转:
MySQL 慢查询日志介绍
一. 慢查询介绍
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过指定阀值的SQL语句,运行时间超过long_query_time值的SQL,会被记录到慢查询日志中。
默认情况下,MySQL数据库并不启动慢查询日志,需要手动开启。如果不是调优需要的话,一般不建议开启,因为开启慢查询日志会或多或少带来一定的性能影响。
在SQL Server中我们利用SQL Profile来记录SQL执行情况,在Oracle中我们可以使用AWR、ASH报告来分析历史SQL执行情况,类似的调优方式映射到MySQL中,即对应为慢查询日志。
二. 参数介绍
介绍与慢查询日志相关的参数
slow_query_log:是否开启慢查询日志,1表示开启,0表示关闭。
slow_query_log_file:MySQL慢查询日志存储路径。
long_query_time :慢查询阈值(s),当查询时间多于设定的阈值时,记录日志。
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中。
log_throttle_queries_not_using_indexes:表示每分钟允许记录到slow_log的且未使用索引的sql语句次数(0为无限制,如果为固定值,可能会记录不到sql)。
log_output:日志存储方式。’FILE’表示存入文件,‘TABLE’表示存入系统表。因为FILE模式开销比较低,所以默认为FILE。
log_slow_admin_statements = 1: 记录ALTER TABLE等语句引发的慢查询
log_slow_slave_statements = 1:记录从服务器产生的慢查询
min_examined_row_limit = 100 :SQL扫描行数大于等于100行才会被记录
我们可以通过show variables命令查看当前具体的参数值,如下查看当前slow_query_log为OFF,即表示未开启慢查询日志,long_query_time值为2,即表示慢查询阈值为2s。
-
mysql> show variables like '%slow_query_log%';
-
+---------------------+----------+
-
| Variable_name | Value |
-
+---------------------+----------+
-
| slow_query_log | OFF |
-
| slow_query_log_file | slow.log |
-
+---------------------+----------+
-
-
mysql> show variables like '%long_query_time%';
-
+-----------------+----------+
-
| Variable_name | Value |
-
+-----------------+----------+
-
| long_query_time | 2.000000 |
-
+-----------------+----------+
三. 开启慢查询日志
开启慢查询日志只需要如下修改部分参数即可,这里设置的慢查询阈值为0.1s,项目上可以根据实际情况调整,这边的建议是如果压测可以设置为0.1s,如果是非压测可以设置为2s。由于开启了log_queries_not_using_indexes,所以慢日志不仅会记录超过阈值的SQL,没有走索引的SQL也会记录日志,即使这些SQL并没有超过阈值。通过set global设置参数后,只会在新连接中生效,所以要查看修改后的参数值,需要重新连接。
-
mysql> set global long_query_time = 0.1;
-
Query OK, 0 rows affected (0.00 sec)
-
-
mysql> set global log_queries_not_using_indexes = 1;
-
Query OK, 0 rows affected (0.00 sec)
-
-
mysql> set global log_throttle_queries_not_using_indexes = 0;
-
Query OK, 0 rows affected (0.00 sec)
