时间昂贵、空间廉价
一段代码会消耗计算时间、资源空间,从而产生时间复杂度和空间复杂度。
假设一段代码经过优化后,虽然降低了时间复杂度,但依然需要消耗非常高的空间复杂度。 例如,对于固定数据量的输入,这段代码需要消耗几十 G 的内存空间,很显然普通计算机根本无法完成这样的计算。如果一定要解决的话,一个最简单粗暴的办法就是,购买大量的高性能计算机,来弥补空间性能的不足。
反过来,假设一段代码经过优化后,依然需要消耗非常高的时间复杂度。 例如,对于固定数据量的输入,这段代码需要消耗 1 年的时间去完成计算。如果在跑程序的 1 年时间内,出现了断电、断网或者程序抛出异常等预期范围之外的问题,那很可能造成 1 年时间浪费的惨重后果。很显然,用 1 年的时间去跑一段代码,对开发者和运维者而言都是极不友好的。
这告诉我们一个什么样的现实问题呢?代码效率的瓶颈可能发生在时间或者空间两个方面。如果是缺少计算空间,花钱买服务器就可以了。这是个花钱就能解决的问题。相反,如果是缺少计算时间,只能投入宝贵的人生去跑程序。即使你有再多的钱、再多的服务器,也是毫无用处。相比于空间复杂度,时间复杂度的降低就显得更加重要了。因此,你会发现这样的结论:空间是廉价的,而时间是昂贵的。
程序优化的最核心的思路
第一步,暴力解法。在没有任何时间、空间约束下,完成代码任务的开发。
第二步,无效操作处理。将代码中的无效计算、无效存储剔除,降低时间或空间复杂度(案例一体现)。
第三步,时空转换。设计合理数据结构,完成时间复杂度向空间复杂度的转移(案例二体现)。
说明:常用的降低时间复杂度的方法有递归、二分法、排序算法、动态规划等,而降低空间复杂度的方法就是数据结构,核心思路就是,能用低复杂度的数据结构能解决问题,就千万不要用高复杂度的数据结构。
降低复杂度案例
案例一
假设有任意多张面额为 2 元、3 元、7 元的货币,现要用它们凑出 100 元,求总共有多少种可能性?
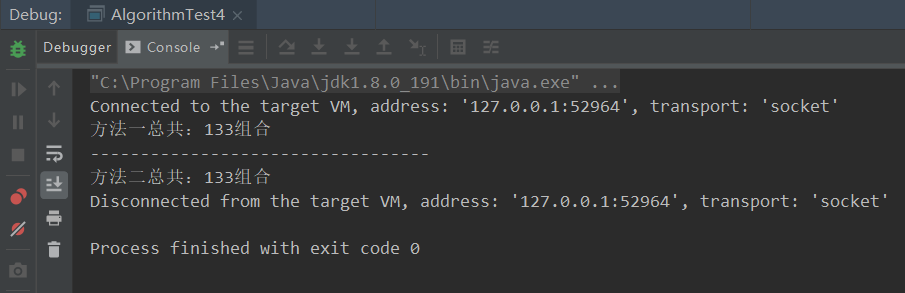
1 /** 2 * @author 佛大Java程序员 3 * @since 1.0.0 4 */ 5 public class AlgorithmTest4 { 6 public static void main(String[] args) { 7 AlgorithmTest4 algorithmTest4 = new AlgorithmTest4(); 8 algorithmTest4.s2_1(); 9 System.out.println("----------------------------------"); 10 algorithmTest4.s2_2(); 11 } 12 13 /** 14 * 方法一 :时间复杂度为O( n³ ) 15 */ 16 public void s2_1() { 17 int count = 0; 18 for (int i = 0; i < (100 / 7); i++) { 19 for (int j = 0; j < (100 / 3); j++) { 20 for (int k = 0; k <= (100 / 2); k++) { 21 if (i * 7 + j * 3 + k * 2 == 100) { 22 count += 1; 23 //System.out.println("i:"+ i + " j:" + j + " k:" +k); 24 } 25 } 26 } 27 } 28 System.out.println("方法一总共:"+count+"组合"); 29 } 30 31 /** 32 * 33 * 方法二:时间复杂度为O(n²) 34 */ 35 public void s2_2() { 36 int count = 0; 37 for (int i = 0; i < (100 / 7); i++) { 38 for (int j = 0; j < (100 / 3); j++) { 39 if (((100 - i * 7 - j * 3) % 2 == 0) && (100 - i * 7 - j * 3) >= 0) { 40 count += 1; 41 //System.out.println("i:"+ i + " j:" + j ); 42 } 43 } 44 } 45 System.out.println("方法二总共:"+count+"组合"); 46 } 47 48 }
方法一:使用3 层的 for 循环。从结构上来看,是很显然的 O( n³ ) 的时间复杂度。然而,仔细观察就会发现,代码中最内层的 for 循环是多余的。因为,当你确定了要用 i 张 7 元和 j 张 3 元时,只需要判断用有限个 2 元能否凑出 100 - 7* i - 3* j 元就可以了。
