申明:因为看的这个课老师讲的有点乱,课程也有的章节少那么几小节。所以对一些东西没理解透彻,而且有些乱。
所以,望理解,等以后学的更深刻了再回来修改。
1.ROC与AOC
ROC与AUC

ROC:横轴False 纵轴TRUE
理想情况下(0,1)达不到 最完美的情况
每一个Threshold都可以判断出来TPR,FPR
比如Threshold最大时,TP=FP=0对应于原点。即对应的都是负样本
当Threadhold最小时,TN,FN都为0,对应于(1,1)点,即都是正样本
(1,0)点是最糟糕的点,因为他避开了所有的正确答案
(0,0)点实际上分类器预测的所有样本都是负样本。因为positive全为01,所以只有Not positive
(1,1)实际上分类器预测的所有样本都是正样本 因为只有positive
对于y=x上的点,这条对角线上的点其实表示的是一个采用随机猜想策略的分类器的结果,表示该分类器对于一半的样本猜测其为正样本,另一半为负样本。
AUC被定义为曲线下的面积,AUC在0.5到1之间
(之所以大于0.5是因为几乎不存在一个模型还不如猜的准)曲线面积越大越好即对于分类器而言,AUC越大越好
从sklearn.metrics import roc_auc_score
导入AUC计算,只需要传入参数是(Y真实值,Y预测值)
2.在树的可视化的时候,由是否满足根特征的条件分为True和False 样本数占的越大颜色越深,如果发现大多数数据都属于一类的话可能会发生过拟合,遇到这种情况的时候,调整决策树的最主要依赖的特征,把之前最主要依赖的特征直接Drop重做一个决策树(反正在建造树的时候也是随机选择几个特征)

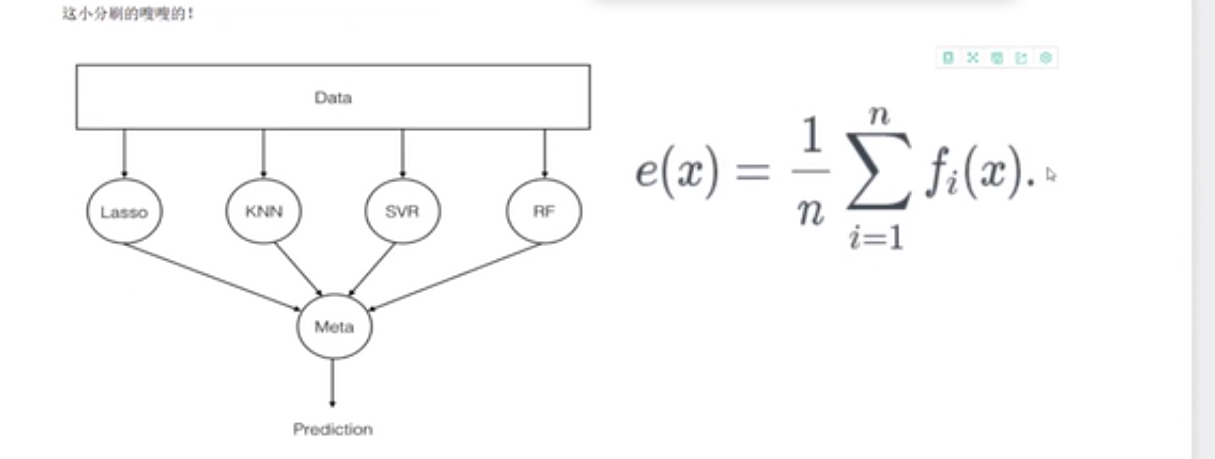
在集成的时候可以针对不同的树将他们的预测结果取个平均,取平均后再去计算AUC时发现的确比就一颗树的时候要好许多。
在sklearn.ensemble导入RandomForestClassifier
rf=RandomForestClassifier(
n_estimators=10,10棵树
max_features=3,
random_state=SEED)直接集成随机森林,10棵树
平均分策略并不是很好。在集成时,将效果差的直接Drop,也可以根据不同的贡献程度分配不同的权重来进行

