一 自己制作web框架
我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端,基于请求做出响应,客户都先请求,服务端做出对应的响应,按照http协议的请求协议发送请求,服务端按照http协议的响应协议来响应请求,这样的网络通信,我们就可以自己实现Web框架了。
通过对socket的学习,我们知道网络通信,我们完全可以自己写了,因为socket就是做网络通信用的,下面我们就基于socket来自己实现一个web框架,写一个web服务端,让浏览器来请求,并通过自己的服务端把页面返回给浏览器,浏览器渲染出我们想要的效果,废话少说,直接上代码:


import time import socket from threading import Thread server = socket.socket() server.bind(('0.0.0.0',8001))#绑定本机端口 server.listen()#监听 def html(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 # conn.send(b'who are you?') with open('01 index2.html', 'rb') as f:#打开我们想渲染的html页面 data = f.read()#此处是一次性读出来的,也可一行行读一行行发 conn.send(data) conn.close()#一次发送完毕就把这个连接关掉,因为http是无状态无连接的 def css(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 # conn.send(b'who are you?') with open('index.css', 'rb') as f:#此处是因为我们发的html页面中有浏览器渲染时需要的文件,只能向我们请求,我们才能给 data = f.read() conn.send(data) conn.close() def js(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 # conn.send(b'who are you?') with open('index.js', 'rb') as f:#此处是因为我们发的html页面中有浏览器渲染时需要的文件,只能向我们请求,我们才能给 data = f.read() data = f.read() conn.send(data) conn.close() def ico(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 # conn.send(b'who are you?') with open('favicon.ico', 'rb') as f:#此处是因为我们发的html页面中有浏览器渲染时需要的文件,只能向我们请求,我们才能给 data = f.read() data = f.read() conn.send(data) conn.close() def jpg(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 # conn.send(b'who are you?') with open('1.jpg', 'rb') as f:#此处是因为我们发的html页面中有浏览器渲染时需要的文件,只能向我们请求,我们才能给 data = f.read() data = f.read() conn.send(data) conn.close() def home(conn): conn.send(b'HTTP/1.1 200 ok k1:v1 ')#按照http协议,每次发消息之前都先发送一条响应头 current_time = str(time.time()) # conn.send(b'who are you?') with open('home.html', 'r',encoding='utf-8') as f:#此处是因为我们发的html页面中有浏览器渲染时需要的文件,只能向我们请求,我们才能给 data = f.read() data = f.read() data = data.replace('xxoo',current_time)#此处是把另一个html的字符串特定内容(这是我们自己定的协议)替换成我们想在浏览器显示的内容---动态页面的雏形 conn.send(data.encode('utf-8')) conn.close() urlpatterns = [ #利用列表中加成对的元祖,造成映射关系,遍历列表按照索引取值加以判断,再关联其相应函数的操作 ('/',html), ('/index.css',css), ('/index.js',js), ('/favicon.ico',ico), ('/1.jpg',jpg), ('/home.html',home), ] def communication(conn):#此为逻辑关系总控制,通过对请求文件的操作分析,筛选需要的信息 client_msg = conn.recv(1024).decode('utf-8') # print(client_msg) path = client_msg.split(' ')[0].split(' ')[1]#对请求文件操作 #针对不同的请求路径,返回不同的文件 for urlpattern in urlpatterns: print(path) if urlpattern[0] == path: # urlpattern[1](conn) # 多线程执行函数 t = Thread(target=urlpattern[1],args=(conn,)) t.start() while 1: conn, add = server.accept()#一旦有来连接的客户端即接受 t = Thread(target=communication,args=(conn,)) t.start()
我们发现,自己做的建议框架,很多东西都在重复,同时存在很多漏洞与bug,需要再完善优化,总体而言对他的大方向是把握住了,下面看一个wsgiref模块版web框架。
二wsgiref模块版web框架
最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
wsgiref模块其实就是将整个请求信息给封装了起来,就不需要你自己处理了,假如它将所有请求信息封装成了一个叫做request的对象,那么你直接request.path就能获取到用户这次请求的路径,request.method就能获取到本次用户请求的请求方式(get还是post)等,那这个模块用起来,我们再写web框架是不是就简单了好多啊。
对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们专心用Python编写Web业务。
这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
WSGI(Web Server Gateway Interface)就是一种规范,它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器。
好,接下来我们就看一下(能理解就行,了解就可以了):先看看wsfiref怎么使用