方法二:代码的结构由 3 层 for 循环,变成了 2 层 for 循环。很显然,时间复杂度就变成了O(n²) 。这样的代码改造,就是利用了方法论中的步骤二,将代码中的无效计算、无效存储剔除,降低时间或空间复杂度。
运行结果
案例二
查找出一个数组中,出现次数最多的那个元素的数值。
例如,输入数组 a = [1,2,3,4,5,5,6 ] 中,查找出现次数最多的数值。从数组中可以看出,只有 5 出现了 2 次,其余都是 1 次。显然 5 出现的次数最多,则输出 5。
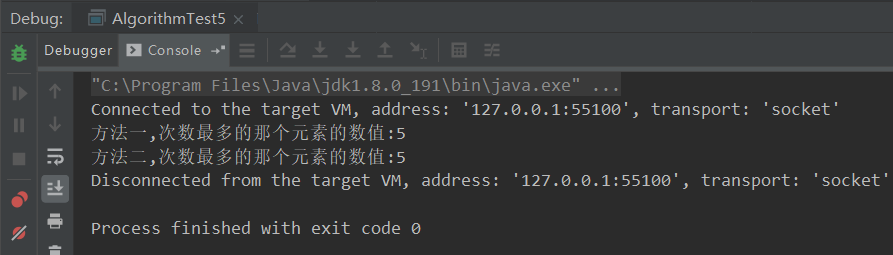
1 /** 2 * @author 佛大Java程序员 3 * @since 1.0.0 4 */ 5 public class AlgorithmTest5 { 6 public static void main(String[] args) { 7 AlgorithmTest5 algorithmTest5 = new AlgorithmTest5(); 8 algorithmTest5.s2_3(); 9 algorithmTest5.s2_4(); 10 } 11 12 /** 13 * 方法一:时间复杂度就是 O(n²) 14 */ 15 public void s2_3() { 16 int a[] = { 1, 2, 3, 4, 5, 5, 6 }; 17 //初始化最大值,最大次数,临时记录次数 18 int maxVal= 0,maxTime = 0,tmpTime ; 19 for (int i = 0; i < a.length; i++) { 20 tmpTime = 0; 21 for (int j = 0; j < a.length; j++) { 22 if (a[i] == a[j]) { 23 tmpTime += 1; 24 } 25 if (tmpTime > maxTime) { 26 maxTime = tmpTime; 27 maxVal = a[i]; 28 } 29 } 30 } 31 System.out.println("方法一,次数最多的那个元素的数值:" + maxVal); 32 } 33 34 /** 35 * 方法二:时间复杂度为 O(n) 36 */ 37 public void s2_4() { 38 int a[] = { 1, 2, 3, 4, 5, 5, 6}; 39 Map<Integer, Integer> d = new HashMap<>(); 40 for (int i = 0; i < a.length; i++) { 41 if (d.containsKey(a[i])) { 42 //HashMap不允许重复,相同的key会使用新值覆盖原值 43 d.put(a[i], d.get(a[i]) + 1); 44 } else { 45 d.put(a[i], 1); 46 } 47 } 48 //初始化最大值 49 int maxVal = -1; 50 //初始化最大次数 51 int maxTime = 0; 52 for (Integer key : d.keySet()) { 53 if (d.get(key) > maxTime) { 54 maxTime = d.get(key); 55 maxVal = key; 56 } 57 } 58 System.out.println("方法二,次数最多的那个元素的数值:" + maxVal); 59 } 60 }
方法一:采用两层的 for 循环完成计算。第一层循环,对数组每个元素遍历。第二层循环,则是对第一层遍历的数字,去遍历计算其出现的次数。这样,全局再同时缓存一个出现次数最多的元素及其次数就可以了时间复杂度就是 O(n²)。而且代码中,几乎没有冗余的无效计算。如果还需要再去优化,就要考虑采用一些数据结构方面的手段,来把时间复杂度转移到空间复杂度了。
方法二:定义一个 k-v 结构的字典,用来存放元素-出现次数的 k-v 关系。那么首先通过一次循环,将数组转变为元素-出现次数的一个字典。接下来,再去遍历一遍这个字典,找到出现次数最多的那个元素,就能找到最后的结果了。代码结构上,有两个 for 循环。不过,这两个循环不是嵌套关系,而是顺序执行关系。其中,第一个循环实现了数组转字典的过程,也就是 O(n) 的复杂度。第二个循环再次遍历字典找到出现次数最多的那个元素,也是一个 O(n) 的时间复杂度。因此,总体的时间复杂度为 O(n) + O(n),就是 O(2n),根据复杂度与具体的常系数无关的原则,也就是O(n) 的复杂度。空间方面,由于定义了 k-v 字典,其字典元素的个数取决于输入数组元素的个数。因此,空间复杂度增加为 O(n)。借鉴了方法论中的步骤三,通过采用更复杂、高效的数据结构,完成了时空转移,提高了空间复杂度,让时间复杂度再次降低。
运行结果
参考/好文:
拉勾教育 -- 重学数据结构与算法