一般在推荐系统中,数据往往是使用 用户-物品 矩阵来表示的。用户对其接触过的物品进行评分,评分表示了用户对于物品的喜爱程度,分数越高,表示用户越喜欢这个物品。而这个矩阵往往是稀疏的,空白项是用户还未接触到的物品,推荐系统的任务则是选择其中的部分物品推荐给用户。

(markdown写表格太麻烦了,直接上传图片吧)
对于这个 用户-物品 矩阵,可以利用非空项的数据来预测空白项的数据,即预测用户对于其未接触到的物品的评分,并根据预测情况,将评分高的物品推荐给用户。预测评分的方式有很多,本篇主要讲述如何使用矩阵分解来进行这个预测。
1.奇异值分解SVD
想详细理解SVD,推荐一篇博客 奇异值分解(SVD)原理与在降维中的应用。
此时可以将这个 用户-物品 对应的m×n矩阵 M 进行 SVD 分解,并通过选择部分较大的一些奇异值来同时进行降维,也就是说矩阵M此时分解为:
 (不知道如何在 markdown 中输入公式,先用图片代替)
(不知道如何在 markdown 中输入公式,先用图片代替)
其中,m 是用户的维度,n 是物品的维度,k 是矩阵 M 的较大的 k 个奇异值,k 往往远小于 m 和 n,这也是 SVD 可以用来降维的原因。
如果我们要预测第 i 个用户对第 j 个物品的评分 mij ,则只需要计算 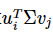 即可。通过这种方法,我们可以将评分表里面所有没有评分的位置得到一个预测评分。通过找到最高的若干个评分对应的物品推荐给用户。
即可。通过这种方法,我们可以将评分表里面所有没有评分的位置得到一个预测评分。通过找到最高的若干个评分对应的物品推荐给用户。
在 Python 的 numpy 中,linalg已经实现了SVD,可以直接调用。
>>> import numpy as np
>>> A=np.mat([[1,2,3],[4,5,6]])
>>> from numpy import linalg as la
>>> U,sigma,VT=la.svd(A)
>>> U
matrix([[-0.3863177 , -0.92236578],
[-0.92236578, 0.3863177 ]])
>>> sigma
array([ 9.508032 , 0.77286964])
>>> VT
matrix([[-0.42866713, -0.56630692, -0.7039467 ],
[ 0.80596391, 0.11238241, -0.58119908],
[ 0.40824829, -0.81649658, 0.40824829]])
有一点需要注意,sigma 本来应该是一个 2*2 的对角方阵,但 linalg.svd() 只返回了一个行向量的 sigma。之所以这样做,是因为当 M 是非常大的矩阵时,只返回奇异值可以节省很大的存储空间。当然,如果我们要重构 M,就必须先将 sigma 转化为矩阵。
可以看出这种方法简单直接,似乎很有吸引力。但是有一个很大的问题我们忽略了,就是SVD分解要求矩阵是稠密的,也就是说矩阵的所有位置不能有空白。有空白时我们的M是没法直接去SVD分解的。大家会说,如果这个矩阵是稠密的,那不就是说我们都已经找到所有用户物品的评分了嘛,那还要SVD干嘛! 的确,这是一个问题,传统SVD采用的方法是对评分矩阵中的缺失值进行简单的补全,比如用全局平均值或者用用户物品平均值补全,得到补全后的矩阵。接着可以用SVD分解并降维。
虽然有了上面的补全策略,我们的传统SVD在推荐算法上还是较难使用。因为我们的用户数和物品一般都是超级大,随便就成千上万了。这么大一个矩阵做SVD分解是非常耗时的。
2.改进的SVD
参考矩阵分解在协同过滤推荐算法中的应用-刘建平Pinard的博客,其中介绍了 3 种改进的 SVD 算法,分别是:FunkSVD,BiasSVD,SVD++。
FunkSVD
在Spark MLlib中,推荐算法只实现了基于矩阵分解的协同过滤推荐算法。其中,矩阵分解算法使用的是 FunkSVD 算法。不同于传统SVD,FunkSVD 将 用户-项目 矩阵 M 分解为两个低维的矩阵,而不是三个矩阵:
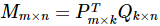
相关代码如下,这使用 movielens 数据集:
from pyspark import SparkContext
from pyspark import SparkConf
sc = SparkContext("local", "testing")
# 打开用户评分文件,此文件是用户对项目的评分,文件每一行前3项分别是用户id,物品id,评分
>>> user_data = sc.textFile("D:/movielens/ml-100k/u.data")
# 查看第一行数据
>>> user_data.first()
'196 242 3 881250949'
# 获取相关数据,即前3列
>>> rates = user_data.map(lambda x: x.split(" ")[0:3])
>>> print (rates.first())
['196', '242', '3']
# 将数据封装成 Rating 类
>>> from pyspark.mllib.recommendation import Rating
>>> rates_data = rates.map(lambda x: Rating(int(x[0]),int(x[1]),int(x[2]))) # 将字符串转为整型
>>> print (rates_data.first())
Rating(user=196, product=242, rating=3.0)
# 训练模型
>>> from pyspark.mllib.recommendation import ALS
>>> from pyspark.mllib.recommendation import MatrixFactorizationModel
>>> sc.setCheckpointDir('checkpoint/')
>>> ALS.checkpointInterval = 2
>>> model = ALS.train(ratings=rates_data, rank=20, iterations=5, lambda_=0.02)
18/02/27 21:01:30 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
18/02/27 21:01:30 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
18/02/27 21:01:31 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
18/02/27 21:01:31 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
# 预测用户38对物品20的评分
>>> print (model.predict(38,20))
2.8397113617489707
# 预测用户38最喜欢的10个物品
>>> print (model.recommendProducts(38,10))
[Rating(user=38, product=574, rating=7.962267822839763), Rating(user=38, product=555, rating=6.729462263620687), Rating(user=38, product=143, rating=6.585357510430526), Rating(user=38, product=1278, rating=6.543555968120091), Rating(user=38, product=843, rating=6.47086091691414), Rating(user=38, product=1425, rating=6.452495383671975), Rating(user=38, product=905, rating=6.143432962038866), Rating(user=38, product=812, rating=6.092267908277885), Rating(user=38, product=682, rating=6.045279001502015), Rating(user=38, product=562, rating=5.956117491161081)]
3.最小交替二乘
Spark MLlib 提供了 最小交替二乘 的实现,即 ALS 算法,可以参见 Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统 和 Spark 实践——音乐推荐和 Audioscrobbler 数据集