##内容回顾
#1、网络传输的两个阶段 1、wait_data 耗时最长 2、copy_data 是一个本地IO操作 速度非常快 recv 先wait 在copy send直接copy系统缓存 就结束 #2、阻塞IO模型 当执行recv/zccept 时 程序阻塞在原地 知道数据到达为止 默认情况下就是IO模型,效率低 #2-1、解决方案:线程池/进程池 线程可以解决一定范围的并发量,但是如果客户端并发量超过了机器能开启的最大线程数,后续的客户端将无法被处理,最主要的问题,如果有大量线程出处于阻塞状态浪费了CPU资源 #2-2、协程: 用一个线程处理所有socket的任务,当一个socket处于阻塞时自动切换至另一个任务来执行 原理是把原来阻塞的网络io操作变成了非阻塞 #3、非阻塞IO模型 非阻塞IO十八wait_data阶段的阻塞变成了非阻塞,也就是recv,accept 把server.setblockong(False) #3-1、带来的问题:执行recv/accept可能数据还没准备好,系统会抛出异常,我们可以切换到其他任务来执行,如果要即使处理客户端发来的数据 必须不间断的询问系统 是否有数据可以处理 如果每次询问没有时间间隔将会大量占用cpu资源 优点:没有开启县城带来的资源消耗,只要性能跟得上 来多少客户端都行 #4、多路复用IO模型 多个socket共用一个线程来处理 select 把需要检测的socket交给select,select会从这些socket中诈骗出可读或是可写的socket,我们只需遍历返回的socket列表来处理即可 优点:避免了CPU占用过高的问题,弱国没有客户端需要处理,会阻塞在原地 缺点:同时只能处理1024个socket epoll就可以解决1024的最大限制
多线程会遇到资源瓶颈,什么才是解决高并发最有效的方式呢
所以epoll仅在linux中可用
##epoll
参考博客地址:https://mp.weixin.qq.com/s?__biz=MjM5NzM0MjcyMQ==&mid=2650088782&idx=1&sn=04d0d6f63bd2cfd8c8b37aeaa373bc4b&chksm=bedafe2089ad7736f12aa6cc88f631ee9060c227965eb65e6547b9f961906332d46bf8db9b46&mpshare=1&scene=1&srcid=0604HfDMhPqzL4fAf4wZX2jx #从事服务端开发,少不了要接触网络编程。epoll 作为 Linux 下高性能网络服务器的必备技术至关重要,nginx、Redis、Skynet 和大部分游戏服务器都使用到这一多路复用技术。 ##1、 程序阻塞过程分析 假设系统目前运行了三个进程 A B C 进程A正在运行一下socket程序 server = socket.socket() server.bind(("127.0.0.1",1688)) server.listen() server.accept() 1.系统会创建文件描述符指向一个socket对象 ,其包含了读写缓冲区,已经进行等待队列 2.当执行到accept / recv 时系统会讲进程A 从工作队列中移除 3.将进程A的引用添加到 socket对象的等待队列中
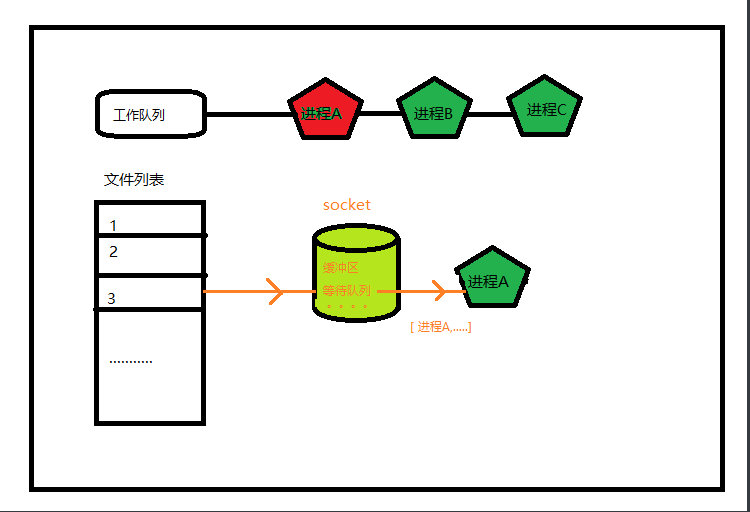
##2、 进程的唤醒 1.当网卡收到数据后会现将数据写入到缓冲区 2.发送中断信号给CPU 3.CPU执行中断程序,将数据从内核copy到socket的缓冲区 4.唤醒进程,即将进程A切换到就绪态,同时从socket的等待队列中移除这个进程引用

##3、 select监控多个socket select的实现思路比较直接 1.先将所有socket放到一个列表中,
rlist=[socket1,socket2.....] 2.遍历这个列表将进程A 添加到每个socket的等待队列中 然后阻塞进程
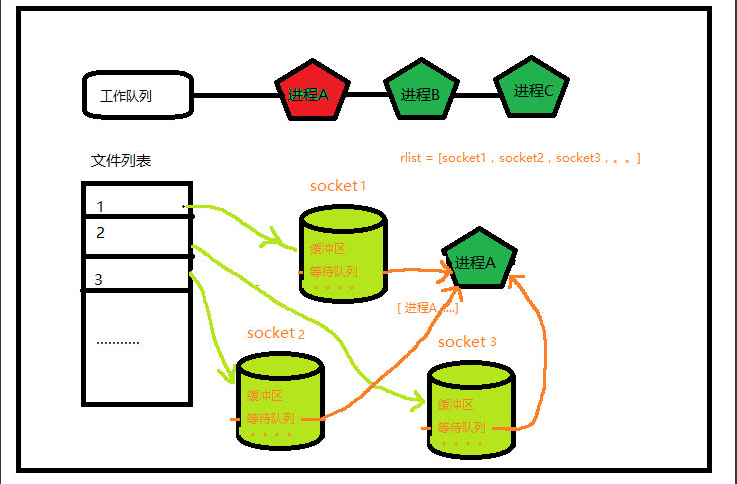
3.当数据到达时,cpu执行中断程序将数据copy给socket 同时唤醒处于等待队列中的进程A
为了防止重复添加等待队列 还需要移除已经存在的进程A
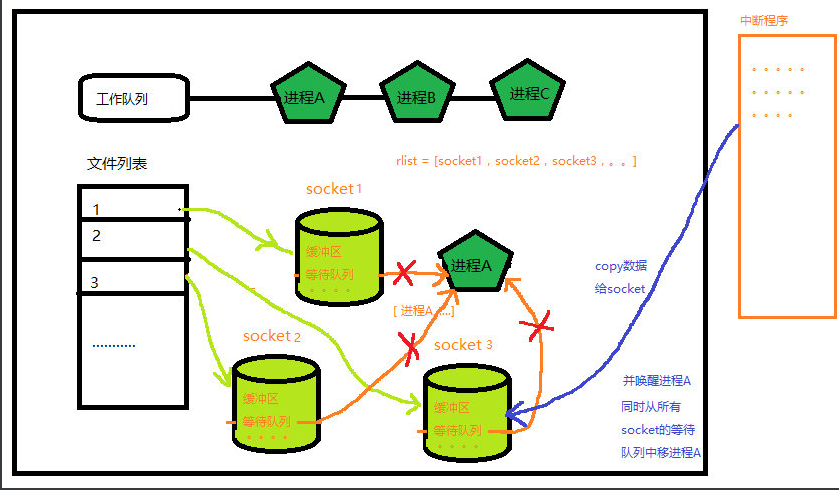
4.进程A唤醒后 由于不清楚那个socket有数据,所以需要遍历一遍所有socket列表 ##4、从上面的过程中不难看出 1.select,需要遍历socket列表,频繁的对等待队列进行添加移除操作, 2.数据到达后还需要给遍历所有socket才能获知哪些socket有数据 两个操作消耗的时间随着要监控的socket的数量增加而大大增加, 处于效率考虑才规定了最大只能监视1024个socket ##5、 epol l要解决的问题 1.避免频繁的对等待队列进行操作 2.避免遍历所有socket ##5-1对于第一个问题我们先看select的处理方式 while True: r_list,w_list,x_list = select.select(rlist,wlist,xlist) 每次处理完一次读写后,都需要将所用过冲重复一遍,包括移除进程,添加进程,默认就会将进程添加到等待队列,并阻塞住进程,然而等待队列的更新操作并不频繁, 所以对于第一个问题epoll,采取的方案是,将对等待队列的维护和,阻塞进程这两个操作进行拆分,相关代码如下 “”“ import socket,select server = socket.socket() server.bind(("127.0.0.1",1688)) server.listen(5) #创建epoll事件对象,后续要监控的事件添加到其中 epoll = select.epoll() #注册服务器监听fd到等待读事件集合 epoll.register(server.fileno(), select.EPOLLIN) # 需要关注 server这个socket的可读事件 # 等待事件发生 while True: for sock,event in epoll.poll(): pass ”“” 在epoll中register 与 unregister函数用于维护等待队列 register 是进程添加到等待队列中 unregister 把进程从等待队列中删除 使用这两个函数我们自己来控制等待队列的添加和删除 从而避免频繁操作等待队列 epoll.poll则用于阻塞进程

这样一来就避免了 每次处理都需要重新操作等待队列的问题 ##5-2 第二个问题是select中进程无法获知哪些socket是有数据的所以需要遍历 epol为了解决这个问题,在内核中维护了一个就绪列表, 1.创建epoll对象,epoll也会对应一个文件,由文件系统管理 2.执行register时,将epoll对象 添加到socket的等待队列中
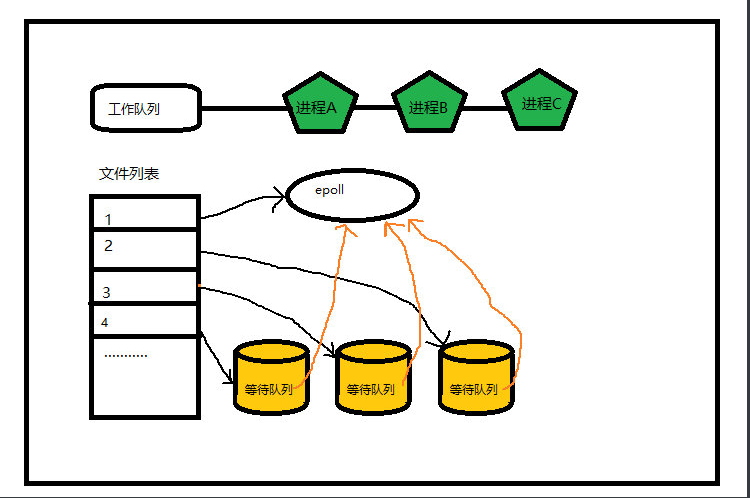
3.数据到达后,CPU执行中断程序,将数据copy给socket 4.在epoll中,中断程序接下来会执行epoll对象中的回调函数,传入就绪的socket对象 5.将socket,添加到就绪列表中 6.唤醒epoll等待队列中的进程, 进程唤醒后,由于存在就绪列表,所以不需要再遍历socket了,直接处理就绪列表即可 解决了这两个问题后,并发量得到大幅度提升,最大可同时维护上万级别的socket
##epoll相关函数
import select 导入select模块 epoll = select.epoll() 创建一个epoll对象 epoll.register(文件句柄,事件类型) 注册要监控的文件句柄和事件 事件类型: select.EPOLLIN 可读事件 select.EPOLLOUT 可写事件 select.EPOLLERR 错误事件 select.EPOLLHUP 客户端断开事件 epoll.unregister(文件句柄) 销毁文件句柄 epoll.poll(timeout) 当文件句柄发生变化,则会以列表的形式主动报告给用户进程,timeout 为超时时间,默认为-1,即一直等待直到文件句柄发生变化,如果指定为1 那么epoll每1秒汇报一次当前文件句柄的变化情况,如果无变化则返回空 epoll.fileno() 返回epoll的控制文件描述符(Return the epoll control file descriptor) epoll.modfiy(fineno,event) fineno为文件描述符 event为事件类型 作用是修改文件描述符所对应的事件 epoll.fromfd(fileno) 从1个指定的文件描述符创建1个epoll对象 epoll.close() 关闭epoll对象的控制文件描述符
##epoll案例
#在Linux中执行 -----------------------------服务器----------------------------------------------------------
#coding:utf-8
import select,socket
import select,socket
server = socket.socket()
server.bind(("127.0.0.1",1688))
server.listen(5) # 在linux中没有默认值 必须填
server.bind(("127.0.0.1",1688))
server.listen(5) # 在linux中没有默认值 必须填
# 创建epoll对象
epoll = select.epoll()
epoll = select.epoll()
# 注册需要关心的事件 本质就是将进程 添加到epoll的等待队列中
# fileno() 可以获取socket对应的文件描述符 (文件描述符就是存储了一堆该文件信息的数据结构)
epoll.register(server.fileno(),select.EPOLLIN)
# 对于服务器socke而言只需要关心可读事件即可
# fileno() 可以获取socket对应的文件描述符 (文件描述符就是存储了一堆该文件信息的数据结构)
epoll.register(server.fileno(),select.EPOLLIN)
# 对于服务器socke而言只需要关心可读事件即可
# 定义一个字典存储 文件描述符 和socket的对应关系
socket_fd = {server.fileno():server}
#保存需要的数据和对应关系
msgs = []
#epoll.poll()
# 该函数是一个阻塞函数 会阻塞直到你关注的事件发生了 可读/可写
# 其返回值是一个列表 列表中是元组 元组第一个是文件描述符(scoket),第二个是发生的事件类型
while True:
# 遍历就绪列表
for fd,event in epoll.poll():
# 通过文件描述找到对应的socket对象
sock = socket_fd[fd]
if sock == server: # 如果是服务器 那就接受请求
client,addr = sock.accept()
# 将新产生的socket也交给epoll来管理
epoll.register(client.fileno(),select.EPOLLIN) # 关注可读事件
# 保存 client与fd的对应关系
socket_fd[client.fileno()] = client
# 遍历就绪列表
for fd,event in epoll.poll():
# 通过文件描述找到对应的socket对象
sock = socket_fd[fd]
if sock == server: # 如果是服务器 那就接受请求
client,addr = sock.accept()
# 将新产生的socket也交给epoll来管理
epoll.register(client.fileno(),select.EPOLLIN) # 关注可读事件
# 保存 client与fd的对应关系
socket_fd[client.fileno()] = client
elif event == select.EPOLLIN: # 如果是客户端的可读事件
data = sock.recv(2048)
if not data:
epoll.unregister(sock.fileno()) # 注销事件
del socket_fd[sock.fileno()] # 删除字典中的对应关系
sock.close() # 关闭socket
continue
data = sock.recv(2048)
if not data:
epoll.unregister(sock.fileno()) # 注销事件
del socket_fd[sock.fileno()] # 删除字典中的对应关系
sock.close() # 关闭socket
continue
print("somebody say %s" % data)
# sock.send(data.upper())
# 注册客户端的 可写事件
epoll.modify(sock.fileno(),select.EPOLLOUT)
msgs.append((sock,data))
# sock.send(data.upper())
# 注册客户端的 可写事件
epoll.modify(sock.fileno(),select.EPOLLOUT)
msgs.append((sock,data))
elif event == select.EPOLLOUT: # 客户端的可写事件
for item in msgs[:]:
if item[0] == sock:
sock.send(item[1].upper())
msgs.remove(item) #删除发送成功的数据
for item in msgs[:]:
if item[0] == sock:
sock.send(item[1].upper())
msgs.remove(item) #删除发送成功的数据
epoll.modify(sock.fileno(),select.EPOLLIN)
-----------------------------客户端----------------------------------------------------------
#coding:utf-8
import socket
import socket
c = socket.socket()
c.connect(("127.0.0.1",1688))
c.connect(("127.0.0.1",1688))
while True:
msg = raw_input(":").strip()
if msg == "q":break
if not msg:continue
