一、开始写代码前的规划:
1、尝试用C#来写,之前没有学过C#,对于C++也不熟,所以打算先花1天的时间学习C#
2、整个程序基本分为文件遍历、单词提取、单词匹配、排序、输出几个模块,各个模块大致时间如下:
- 文件遍历,这个应该就是个递归,应该不会太花时间,加上查阅资料,预计最多半个小时
- 单词提取,用正则表达式应该挺简单的,5分钟
- 单词匹配,这个对我来说才是最难的,怎么样保证两个模式下的匹配正确,而且匹配的时候不区分大小写,输出要分大小写,还要同时记录出现次数……先给3个小时
- 排序,自己写个快排和插入,20分钟吧
- 输出,到了这儿就全部结束了,一个循环输出就全部结束了,这个时间就忽略了
3、调试以及优化,这个比较难预计,估计半天到一天吧。
其实除了这些时间,对于我这种反应比较慢的人,最开始还要想想程序的逻辑结构,简单写下整体的算法,这个预计要花半个小时。
总共预计:两天半
二、实际用时:
- 学习C#:总的加起来大概用了1天。
- 程序逻辑结构设计20分钟左右。
- 文件遍历,这个我看的书上有现成代码,我只改了很小部分,用了20分钟左右。
- 单词提取:正则表达式不熟练,导致写出来的匹配老有问题,花了我一个小时……
- 单词匹配:用C#中的Dictionary,轻松了不少,但是Dictionary不可修改,而且要是要直接找key的话只能遍历所有的keys,这个比较纠结,最后大概用2个小时。
- 排序:本来想捡便宜,用C#中的ArrayList sort(),但是用了发现并不是按ascii排序,自己写快排,30分钟。
- 调试以及优化,前面编的没什么问题,调试的时候遇到的问题也比较轻松的解决了,代码优化花了比较多的时间,而且有时候用自己想的方法优化发现比不优化前还差,总共用大概2个小时吧。
总共用时:30小时。
三、性能优化
从一开始写代码,我尽量用自己想到的效率最快的方法完成。第一次写完后根据性能分析报告再找优化方法花了我两个小时左右的时间。
测试数据(大概11MB的文本文件,除了1个文件是我自己为了测试结果的正确性编的数据,其他的全都是.txt的英语小说):

1、优化前性能分析结果:


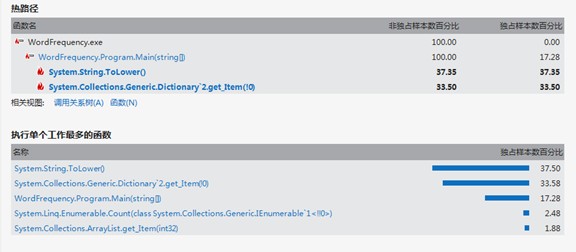
从分析报告看,String.ToLower()和Dictionary的key值判断对性能影响较大,所以我就自己写了一个将大写转换成小写的函数lower(),而仔细看代码,很多地方是可以不用进行大小写转换的,最后尽量减少大小写的转换。
另外一个就是Dctionary的优化,很多同学都说hash表很快,而C#中正好用hashTable,但是后来我查阅了些资料,还是坚持用Dictionary,理由如下:
- 在不指定Capacity的时候数据量较少时,hashtable的插入性能确实比dictionary高,但在其他情况下,dictionary的性能基本都高于hashtable。
- Dic是类型安全的,这有助于我们写出更健壮更具可读性的代码,而且省却我们强制转化的麻烦。
- Dic是泛行的,当K或V是值类型时,其速度远远超过Hashtable。(我其中的v就是)
- 如果K和V都是引用类型,如eaglet所测,Hashtable比Dic更快(参看文章http://www.cnblogs.com/lucifer1982/archive/2008/06/18/1224319.html)
除了这两个我就没想到还能从哪能比较好的优化代码了,后来添添补补对代码循环内的一些定义和变量进行了更改,但是影响好像不大。
2、优化后的分析报告:

四、测试用例:
- 空文件夹
- 空文本文件
- 在simple模式下测试分词结果,文本文件包含不符合单词规则的字符串(1)
- 在simple模式下测试分词结果,文本文件包含不符合单词规则的字符串(2)
- 在simple模式下测试词频统计,文本文件包含多个相同单词(完全相同和仅大小写有区别)
- 在simple模式下测试词频统计,文本文件包含多个相同单词(完全相同和仅大小写有区别)
- 在extend模式下测试仅单词最末数字不同的情况
- 在extend模式下完整测试文件中有特殊符号、单词大小写不同、单词末尾数字不同等特殊情况
- 在simple模式下对大文件进行性能测试
- 在extend模式下对大文件进行性能测试
五、学习与收获
其实程序写完后发现,并不是很难,之前觉得比较困难,主要还是自己对C#不熟悉,这是我写的第一个C#程序,总的来说对C#有了一个基本的了解,包括基本语法、文件处理、字符串处理、键值对、哈希表、以及正则表达式。
简单记录下现在我还有较深印象的3点,都是些看起来不起眼的问题,但是是我遇到的最大障碍,这些东西以后应该还用得着:
1、C#中Dictionary是不能更改的,但可以删了重新添加,如果一定要进行更新,可以再设一个Dictinary进行同步更新。
2、正则表达式中,零宽度正回顾后发断言(?<=exp),断言自身出现的位置的前面能匹配表达式exp。但是像这次的程序中如果仅仅这样考虑是不行的,如果直接用
(?<=[^A-Za-z0-9])[A-Za-z]{4}[A-Za-z0-9]*
进行单词匹配,会导致每行的第一个单词不能匹配,因为它前面没有其他字符了!一个解决办法是每次在读取一行后在行首添加个空格(insert不会改变原来的字符串的,需要设一个临时变量!)
3、C#中可以用TrimEnd去掉字符串末尾指定的字符(串),如去掉s后的1234
char[] inte = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' }; string s = "abcd1234"; string result = s.TrimEnd(inte);