一、概念
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
关键词:
1. 线性表(Linear List),线性表就是数据排成像一条线一样的结构。
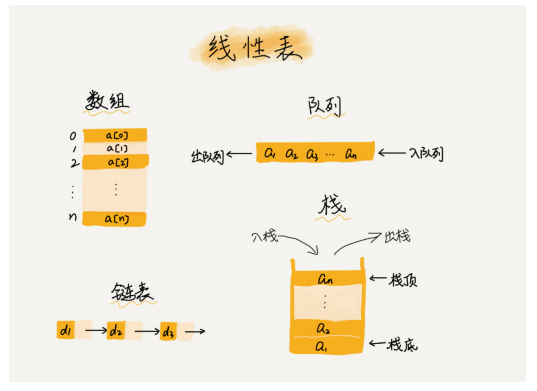
相对的是,非线性表
2. 连续的内存空间和相同类型的数据。
有这两个限制,有一个特性:“随机访问”。通过内存空间地址来获取数组元素。
二、警惕数组的访问越界问题
以C语言为例,只要不是访问受限的内存,所有的内存空间都是可以自由访问的。
以Java、C#为例,数组越界时会抛出异常。
三、容器能否完全替换数组
以Java的ArrayLisit为例(同比C#的List),最大的优势是可以将很多数组操作的细节封装起来,并且支持动态扩容。
注意:动态扩容涉及内存申请和数据搬移,如果事先能确定需要存储的灵气大小,最好在创建时就指定数据大小。
相比于容器,数组是否无用武之地?
1. Java的ArrayList无法存储基本类型,会涉及到Autoboxing、Unboxing,对性能有一定的消耗,如果关注性能,选择数组。
2. 如果数据大小已知,并且对数据的操作非常简单,可直接使用数组。
3. 表示多维数组时,用数组往往会更加直观。
但对于业务开发,直接使用容器就足够了,省时省力。
课后思考:
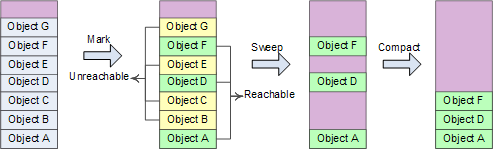
1. 前面我基于数组的原理引出JVM的标记清除垃圾回收算法的核心理念。我不知道你是否使
用Java语言,理解JVM,如果你熟悉,可以在评论区回顾下你理解的标记清除垃圾回收算法。
使用的是C#,一样有GC。
有两个阶段:
阶段1:Mark-Sweep标记清除阶段
阶段2:Compact压缩阶段
参考资料:https://kb.cnblogs.com/page/106720/
2. 前面我们讲到一维数组的内存寻址公式,那你可以思考一下,类比一下,二维数组的内存寻址公式是怎样的呢?
a[i][j]_address = base_address + (i * col_count + j) * data_type_size