stacking:
第一层选择好多个弱分类器集成,然后将输出结果作为第二层的输入。不过在这里我不知道第二层的分类器处理第一层输出数据时到底是如何处理的,很乱,不知道原理,以后来填坑。
不过在选择数据时,第一层和第二层不能用同样的数据,但是如果切分开的话又会造成数据量少而影响结果。所以,还是需要用交叉验证。
还有虽然说stacking是串行,但也可以并行操作 SuperLearner
3.贝叶斯
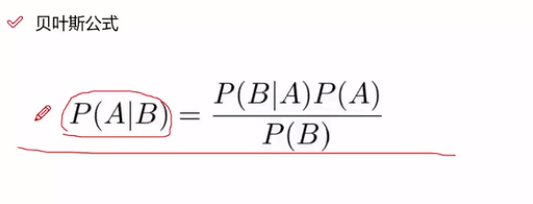
其实这个公式可以由条件概率公式证明。P(AB)=P(A|B)P(B)=P(B|A)P(A)很明显吧..


对于垃圾邮件的过滤。P(h+)或者P(h-)都是很容易求的,就是指在给定库中二者的比例。
p(D|h+)表示在非垃圾邮件中包含这个邮件的概率。因为这份邮件也是由若干单词构成。扩展式如上。说实话不理解这里,因为我觉得所谓的扩展和没扩展一样的啊...扩展成上式之后再换成朴素贝叶斯,相互之间独立,所以上式又可以变成P(d1|h+)*P(d2|h+)。。。。这个就很容易得到了吧...就相当于这么多非垃圾邮件中出现某个单词的频率..也是先验概率。

TF-IDF
TF就是词频浏览,IDF是逆文档频率,上面有计算公式。据我目前在学习时所体会到的,这个只是一种将一个个输入数据转变为向量,可以根据词频,也可以根据这个来计算每个词对应的数然后构成向量,如下既是引用这个。