-
-
mysql> set global min_examined_row_limit = 100;
-
Query OK, 0 rows affected (0.00 sec)
-
-
mysql> set global slow_query_log = 1;
-
Query OK, 0 rows affected (0.00 sec)
四. 日志内容
我们得到慢查询日志后,最重要的一步就是去分析这个日志。我们先来看下慢日志里到底记录了哪些内容。
如下图是慢日志里其中一条SQL的记录内容,可以看到有时间戳,用户,查询时长及具体的SQL等,内容其实是很齐全的。但是存在一个问题,慢日志里往往有许多SQL,不可能一条一条SQL看过去,我们需要将所有的慢SQL分组统计后在进行分析。
-
# Time: 2018-08-16T00:00:04.821003+08:00
-
# User@Host: zwfwroot[zwfwroot] @ 19.15.0.30 [19.15.0.30] Id: 67508
-
# Schema: gdqlk Last_errno: 0 Killed: 0
-
# Query_time: 14.344185 Lock_time: 0.000028 Rows_sent: 237064 Rows_examined: 237064 Rows_affected: 0
-
# Bytes_sent: 96078006
-
SET timestamp=1534348804;
-
SELECT * FROM `audit_catalog_lobby`;
五. 日志分析
pt-query-digest是用于分析MySQL慢查询的一个工具,先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,同时把分析结果输出到文件中,我们可以借助分析结果找出问题进行优化。
pt-query-digest是percona-toolkit工具包下的一个工具,如果MySQL是使用Linux_5.7.22版本的bin包安装的话,默认会安装percona-toolkit,可以直接使用pt-query-digest命令来分析慢查询日志。
Linux下使用如下命令分析指定时间范围内的慢查询,slow.log需要指定具体路径,slow_report.log指定输出文件。
# pt-query-digest slow.log --since '2017-01-07 09:30:00' --until '2017-01-07 10:00:00' > slow_report.log
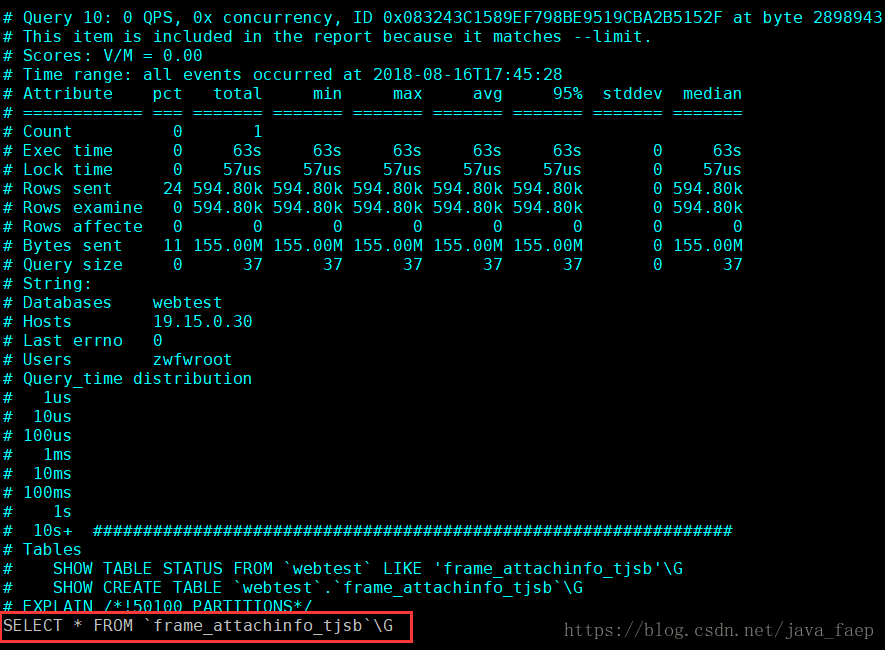
下面介绍通过pt-query-digest分析slow.log后得到的slow_report.log文件。
文件内容总体分成3个部分,第一部分为总体统计结果,第二部分为查询分组统计结果,第三部分为每一类查询的详细统计结果。
(1) 总体统计结果

Overall:查询总数、唯一查询数量、QPS、并发
Time range:查询的时间范围
Exec time :执行时间
Lock time:被阻塞时间
Rows sent:查询返回行数
Rows examine : 查询扫描行数
query size : 查询数据量
total:总计 min:最小 max:最大 avg:平均 stddev: 标准差
95%:把所有值从小到大排列,位于95%的值
median:中位数,把所有值从小到大排列,位于中间的值

(2) 查询分组统计结果

Rank:所有语句的排名,默认按查询总时间降序排列
Query ID:SQL的ID
Response:总执行时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:方差均值
Item:查询对象

(3) 每个查询的详细统计结果

Query:对应第二部分中的Rank排名
ID:查询ID号,与Query ID对应
Time range:查询时间范围
Attribute:针对此类查询的统计
Databases:数据库名
Hosts:执行查询的IP分布(占比)
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中10s以上查询数较多。
六. 总结
项目上可以通过此方法来优化SQL,根据Rank排名先后,依次分析优化SQL即可。