一、安装pandas
pip install pandas
二、数据结构
pandas有两种数据结构,这里篇幅主要讲述DataFrame。
DataFrame相当于一种二维的数据模型,相当于excel表格中的数据,有横竖两种坐标,横轴很Series 一样使用index,竖轴用columns 来确定,在建立DataFrame 对象的时候,需要确定三个元素:数据,横轴,竖轴。
三、DataFrame基本使用
本次案例使用的测试表单:https://pan.baidu.com/s/1xn6gdMlh0pWHa-pnVv2LqA
1 创建DataFrame数据
创建不是我们本次的重点,我们所直接使用下列读取现有表的方法
2 读取excel/csv,读取到的数据在DataFrame具柄中进行处理
# 读取test.xls,并指定sheet df = pd.DataFrame(pd.read_excel('test.xls',sheet_name='detail'))
3 抽取指定列名赋值给need_df
# 指定列名,将这一列赋值到package_num_df 这个具柄,并打印结果 need_df = df[['工厂','仓库','捆包号','树种','规格','账面数量','账面米数']] print(need_df)
4 在need_df的dataframe中筛选[捆包号]=J-0001-04,并打印结果
find_need_df = need_df.loc[need_df['捆包号'] == 'J-0001-04'] print(find_need_df)
5在df的dataframe中删除label标签=1 的数据并打印结果(dataframe只存在于内存中,并不会改变原来的excle表数据,可以通过将内容中的dataframe重新赋值给新表即可
#删除行号=1的那一整行,axis默认=0,inplace默认=False(不删除原来excel的数据) 标志为True的话就说明将存储在内存中的df 行号为1进行删除 res = df.drop(labels=1, axis=0, inplace=True) print(df)
find_need_df = need_df.loc[need_df['捆包号'] == '原来df数据
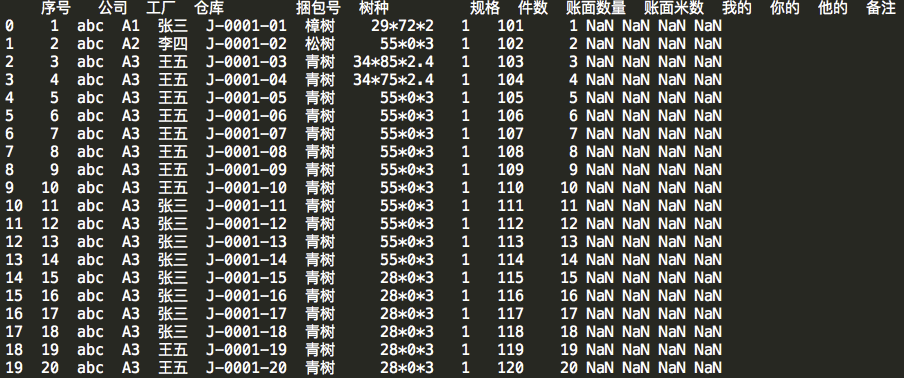
drop后df的数据
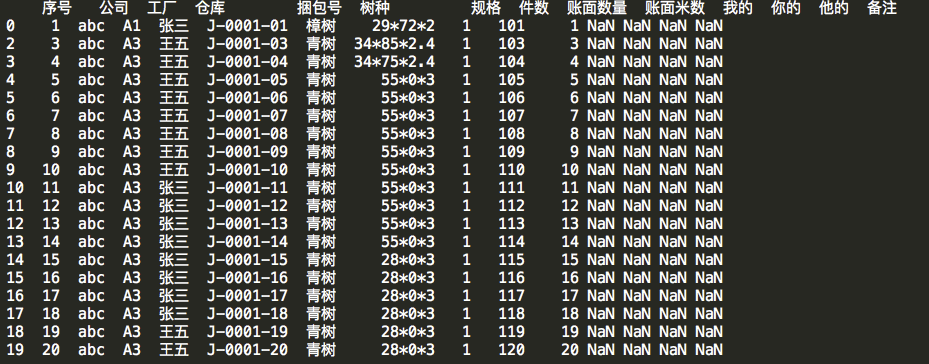
6写入excel/csv
#安装本地目录,格式化制定文件名称 wb_path = os.path.join(dir_path,'work_book') ctime = datetime.datetime.now().strftime('%Y%m%d_%H%M') df.to_excel('%s/%s_detail.xls'%(wb_path,ctime))
若遇到 # ModuleNotFoundError: No module named 'xlwt' ,则需要安装xlwt模块
find_need_df.to_csv('temp.csv', mode='a', encoding='gbk')
四、DataFrame增删改查操作
1 创建练习案例dataframe


import pandas as pd import numpy as np data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2017,2016,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(data, columns = ['year', 'city', 'population', 'debt']) df1 = pd.DataFrame({'apts': [55000, 60000], 'cars': [200000, 300000], }, index=['Shanghai', 'Beijing']) df2 = pd.DataFrame({'apts': [25000, 20000], 'cars': [150000, 120000], }, index=['Hangzhou', 'Najing']) df3 = pd.DataFrame({'apts': [30000, 10000], 'cars': [180000, 100000], }, index=['Guangzhou', 'Chongqing']) df4 = pd.DataFrame({'apts': [55000, 60000, 58000], 'cars': [200000, 300000, 250000], 'cities': ['Shanghai', 'Beijing', 'Shenzhen']}) df5 = pd.DataFrame({'salaries': [10000, 30000, 30000, 20000, 15000], 'cities': ['Suzhou', 'Beijing', 'Shanghai', 'Guangzhou', 'Tianjin']}) # print(df1) # print(df2) # print(df3) # print(df4) # print(df5)
2 增
