不要子类化内置类型
内置类型(由C语言编写)不会调用用户定义的类覆盖的特殊方法。
例如,子类化dict作为测验:
class DoppeDict(dict): def __setitem__(self, key, value): super().__setitem__(key, [value]*2) #改为重复存入的值 dd = DoppeDict(one=1) print(dd) dd['two'] = 2 print(dd) dd.update(three=3) print(dd) #结果 {'one': 1} #没有预期效果,即__init__方法忽略了覆盖的__setitem__方法 {'one': 1, 'two': [2, 2]} #[]正确调用 {'one': 1, 'three': 3, 'two': [2, 2]} #update方法忽略了覆盖的__setitem__方法
原生类型这种行为违背了面向对象编程的一个基本原则:始终应该从实例所属的类开始搜索方法,即使在超类实现类的调用也是如此。这种环境中,有个特例,即__miss__方法能按预期工作。
不止实例内部的调用有这个问题,,内置类型的方法调用其他类的方法,如果被覆盖了,也不会被调用。例如:
class AnswerDict(dict): def __getitem__(self, item): #不管传入什么键,始终返回42 return 42 ad = AnswerDict(a='foo') print(ad['a']) d = {} d.update(ad) print(d['a']) print(d) #结果 42 #符号预期 foo #update忽略了覆盖的__getitem__方法 {'a': 'foo'}
因而子类化内置类型(dict,list,str)等容易出错,内置类型的方法通常会忽略用户覆盖的方法。
不要子类化内置类型,用户自定义的类应该继承collections模块中的类,例如Userdict,UserList,UserString,这些类做了特殊设计,因此易于扩展:
import collections class AnswerDict(collections.UserDict): def __getitem__(self, item): #不管传入什么键,始终返回42 return 42 ad = AnswerDict(a='foo') print(ad['a']) d = {} d.update(ad) print(d['a']) print(d) #结果没有问题 42 42 {'a': 42}
多重继承和方法解析顺序
任何实现多继承的语言都要处理潜在的命名冲突,这种冲突由不相关的祖先类实现同名方法引起。这种冲突称为菱形问题:
定义四个类ABCD:
class A: def ping(self): print('A_ping:', self) class B(A): def pong(self): print('B_pong:', self) class C(A): def pong(self): print('C_pong:', self) class D(B, C): def ping(self): super().ping() print('D_ping:', self) def pingpong(self): self.ping() super().ping() self.pong() super().pong() C.pong(self)
实箭头表示继承顺序,虚箭头表示方法解析顺序,如图所示:
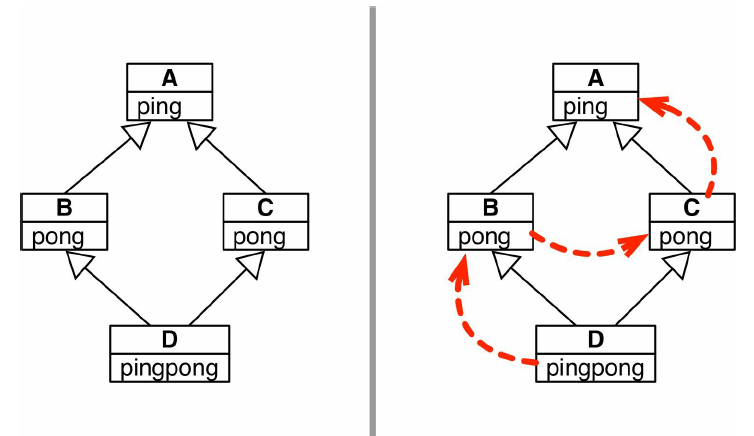
在D实例上调用pong方法:
if __name__ == '__main__': d = D() print(d.pong()) print(C.pong(d)) #结果 B_pong: <__main__.D object at 0x0000026F4D9F5898> C_pong: <__main__.D object at 0x0000026F4D9F5898>
按照解析顺序,,直接调用d.pong()运行的是B类中的版本;
超类中的方法都可以调用,只要把实例作为显式参数传入,如上面的C.pong(d)
python能区分d.pong()调用的是哪个方法,是因为python会按照特定的顺序便利继承图。这个方法叫做方法解析顺序(本例中的解析顺序如虚箭头所示)。类都有一个名为__mro__的属性,它的值是一个元组,按照方法解析顺序列出各个超类,从当前类一直往上,直到object。D类的__mro__:
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
D->B->C->A->object
若想把方法调用委托给超类,推荐的方式是使用内置的super()函数。然而有时需要绕过方法解析顺序,直接调用某个超类的方法,例如D.ping方法这样写:
def ping(self): A.ping(self) print('D_ping:', self)
这样就调用了A的ping()方法绕过了B。