4.SVM
SVM添加超平面的时候尽量使最靠近分离平面的那个元素与超平面的距离变大。
大部分数据对于分离超平面都没有作用,能决定分离超平面的,只是已知的训练数据中很小的一部分。对于超平面有着非常强大影响的数据点也被称为支持向量。
核函数可以将原始特征映射到另一个高维特征空间中,解决原始空间的线性不可分问题
今天只是简单的了解,之前只会直接从sklearn中调,现在想学习原理,一起加油吧
5.K-means
聚类概念:
无监督问题,聚类:相似的东西分到一组
评估和调参有些困难
K means
要得到簇的个数 K 聚成几堆
质心:均值,即向量各维度取平均值 对于每一堆中有一个质心
距离的度量:欧氏距离和余弦相似度
要先对数据进行标准化
优化目标:对于每一个簇,其中每一个样本到中心点的距离越近越好
根据K,会初始化随机K个点,然后计算点分别到这K个点的距离来进行分离,
更新质心,将一个簇里面再算一个质心。
再重新计算距离,进行分类
继续更新///////////
直到质心基本不变了或者是样本大致不再变了
劣势:
K值难确定 复杂度与样本呈现线性关系 很难发现任意形状的簇 与初始值也有很大的原因
聚类评估:轮廓系数:
计算一个簇中一个样本到其他样本的平均距离
越小越好一个样本到其他簇的平均距离,希望越大越好
s=b-a/max(a,b)接近1越好
6.PCA
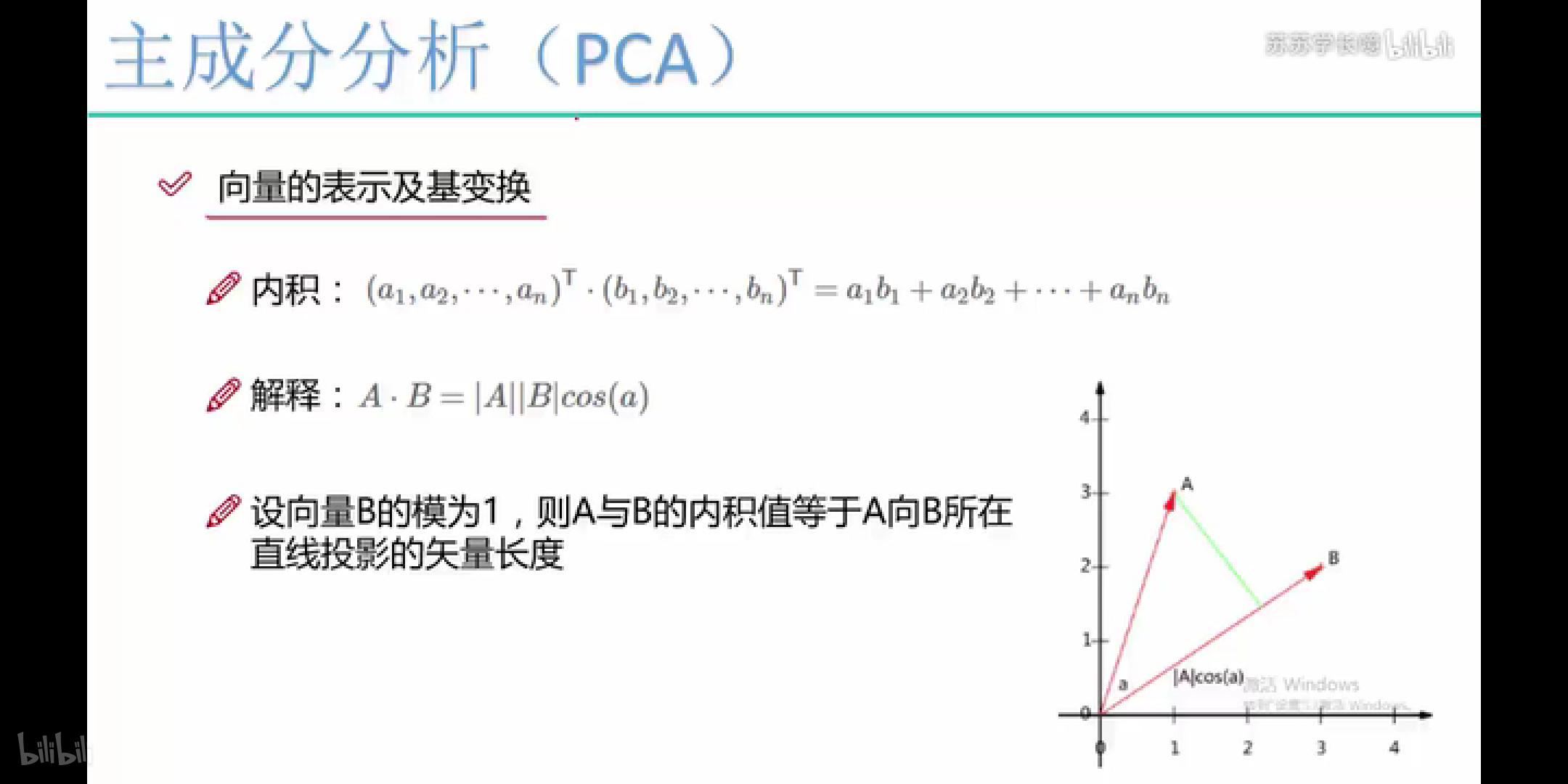

基变换,所以对于降到K维,我们也是需要找到一个K维向量,然后去和原来的向量做内积运算,即可降维


在PCA中尽量使投影的方差比较大

想要找不相关的也就是垂直的,90度

由协方差矩阵可以看出,其对角线为方差,其他是协方差,我们想要让协方差为0



所以可以实现将协方差对角化

原始数据输入,构造协方差矩阵1/mXX的转置,求其特征值和特征向量,然后将特征向量从小到大排序。因为最后化为1维,所以选择最大的即可。对角化的话特征向量组成的矩阵可以使协方差矩阵对角化。对于原数据,只需用选择出来的特征向量去内积。因为是基,所以模为1.