# frame.ix[0] = np.arange(4) # 在第0行添加新行,分别为0,1,2,3 # frame.insert(0, 'temp', frame.year) # 在第0列处添加新列,名为temp # frame.ix[:, 'xx'] = np.arange(6) # 在末尾添加列名=xx的新列 # df1.append(df2) # 往df1末尾添加df2形成一个新数据 # pd.concat([df1, df2, df3]) # 往末尾添加多个dataframe,复用原来的column # pd.concat([df1, df2, df3], axis=1,sort=False) #axis=1时,不复用其他df的colums,各自使用自己的colums横向阶梯式合并 # 按照关键字做并集 # result = pd.merge(df4, df5, on='cities') #按照关键字cities的值相等时,将数据做并集 # result2 = pd.merge(df4, df5, on='cities', how='outer') # 按colums作并集,然后其他数据依次并集填入,不存在的值置为NaN
3 删
# del frame['year'] # 删除year列 # frame = frame.drop(['city', 'debt'], axis=1) # 删除多列,axis=1 表示x轴方向 # frame = frame.drop([0, 1, 2]) # 删除dataframe索引= 0、1、2行 # # frame.dropna() # 删除带有Nan的行 # frame.dropna(axis=1, how='all') # 删除全为Nan的列 # frame.dropna(axis=1, how='any') # 删除带有Nan的列 # frame.dropna(axis=0, how='all') # 删除全为Nan的行 # frame.dropna(axis=0, how='any') # 删除带有Nan的行 默认选项为此
4 改
# 元素赋值 # frame.loc[0, 'city'] = 'YunCheng' # 将frame数据中 dataframe索引=0,colums=city 的值改为 YunCheng # frame.iloc[0, 0] = 2011 #将frame数据中,dataframe y轴索引=0,x轴索引=0的值改为2011(索引为主) # frame.at[0, 'city'] = 'YunCheng' # frame.iat[0, 0] = 2010 #将frame数据中,dataframe y轴索引=0,x轴索引=0的值改为 2010 # frame.fillna(value=1) # 用1替换NaN # 列赋值 # frame['year'] = 2000 #将year这一列的数值全部更改为2000 # frame.debt = np.arange(6) #将debt这一列的值按0-5 依次填入 # val = pd.Series([200, 300, 500]) #制作series二维数列, # frame['debt'] = val #将val依次填入debt这一列,剩余没有被填充到的默认NaN # 行赋值 # val = pd.Series(['aa', 2000, 500], index=['city', 'year', 'population']) #制作二维数列 # frame.loc[0] = val #将val按照列 year city population的值分别新增到x轴首行,并将索引位置0,debt则置NaN
5 查
# frame.index # 查询frame数据的所以y轴索引起止、步长 # frame.columns # 查询frame数据的colums具体有哪些列 # frame.values # 查询frame数据的值,按y轴索引,从0开始,每一行作为一个列表,共6行组成一个新的大列表 # 元素查找 # xx = frame.loc[0, 'city'] # 数据是什么类型,xx就是什么类型 # xx = frame.loc[[0], ['city']] # DataFrame类型 # 行查找 # df = frame.loc[0:2] # DataFrame数据 y轴索引切片0~2 顾首顾尾。 # df = frame.iloc[0:2] # DataFrame类型 y轴索引切片0~2 顾首不顾尾。 # df = frame[0:3] # DataFrame数据,y轴索引切片0~3 顾首不顾尾 # df = frame.ix[0] # Series类型 y轴索引为0,的那一行数据 # 列查找 # df = frame.loc[:, 'city'] # 切片查找,列为city的那一列 # df = frame.loc[:, ['city', 'population']] # 切片查找,列为city、population的那两列形成新的dataframe # df = frame.iloc[:, 0:2] # DataFrames数据x轴切片, 索引为0~2 顾首不顾尾形成新的dataframe # df = frame['year'] # 将year那一列的所有值取出 # df = frame.year # Series类型 同上 # df = frame[['population', 'year']] # DataFrame类型 筛选population year两列重新组合dataframe # df = frame.filter(regex='population|year') # 结果同上 # frame[frame.year > 2016] # 选择frame.year中>2016的行 # res =frame[frame.year.isin(['2016', '2015'])] # DataFrame数据,筛选year= 2016 或者2015的数据 # res = frame[['city', 'year']][0:3] # DataFrame 筛选出city和year两列,并按y轴 0~3 顾首不顾尾进行切片,重组成新的dataframe # 