但仍然推荐使用super(),它更安全也不易过时。super()方法调用时,会遵守方法解析顺序:
if __name__ == '__main__': d = D() print(d.ping()) #结果,两次调用 #1调用super().ping(),super()函数把ping调用委托给A类(B,C没有ping方法) #2调用print('D_ping',self) A_ping: <__main__.D object at 0x000001E1447358D0> D_ping: <__main__.D object at 0x000001E1447358D0>
pingpong方法的5个调用:
if __name__ == '__main__': d = D() print(d.pingpong()) #结果 #1调用self.ping #2调用self.ping内部的super.ping #3调用super().ping #4调用self.pong(),根据__mro__,找到B的pong #5调用super().pong(),根据__mro__,找到B的pong #6调用C.pong(self),忽略__mro__,调用C类的pong A_ping: <__main__.D object at 0x00000204691F6898> D_ping: <__main__.D object at 0x00000204691F6898> A_ping: <__main__.D object at 0x00000204691F6898> B_pong: <__main__.D object at 0x00000204691F6898> B_pong: <__main__.D object at 0x00000204691F6898> C_pong: <__main__.D object at 0x00000204691F6898>
方法解析顺序不仅考虑继承图,还考虑子类声明中列出的超类的顺序。如果把D类声明为class D(C, B):, 那么__mro__中就是:D->C->B->A->object
分析类时查看__mro__属性可以看到方法解析顺序:
bool.__mro__ (<class 'bool'>, <class 'int'>, <class 'object'>) import numbers numbers.Integral.__mro__ (<class 'numbers.Integral'>, <class 'numbers.Rational'>, <class 'numbers.Real'>, <class 'numbers.Complex'>, <class 'numbers.Number'>, <class 'object'>) #Base结尾命名的是抽象基类 import io io.TextIOWrapper.__mro__ (<class '_io.TextIOWrapper'>, <class '_io._TextIOBase'>, <class '_io._IOBase'>, <class 'object'>)
处理多重继承
一些建议:
1.把接口继承和实现继承区分开
使用多重继承时,一定要明确一开始为什么要创建子类。主要原因可能有:
1)实现接口,创建子类型,实现"是什么"关系
2)继承实现,通过重用避免代码重复
这两条可能同时出现,不过只要可能,一定要明确意图。通过继承重用代码是实现细节,通常可以换用组合和委托模式。而接口继承则是框架的支柱。
2.使用抽象基类显式表示接口
如果类作用是定义接口,应该明确把它定义为抽象基类,创建abc.ABC或其他抽象基类的子类。
3.通过混入重用代码
如果一个类作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现"是什么"关系,应该明确把那个类定义为混入类。混入类不能实例化,具体类不能只继承混入类。混入类应该提供某方面特定行为,只实现少量关系非常紧密的方法。
4.在名称中明确指明混入
在名称中加入Mixin后缀。
5.抽象基类可以作为混入,反过来则不成立
抽象基类可以实现具体方法,因此也可以作为混入使用。不过,抽象基类会定义类型,而混入做不到。此外,抽象基类可以作为其他类的唯一基类,而混入类不行。
抽象基类有个局限而混入类没有:抽象基类中实现的具体方法只能与抽象基类以及其超类中的方法协作。
6.不要子类化多个具体类
具体类可以没有或者最多只有一个具体超类。也就是说,具体类的超类中除了这一个具体超类之外,其余都是抽象基类或者混入。例如,下列代码中,如果Alpha是具体类,那么Beta和Gamma必须是抽象基类或者混入:
class MyConcreteclass(Alpha, Beta, Gamma): #更多代码...
7.为用户提供聚合类
类的结构主要继承自混入,自身没有添加结构或者行为,那么这样的类称为聚合类。
8.优先使用对象组合而不是继承
组合和委托能够代替混入,把行为提供给不同的类,但是不能取代接口继承去定义类型层次结构。
以上来自《流畅的python》