msg = raw_input(":").strip()
if msg == "q":break
if not msg:continue
c.send(msg.encode("utf-8"))
data = c.recv(2048).decode("utf-8")
print(data)
data = c.recv(2048).decode("utf-8")
print(data)
#关闭客户端socket
clientsocket.close()
##MySQL数据库
# 一.认识数据库 ## 1.什么是数据库? 数据库就是存储数据的仓库 #### 存储数据的方式1 """ 第一天就学习了一种存储数据的方式 就是变量 然而变量的存储介质是内存,内存中的数据在断电后就消失了,无法永久保存 很明显这是不行的 ,比如用户刚刚注册成功的用户名密码必须要永久。 """ #### 存储数据的方式2 """ 使用文件来存储数据就可以实现永久存储,但是文件是存储于硬盘上的,首先要考虑的就是效率问题一个应用程序之所以效率低就是因为IO操作太多。 另外还需要考虑一个问题: 不可能所有组件运行在同一台计算机上为什么? 一台计算机的性能总归有上限 例如淘宝双11 双12 用一台计算机来做服务器的 配置再高都肯定吃不消,那怎么办? """ #### 计算机的性能进行扩展 """ 1.垂直扩展 不断的提升硬件性能 不可取 2.横向扩展 (分布式计算) 添加更多的计算机 将程序的不同组件分别运行在不同的计算机上 带来的优点: 性能提高 稳定性提高(可拔插式) 现在性能问题已经解决了 通过分布式的方式 但是这些组件虽然分布在各个计算机上 但是它们还是一个整体 也就是说你操作的数据文件还是是同一份 默认情况下 程序能访问的数据 但是只有当前计算机。 """ #### 访问不同计算机上的文件数据 """ 如何能访问别的计算机上的文件呢? 只有一种办法,通过网络 通过网络把你要什么数据告诉服务器 服务器在通过网络把你要的数据发送给你,得需要使用socket ,需要配套的来一个服务器端 和 客户端程序,把客户端程序分发给各个python程序 python程序通过客户端来链接服务器端 从而完成数据的读写 也就是说数据库本质上就是一套C/S结构的TCP程序 我们完全可以自己来编写这么一套软件,但是需要考虑一下几个问题 1.socket需不需实现并发? 必须要 2.既然是并发 还要考虑线程安全问题? 需要给文件操作加锁 3.是不是任何计算机请求链接我都要接受呢? 不是需要进行用户认证 4.单纯的对本地计算机上的数据进行读取 速度都是非常慢的硬盘上的数据有寻道寻址时间 平均延迟时间,速度太慢! 要想办法提高数据的存取效率,通过索引。 到现在我们知道了要开发一款应用程序必须先解决上述四个问题,但是对于每一个公司而言,开发周期是非常重要的,不可能为了开发应用程序而先花大把时间来编写数据库程序,这便产生了专门的数据库软件厂商。写出了专门的数据库软件。 ``` ## 2.常见数据库 #### 关系型数据库 数据库可以为数据与数据之间建立关联关系,人是一条数据,他可能关联着一个工作岗位数据。双方可以通过自身找到对方。 """ mysql 免费开源 支持中大型企业 为了防止mysql被闭源 以及 担心oracle的优化能力 创始人Widenius 另起灶炉 开发了mariaDB mariaDB 完全兼容mysql 使用起来 一模一样 mysql的一生 坎坎坷坷 先后被 sun - oracle 收购 oracle 收费闭源 功能强大 分布式数据库 SQLServer 微软生态圈 仅支持 windows系统 太局限 DB2 IBM 开发的数据库软件 收费闭源 经常与IMB的机器绑定销售 打折啥的 #### 非关系型 通关key value存储数据各个数据之间没有关系 不是通用性数据库 有局限性,通常运行在将数据存储在内存中,以提高速度,所以非关系性数据库多用于缓存,与关系型数据库搭配使用。 