from wsgiref.simple_server import make_server # wsgiref本身就是个web框架,提供了一些固定的功能(请求和响应信息的封装,不需要我们自己写原生的socket了也不需要咱们自己来完成请求信息的提取了,提取起来很方便) #函数名字随便起 def application(environ, start_response): ''' :param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息 :param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数 :return: ''' start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')]) print(environ) print(environ['PATH_INFO']) #输入地址127.0.0.1:8000,这个打印的是'/',输入的是127.0.0.1:8000/index,打印结果是'/index' return [b'<h1>Hello, web!</h1>'] #和咱们学的socketserver那个模块很像啊 httpd = make_server('127.0.0.1', 8080, application) print('Serving HTTP on port 8080...') # 开始监听HTTP请求: httpd.serve_forever()
来一个完整的web项目,用户登录认证的项目,我们需要连接数据库了,所以先到mysql数据库里面准备一些表和数据
mysql> create database db1; Query OK, 1 row affected (0.00 sec) mysql> use db1; Database changed mysql> create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null); Query OK, 0 rows affected (0.23 sec) mysql> insert into userinfo(username,password) values('chao','666'),('sb1','222'); Query OK, 2 rows affected (0.03 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from userinfo; +----+----------+----------+ | id | username | password | +----+----------+----------+ | 1 | chao | 666 | | 2 | sb1 | 222 | +----+----------+----------+ 2 rows in set (0.00 sec)
然后再创建这么几个文件:
python文件名称webmodel.py,内容如下:
#创建表,插入数据 def createtable(): import pymysql conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='666', database='db1', charset='utf8' ) cursor = conn.cursor(pymysql.cursors.DictCursor) sql = ''' -- 创建表 create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null); -- 插入数据 insert into userinfo(username,password) values('chao','666'),('sb1','222'); ''' cursor.execute(sql) conn.commit() cursor.close() conn.close()
python的名为webauth文件,内容如下:
#对用户名和密码进行验证 def auth(username,password): import pymysql conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', password='123', database='db1', charset='utf8' ) print('userinfo',username,password) cursor = conn.cursor(pymysql.cursors.DictCursor) sql = 'select * from userinfo where username=%s and password=%s;' res = cursor.execute(sql, [username, password]) if res: return True else: return False
用户输入用户名和密码的文件,名为web.html,内容如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!--如果form表单里面的action什么值也没给,默认是往当前页面的url上提交你的数据,所以我们可以自己指定数据的提交路径--> <!--<form action="http://127.0.0.1:8080/auth/" method="post">--> <form action="http://127.0.0.1:8080/auth/" method="get"> 用户名<input type="text" name="username"> 密码 <input type="password" name="password"> <input type="submit"> </form> <script> </script> </body> </html>
用户验证成功后跳转的页面,显示成功,名为websuccess.html,内容如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> h1{ color:red; } </style> </head> <body> <h1>宝贝儿,恭喜你登陆成功啦</h1> </body> </html>
python服务端代码(主逻辑代码),名为web_python.py:
from urllib.parse import parse_qs from wsgiref.simple_server import make_server import webauth def application(environ, start_response): # start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')]) # start_response('200 OK', [('Content-Type', 'text/html'),('charset','utf-8')]) start_response('200 OK', [('Content-Type', 'text/html')]) print(environ) print(environ['PATH_INFO']) path = environ['PATH_INFO'] #用户获取login页面的请求路径 if path == '/login': with open('web.html','rb') as f: data = f.read() #针对form表单提交的auth路径,进行对应的逻辑处理 elif path == '/auth/': #登陆认证 #1.获取用户输入的用户名和密码 #2.去数据库做数据的校验,查看用户提交的是否合法 # user_information = environ[''] if environ.get("REQUEST_METHOD") == "POST": #获取请求体数据的长度,因为提交过来的数据需要用它来提取,注意POST请求和GET请求的获取数据的方式不同 try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 #POST请求获取数据的方式 request_data = environ['wsgi.input'].read(request_body_size) print('>>>>>',request_data) # >>>>> b'username=chao&password=123',是个bytes类型数据 print('?????',environ['QUERY_STRING']) #????? 