通过python 爬取网址url 自动提交百度

昨天同事说,可以手动提交百度这样索引量会上去。
然后想了下。是不是应该弄一个py 然后自动提交呢?想了下。还是弄一个把
python 代码如下:
import os import re import shutil REJECT_FILETYPE = 'rar,7z,css,js,jpg,jpeg,gif,bmp,png,swf,exe' #定义爬虫过程中不下载的文件类型 def getinfo(webaddress): #'#通过用户输入的网址连接上网络协议,得到URL我这里是我自己的域名 global REJECT_FILETYPE url = 'http://'+webaddress+'/' #网址的url地址 print 'Getting>>>>> '+url websitefilepath = os.path.abspath('.')+'/'+webaddress #通过函数os.path.abspath得到当前程序所在的绝对路径,然后搭配用户所输入的网址得到用于存储下载网页的文件夹 if os.path.exists(websitefilepath): #如果此文件夹已经存在就将其删除,原因是如果它存在,那么爬虫将不成功 shutil.rmtree(websitefilepath) #shutil.rmtree函数用于删除文件夹(其中含有文件) outputfilepath = os.path.abspath('.')+'/'+'output.txt' #在当前文件夹下创建一个过渡性质的文件output.txt fobj = open(outputfilepath,'w+') command = 'wget -r -m -nv --reject='+REJECT_FILETYPE+' -o '+outputfilepath+' '+url #利用wget命令爬取网站 tmp0 = os.popen(command).readlines() #函数os.popen执行命令并且将运行结果存储在变量tmp0中 print >> fobj,tmp0 #写入output.txt中 allinfo = fobj.read() target_url = re.compile(r'".