块查找 # df = frame.iloc[0:2, 0:2] # DataFrame数据,按x轴 y轴分别进行索引0~2 顾首不顾尾的切片,并重组新的dataframe # 条件查找 # df = frame.year.notnull() # Series类型 判断year列的值是否不为空 # df = frame['year'].notnull() # Series 同上 # df = frame[frame.year.notnull()] # DataFrame类型 按照year非空筛选之后的结果 # df = frame[frame.year.notnull()].values # ndarray类型,按照year非空筛选之后的结果,形成一个大列表 # df = frame[frame.year == 2016][frame.city == 'Beijing'] # DataFrame # df = frame.debt[frame.year == 2016][frame.city == 'Beijing'] # 使用多条件year=2016、city=Beijing查询debt的值
五、数据透视表
话不多说,直接上例子说明下简单的一个用法:
本次案例使用的测试表单:https://pan.baidu.com/s/1HZCN9wZ_6sSNSnbUZPViHQ
import pandas as pd import numpy as np df = pd.read_excel('./work_book/pandas_sheet.xlsx') pd.set_option('display.width', None) #解决pandas模块会出现省略号的问题 # print(df.head()) #读取前五行数据 df['Status'] = df['Status'].astype('category') df['Status'].cat.set_categories(['won','pending','presented','declined'], inplace=True) ### 例1: 均值运算数据透视 # 单索引为[Name]字段,account price quantity进行平均值运算 res_ave_1 = pd.pivot_table(df, index=['Name']) # print(res_ave_1) # 多索引为[Name],[Rep],[Manager]字段,account price quantity进行平均值运算 res_ave_2 = pd.pivot_table(df,index=['Name', 'Rep', 'Manager']) # print(res_ave_2) # 多索引为[Manager][Rep]字段,account price quantity进行平均值运算 res_ave_3 = pd.pivot_table(df, index=['Manager','Rep']) # print(res_ave_3) # 多索引为[Manager][Rep]字段,value为[Price]进行平均值运算 res_ave_4 = pd.pivot_table(df, index=['Manager','Rep'], values=['Price']) # print(res_ave_4) # 多索引为[Manager][Rep]字段,value为[Price]并使用numpy的mean方法,并计算对应数据量的长度 res_ave_5 = pd.pivot_table(df, index=['Manager','Rep'], values=['Price'], aggfunc=[np.mean, len]) # print(res_ave_5) ### 例2: 求和运算数据透视 # 表格从左往右,以[Manager]为第一索引,[Rep]为第二索引,表格最上面以[Price]为第一索引,二级索引以[Product]的明细分别展开, # 统计数据以数据求和,product 没有的部分填充NaN(fill_value=0是将NaN填充为0),margins=True表示所有表进行所有项目合计求和 res_sum_1 = pd.pivot_table(df, index=['Manager','Rep'], values=['Price'], columns=['Product'], aggfunc=[np.sum], fill_value=0, margins=True) # print(res_sum_1) #表格从左往右,以[Manager]为第一索引,[status]为第二索引,表格上面以'均值'、'合计'、'单元格长度个数'三大项作为大列,大列中分别都以 # CPU Maintenance Monitor Software 作为明细项列分开进行单独计算(NaN项以0填充) res_sum_2 = pd.pivot_table(df, index=['Manager', 'Status'], columns=['Product'], values=['Quantity', 'Price'], aggfunc={'Quantity':len, 'Price':[np.sum,np.mean]}, fill_value=0 ) # print(res_sum_2) ### 例3:数据透视表过滤 #上述透视表res_sum_2生成后,他就位于DataFrame中,所以可以进行标准的DataFrame函数对其进行过滤,以Manager为筛选字段,字段值=Debra Henley res_filter_1 = res_sum_2.query('Manager == ["Debra Henley"]') # print(res_filter_1)