is和==的区别
1、id() - 我们通过id()可以查看一个变量表示的值在内存中的地址
is 比较的是内存地址 ==比较的是值
s = 'abc_' s2 = 'abc_' print(id(s),id(s2)) # 4327204768 4327204768 print(s is s2) #True print(s == s2) #True
对于int和str中的部分,两个变量如果值相同,指向也是相同的,原理如下:
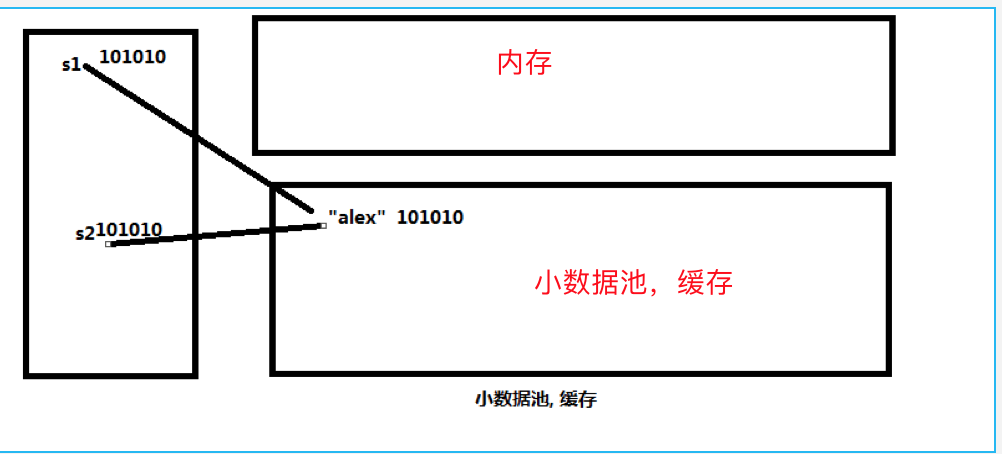
小数据池(常量池):把我们使用过的值存储在小数据池中,供其他的变量使用
小数据池给数字和字符串使用,其他类型不存在。
对于数字:
-5~256是会被加到小数据池中的,每次使用的都是同一个对象。
对于字符串:
1、如果是纯文字信息和下划线,那么这个对象会被添加到小数据池
2、如果是带有特殊字符的,那么不会被添加到小数据池,每次都是新的
3、如果是单一字母*n的情况,在20个单位内是可以的,超过20个单位就不会添加到小数据池中。
注意(一般情况下):
在py文件中,如果你只是单纯的定义一个字符串,那么一般情况下都是会被追加到小数据池中的。
我们可以这样认为,在使用字符串的时候,Python会帮我们把字符串进行缓存,在下次使用的时候直接指向这个字符串即可,可以节省很多内存。
二、编码
Python3中:内存中使用的是Unicode
1、ASCII:最早的编码,里面有英文大写字母、小写字母、数字、一些特殊字符,没有中文 8bit 1byte
2、GBK:中文国标码,里面包含了ASCII编码和中文常用编码。 16bit 2byte
3、Unicode:万国码,里面包含了全世界所有国家文字的编码 32bit 4byte
4、UTF-8:长度可以变的万国码,是Unicode的一种实现,最小字符占8位
1、英文:8bit 1byte
2、欧洲文字:16bit 2byte
3、中文:24bit 3byte
在Python3的内存中,在程序运行阶段,使用的是Unicode编码,因为Unicode是万国码,什么内容都可以进行显示,那么在数据传输和存储的时候由于Unicode比较浪费空间和资源,需要把Unicode转存成utf-8或者GBK进行存储。
在Python中可以把文字信息进行编码,编码之后的内容就可以进行传输了,编码之后的数据是byte类型的数据,还是原来的数据,只是通过编码之后表现形式发生了改变而已。
s = '新'
print(s.encode('GBK')) # b'xd0xc2'
print(s.encode('utf-8')) # b'xe6x96xb0'
s1='a'
print(s1.encode('GBK')) # b'a'
print(s1.encode("utf-8"))# b'a'
英文编码之后的结果和源字符串一致。
中文编码之后的结果根据编码的不同,编码结果也不同。
一个中文的UFT-8编码是3个字节,一个GBK的中文编码是2个字节。