*?"',re.DOTALL).findall(allinfo) #通过正则表达式筛选出得到的网址 print target_url target_num = len(target_url) fobj1 = open('result.txt','w') #在本目录下创建一个result.txt文件,里面存储最终得到的内容 for i in range(target_num): if len(target_url[i][1:-1])<70: # 这个target_url 是一个字典形式的,如果url 长度大于70 就不会记录到里面 print >> fobj1,target_url[i][1:-1] #写入到文件中 else: print "NO" fobj.close() fobj1.close() if os.path.exists(outputfilepath): #将过渡文件output.txt删除 os.remove(outputfilepath) #删除 if __name__=="__main__": webaddress = raw_input("Input the Website Address(without "http:")>") getinfo(webaddress) print "Well Done."
执行完之后就会有如下url
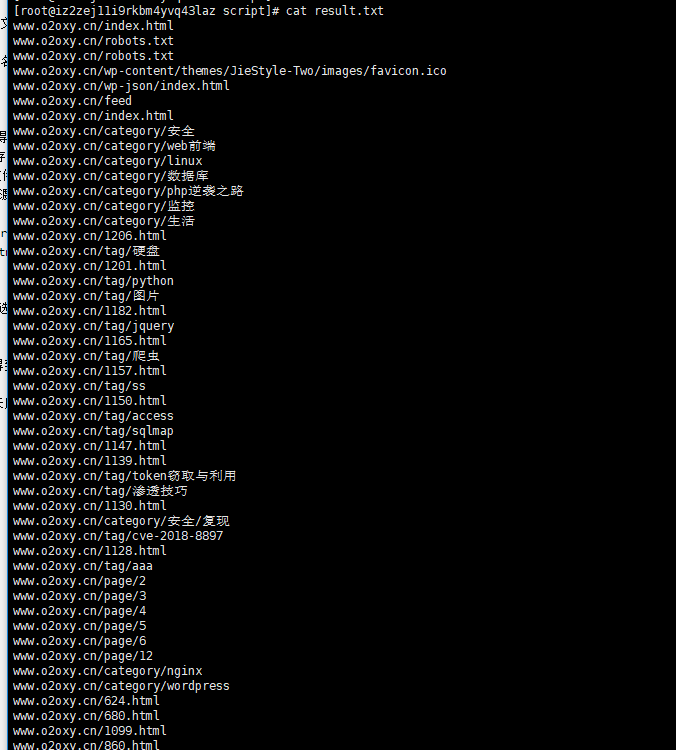
再弄一个主动提交的脚本,我进入百度录入的网址找到自己提交的地址
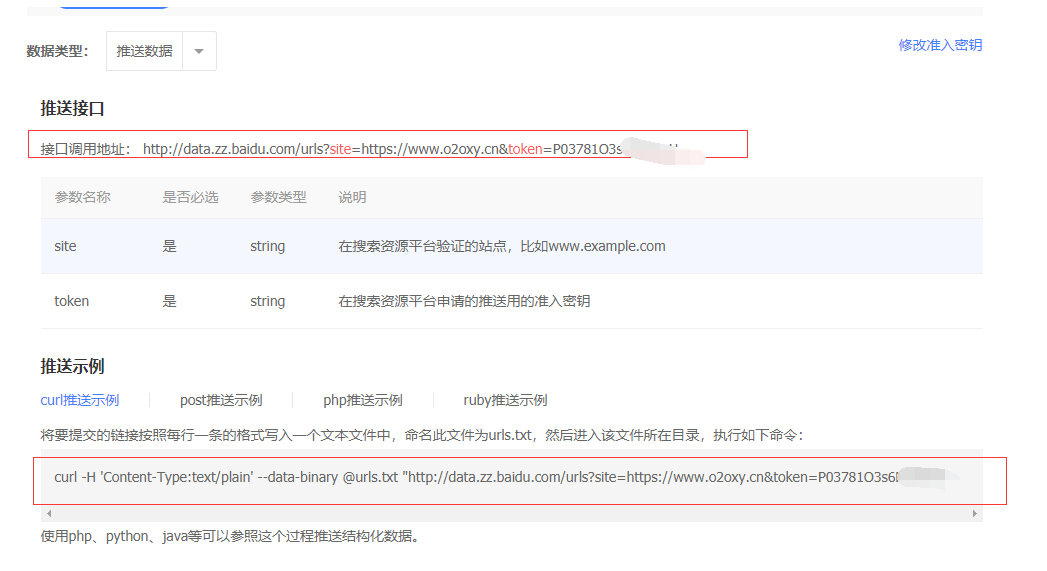
写了一个垃圾脚本,本来想融入到py中。但是想了下,还是别了
[root@iz2zej11i9rkbm4yvq43laz script]# cat baiduurl.sh cd /script && curl -H 'Content-Type:text/plain' --data-binary @result.txt "http://data.zz.baidu.com/urls?site=https://www.o2oxy.cn&token=P03781O3s6Ee" && curl -H 'Content-Type:text/plain' --data-binary @result.txt "http://data.zz.baidu.com/urls?site=https://www.o2oxy.cn&token=P03781O3s6E"
执行结果如下:
[root@iz2zej11i9rkbm4yvq43laz script]# sh baiduurl.sh {"remain":4993750,"success":455}{"remain":4993295,"success":455}
然后做了一个计划任务

执行一下。获取网址url 比较慢,可能十分钟把
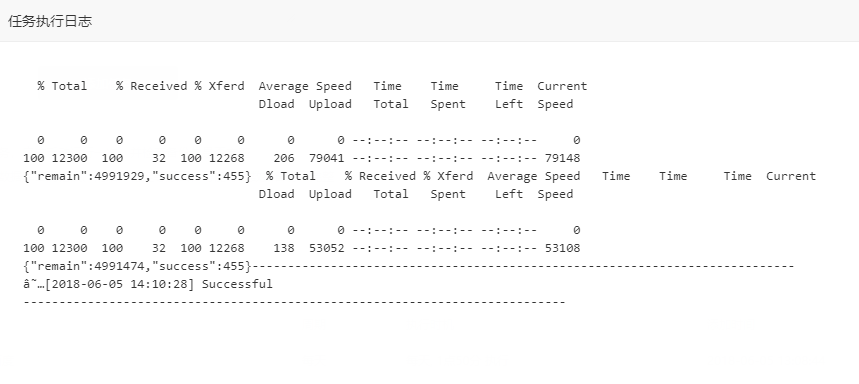
唔。完美!!!!!
