工作中遇到这样的一个需求,按位置解析一些文本文件,它们由头部、详情、尾部组成,并且每一行的长度可能不一样,每一行代表的意思也可能不一样,但是每一行各个位置代表的含义已经确定了。
例如有下面这样一段文本:
H1201504280222
D1000001TYPE12000000000002
D20001DATA13
T10334
每一行的前两位决定了这一行各个位置代表的含义,例如以H1开关的第3位到第10位代表日期,尽管可以按照文档一行一行的对照来了解它们的含义,但这样不是一种折磨?经过一个小工具处理后,输出HTML文件,用浏览器打开后,展示如下:

是不是看着稍微舒服些了呢?
要实现的几个功能
- 可通过下拉框选择不同类型的文件
- 使用Swing选择文件再进行处理
- 易于扩展(可通过配置文件添加新的文件类型,而不需要更改Java代码)
相关实现
运行截图如下:
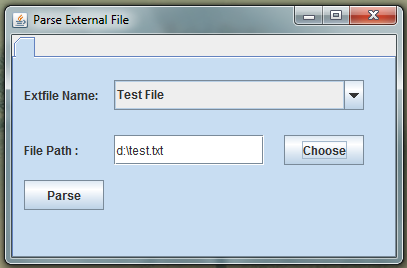
1.首先读取配置,将能处理的文件类型显示在下拉框中
通过file_list_config.properties文件进行配置:
test=Test File
需要有test.properties文件来定义有哪些不同的行:
H1=folder/Header.xml
D1=folder/Detail1.xml
D2=folder/Detail2.xml
T1=folder/Trailer.xml
而Header.xml代表用来定义以H1开头的行:
<?xml version="1.0" encoding="UTF-8"?>
<bean>
<field length="2">Flag</field>
<field length="8">Date</field>
<field length="4">Type</field>
</bean>
由于swing可的下拉框JComboBox不直接支持HTML中的key value对,可以像下面这样初始化:
// initial JComboBox
private JComboBox<FileItem> jSelect = new JComboBox<FileItem>();
.........
// define FileItem
public class FileItem {
private String key;
private String value;
..........
@Override
public String toString() {
return value;
}
}
// 填充下拉框
fileList = ResourceFactory.getSington().getFileItemList();
for (FileItem item : fileList) {
jSelect.addItem(item);
}
下面代码中 getFileItemList 是通过读取配置文件,返回一个 List 的结果集, 由于在 JComboBox 中展示的文本它会调用FileItem的toString进行输出,所以需要重写toString方法。
2.选择要处理的文件后,点击按钮 Parse,根据文件名称对缓存对象中获取各行的字段规则:
private Map<String, Map<String, List<RecordField>>> CONFIG_CACHE = new HashMap<String, Map<String, List<RecordField>>>();
如何缓存没有该文本对应的规则,需解析对应的XML文件并放入缓存中。
3.一行一行解析文本,根据前两位按照不同的规则返回html字符串,最后输出到结果文件中:
writer.write(appendHeader());
String line;
while ((line = reader.readLine()) != null) {
if ("".equals(line.trim())) {
continue;
}
try {
String identify = line.substring(0, 2);
if (configCache.containsKey(identify)) {
fields = configCache.get(identify);
writer.write(buildOutputStr(line, fields));
} else {
writer.write("Skip Record : " + line + "<br /><br />");
}
} catch (Exception e) {
writer.write("Parse Error : " + line + "<br /><br />");
}
}
writer.write(appendFooter());
4.如果需要添加新的要处理文件类型,往file_list_config.properties文件中进行追加,编写各个字段解析规则即可。
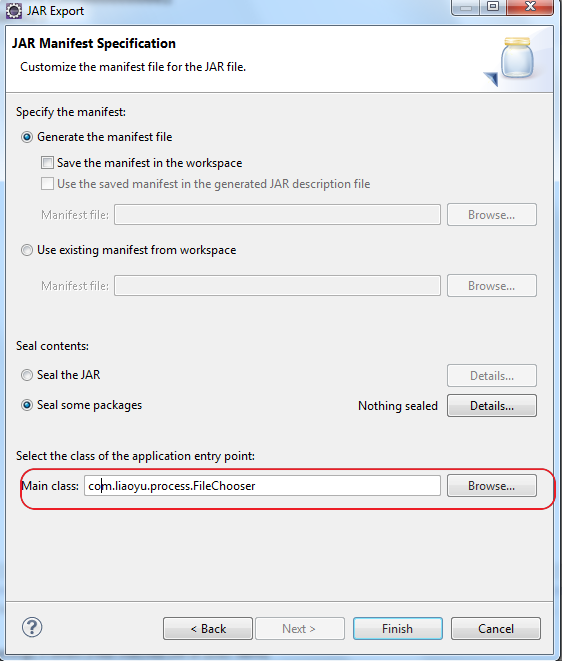
导出可运行Jar包
eclipse自带这项功能,在项目中右键
Export -> 一直next -> 最后选择入口类(需要有main方法)
存在的问题
- 不适合解析大文件,由于是生成html文件,如果浏览器打开超过10M的文件会相当卡。
- 原生的Swing界面很丑。
相关链接
查看源代码 点击这里
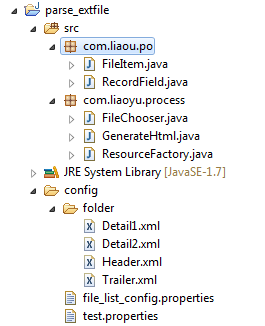
代码结构: