import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #导入mnist数据集
minst=input_data.read_data_sets('MNIST_data',one_hot=True)
def add_layer(inputs,in_size,out_size,activation_function=None):#添加一层隐藏层
#with tf.name_scope('layer'):
# with tf.name_scope('Weights'):
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#定义变量weights
#with tf.name_scope('biase'):
biases=tf.Variable(tf.zeros([1,out_size])+0.1,name='b')#定义变量biases
Wx_plus_b=tf.matmul(inputs,Weights)+biases#运算WX+b
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
xs=tf.placeholder(tf.float32,[None,784])#placeholder在后面输入
ys=tf.placeholder(tf.float32,[None,10])
prediction=add_layer(xs,784,10,activation_function=tf.nn.softmax)#调用函数,激励函数是softmax
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))#交叉熵运算,相当于loss 下面还会有介绍
train_step=tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)#定义优化器来优化loss
sess=tf.Session()#实例化Session
sess.run(tf.initialize_all_variables())#只有进行这一步所有的变量才会起作用
def compute_accuracy(v_xs,v_ys):#计算准确率的函数
global prediction
y_pre=sess.run(prediction,feed_dict={xs:v_xs})#对应上边的palceholder
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))#比较你预测的y和真实y那个1所在的位置。是一个布尔型量
print(sess.run(correct_prediction))
float=tf.cast(correct_prediction,tf.float32)#转化为float32类型
print(sess.run(float))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#转化为float32格式然后求其正确率 tf.cast转换格式
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})
return result
for i in range(1000):
batch_xs,batch_ys=minst.train.next_batch(100)
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})
if i %100==0:
print(compute_accuracy(
minst.test.images,minst.test.labels
))
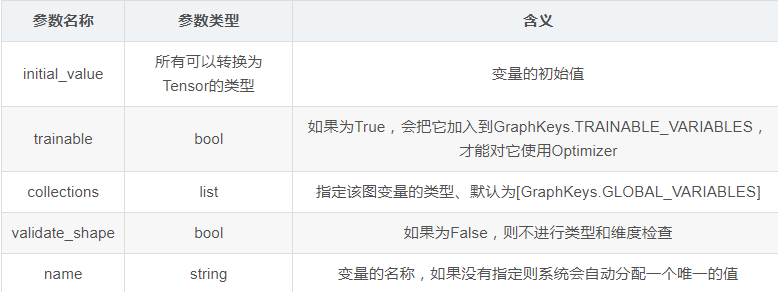
tensorflow定义一个变量的函数Varible
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
Weights=tf.Variable(tf.random_normal([in_size,out_size])) tf.random_normal正态分布
e.g. weights=tf.Varible(tf.random_normal([2,3],stddev=2,mean=0,seed=1)) 服从正态分布的 2×3的矩阵 标准差为2 均值为0 ,随机种子为1
tf.zeros全0数组 tf.ones全1数组 tf.constant 直接给值 tf.truncated_normal()去掉过大偏离点的正态分布
tf.random_uniform()平均分布
tf.placeholder(dtype, shape=None, name=None)
此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
激活函数:

交叉熵:


学习率


滑动平均


