此作业具体要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11207
白名单 SPEC
Coding地址:https://e.coding.net/lhbat/baimingdan/baimingdan.git git pull前确保git init初始化仓库。
网页访问:https://lhbat.coding.net/public/baimingdan/baimingdan/git/files
作业0(5分)
//create.cpp #include <iostream> #include <stdlib.h> #include <time.h> using namespace std; int main(int argc, char* argv[]) { int number = atoi(argv[1]);//将命令行参数转数字 srand((unsigned)time(NULL)); for (int i = 0; i < number; i++) { cout << rand(); if(i!=number-1) cout << " "; } cout << endl; return 0; }
read.md文档如下:
| readme.md |
|
作业1(10分)

运行“ -w q < whitelist > output”可以看到,当数据量较少时IO操作占比很大。
作业2(10分)
以biggerwhitelist和biggerq作为输入,对作业1中选择的代码再次进行profile,找到代码执行最“慢”的地方,截图为证并文字说明。
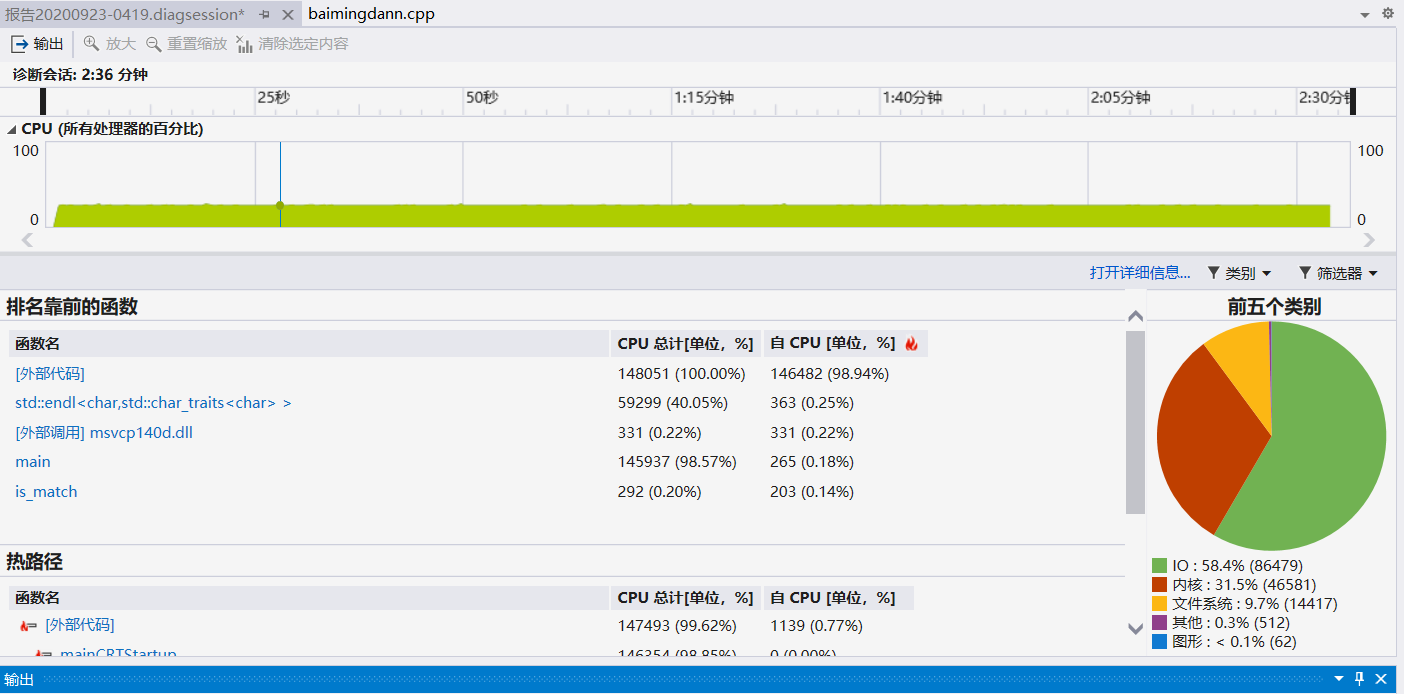

可以看出,当数据量较大时main函数中的is_match函数下面的cout很耗时,很大原因是is_match函数效率不高。
作业3(10分)
根据作业2找到的最慢的地方,优化作业1中你选择的代码,在保证输出结果正确的前提下,减少老杨程序运行的时间。(优化后的代码需要你提交到git上,作为教师的判断依据。优化后的程序的名字应该是better.cpp或者better.cs。)
地址:https://lhbat.coding.net/public/baimingdan/baimingdan/git/files
bool erfen(int t, int low, int high) { int mid; while (low<high) { mid = (high + low) / 2; if (w[mid] == t) { return true;//找到目标数字,成功 } else if (w[mid] > t) { high = mid - 1; } else if (w[mid] < t) { low = mid + 1; } } return false;//查找失败 }
作业4(5分)
对作业3优化后的代码进行profile,结果与作业2的结果做对比。画表格并文字说明。
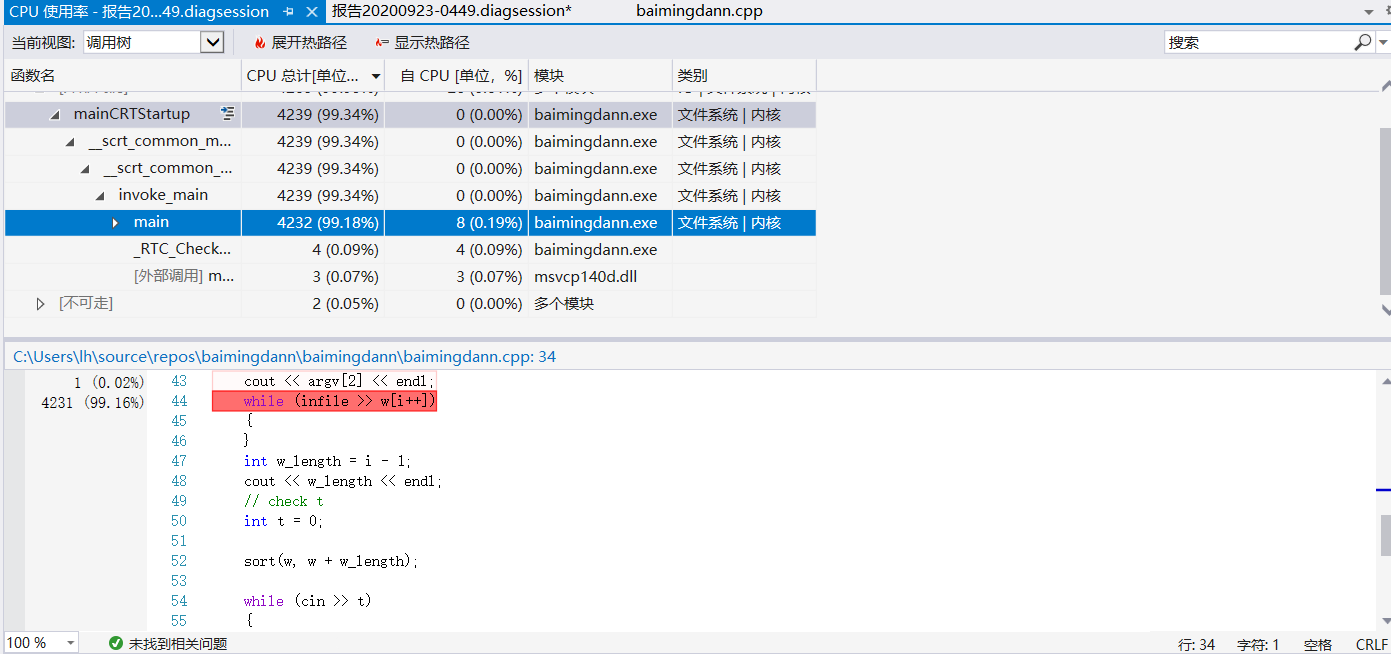
可以看出,经过优化后,当数据量较多时IO操作成为占比较大的部分,这部分事无法避免的。
做业5(5分)
你觉得老杨的文档(readme),注释和代码风格又哪些问题,该如何改进?
我觉得文档的内容略少,小白不容易懂,注释掉的暂时不使用的代码可以删掉,代码中的“t! = w[i]”应该讲不等于作为一个整体。