MongoDB redis memcache **总结**: 我们通常说的数据库就是一套软件 有服务端和客户端 用来操作服务器端上的文件 ## 3.数据库相关概念 """ 数据: 用于记录事物的状态信息 可以是数字 字符 声音 图像等等 如name = jerry 记录: 一条记录用于保存一个事物的典型特征 就相当于文件中的一行 如jerry,180,man,帅 表: 本质就是一个文件,创建表的时候其实就是在创建一个文件 ,可以在数据库目录下看到 可不可能把所有数据全放到同一个文件里? 为了降低耦合性 方便管理 都应该把数据分门别类 放到不同文件中 库: 就是一个文件夹 DBMS: 数据库管理软件 就是一个套接字服务器端软件 数据库服务器: 运行有数据库管理软件的计算机 在公司我们开发者关心的部分是哪些? 从库往上的需要我们关心 DBMS 和 服务器是运维关心的 # 二.安装mysql(记得要在管理员权限下开CMD,不然启停mysql会被拒绝) #1.下载解压包 mysql 5.6版本----无界面操作哦 下载地址:https://dev.mysql.com/downloads/mysql/ 下载的时候提供了带界面的和不带界面的 用哪个呢? 服务器通常是不带界面的linux系统,并且熟练掌握SQL语句通常是面试官的基本要求 此处安装解压版的,下载对应的32/64位压缩包,解压到指定位置即可。 #2.解压到某个目录下 #3.添加环境变量 将bin所在的完整路径 copy 添加系统的path中 #4.作为服务器 应该自启动mysql服务器 需要制系统服务 注意:5.7后的版本需要先初始化 执行:mysqld --initialize-insecure mysqld --install 运行输入services,msc 查看是是否成功 需要注意的是 默认注册的服务名称叫做mysql 这与bin下的mysql是两码子事,一个系统服务一个是客户端执行文件 删除服务 sc delete mysql 如果需要重装的话... 启动服务 net start mysql 停止服务 net stop mysql #关闭服务器 tasklist | findstr mysqld taskkill /F /PID 8372 也可以直接退出CMD #5、连接服务器的指令 必要掌握 本质是TCP程序,必须指定ip和端口 ,如果服务器就运行在本机上 可以省略ip 如果端口没改过 也可以省略端口 完整的写法 : mysql -hip -P端口 -u用户名 -p密码 实例: mysql -uroot -p mysql 5.6 默认是没有密码的 #三 修改管理员密码 了解 #1.如果知道原始密码 可以使用mysqladmin 这个工具 mysqladmin -p旧密码 -u用户名 password 新密码 实例: mysqladmin -uroot -p password 123 ``` #2.不知道原始密码的情况 删除密码文件,会删除所有授权信息 跳过授权表 我们可以在启动服务器时 指定让其忽略授权信息 1.先关闭mysql服务器 net stop mysql 然后直接在终端执行 mysqld --skip-grant-tables 2.无密码登录root账户 直接mysql -u root -p 就可以进入mysql 3.执行更新语句 update mysql.user set password = password("123") where user="root" and host = "localhost";