空的,因为post请求只能按照上面这种方式取数据 #parse_qs可以帮我们解析数据 re_data = parse_qs(request_data) print('拆解后的数据',re_data) #拆解后的数据 {b'password': [b'123'], b'username': [b'chao']} #post请求的返回数据我就不写啦 pass if environ.get("REQUEST_METHOD") == "GET": #GET请求获取数据的方式,只能按照这种方式取 print('?????',environ['QUERY_STRING']) #????? username=chao&password=123,是个字符串类型数据 request_data = environ['QUERY_STRING'] # parse_qs可以帮我们解析数据 re_data = parse_qs(request_data) print('拆解后的数据', re_data) #拆解后的数据 {'password': ['123'], 'username': ['chao']} username = re_data['username'][0] password = re_data['password'][0] print(username,password) #进行验证: status = webauth.auth(username,password) if status: # 3.将相应内容返回 with open('websuccess.html','rb') as f: data = f.read() else: data = b'auth error' # 但是不管是post还是get请求都不能直接拿到数据,拿到的数据还需要我们来进行分解提取,所以我们引入urllib模块来帮我们分解 #注意昂,我们如果直接返回中文,没有给浏览器指定编码格式,默认是gbk,所以我们需要gbk来编码一下,浏览器才能识别 # data='登陆成功!'.encode('gbk') else: data = b'sorry 404!,not found the page' return [data] #和咱们学的socketserver那个模块很像啊 httpd = make_server('127.0.0.1', 8080, application) print('Serving HTTP on port 8080...') # 开始监听HTTP请求: httpd.serve_forever()
把代码拷走,创建文件,放到同一个目录下,运行一下we_python.py文件的代码就能看到效果,注意先输入的网址是127.0.0.1:8080/login ,还要注意你的mysql数据库没有问题。

二 模板渲染JinJa2
利用字符串replace(产生一个新字符串)的方法(原理),去替换html中的对应内容(专业名词叫做模板渲染,你先渲染一下,再给浏览器进行渲染),然后再发送给浏览器完成渲染。 这个过程就相当于HTML模板渲染数据。 本质上就是HTML内容中利用一些特殊的符号来替换要展示的数据。 我们也可以自己定义特殊符号去替换,其实模板渲染有个现成的工具: jinja2---->先下载:pip install jinja2
来一个html文件,index2,html,内容如下:
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <h1>姓名:{{name}}</h1><!--{{}}这是jinja2定义的特殊符号--> <h1>爱好:</h1> <ul> {% for hobby in hobby_list %}<!--for 循环,格式就是%开头的--> <li>{{hobby}}</li> {% endfor %}<!--for 循环,结束格式就是% endfor %--> </ul> </body> </html>
使用jinja2渲染index2.html文件,创建一个python文件,代码如下:
from wsgiref.simple_server import make_server from jinja2 import Template def index(): with open("index2.html", "r",encoding='utf-8') as f: data = f.read() template = Template(data) # 生成模板文件Template是一个类,生成一个template对象 ret = template.render({"name": "于谦", "hobby_list": ["烫头", "泡吧"]}) # 把数据填充到模板里面 return [bytes(ret, encoding="utf8"), ]#[]中括号也是规定的 # 定义一个url和函数的对应关系 URL_LIST = [ ("/index/", index), ] def run_server(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息 url = environ['PATH_INFO'] # 取到用户输入的url func = None # 将要执行的函数 for i in URL_LIST: if i[0] == url: func = i[1] # 去之前定义好的url列表里找url应该执行的函数 break if func: # 如果能找到要执行的函数 return func() # 返回函数的执行结果 else: return [bytes("404没有该页面", encoding="utf8"), ] if __name__ == '__main__': httpd = make_server('', 8000, run_server) print("Serving HTTP on port 8000...") httpd.serve_forever()
现在的数据是我们自己手写的,那可不可以从数据库中查询数据,来填充页面呢?
使用pymysql连接数据库:
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="xxx", db="xxx", charset="utf8") cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) cursor.execute("select name, age, department_id from userinfo") user_list = cursor.fetchall() cursor.close() conn.close()
创建一个测试的user表:
CREATE TABLE user( id int auto_increment PRIMARY KEY, name CHAR(10) NOT NULL, hobby CHAR(20) NOT NULL )engine=innodb DEFAULT charset=UTF8;
模板的原理就是字符串替换,我们只要在HTML页面中遵循jinja2的语法规则写上,其内部就会按照指定的语法进行相应的替换,从而达到动态的返回内容。
三 MVC和MTV框架
MVC
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
- M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
- T 代表模板 (Template):负责如何把页面展示给用户(html)。
- V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示: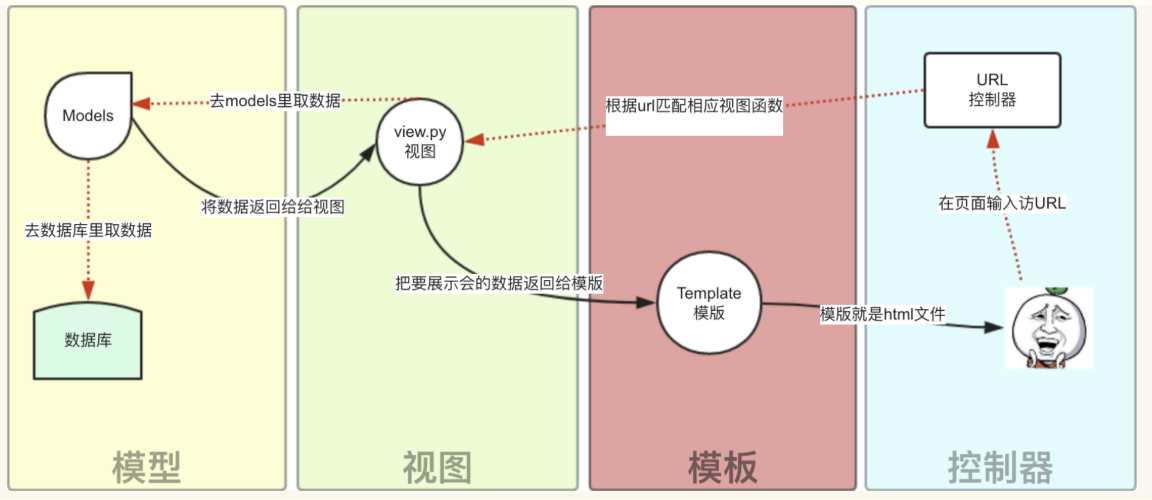
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。