介绍如何在Intellij Idea中通过创建maven工程配置MapReduce的编程环境。
一、软件环境
我使用的软件版本如下:
- Intellij Idea 2017.1
- Maven 3.3.9
- Hadoop伪分布式环境( 安装教程可参考这里)
二、创建maven工程
打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建Java工程即可,不用勾选Creat from archetype,如果想创建web工程或者使用骨架可以勾选) 
设置GroupId和ArtifactId,下一步。 
设置工程存储路径,下一步。 
Finish之后,空白工程的路径如下图所示。

完整的工程路径如下图所示:

三、添加maven依赖
在pom.xml添加依赖,对于Hadoop 2.7.3版本的hadoop,需要的jar包有以下几个:
- hadoop-common
- hadoop-hdfs
- hadoop-mapreduce-client-core
- hadoop-mapreduce-client-jobclient
-
log4j( 打印日志)
pom.xml中的依赖如下:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>四、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = debug,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
五、启动Hadoop
启动Hadoop,运行命令:
cd hadoop-2.7.3/
./sbin/start-all.sh访问http://localhost:50070/查看hadoop是否正常启动。
六、运行WordCount(从本地读取文件)
在工程根目录下新建input文件夹,input文件夹下新增dream.txt,随便写入一些单词:
I have a dream
a dream在src/main/java目录下新建包,新增FileUtil.java,创建一个删除output文件的函数,以后就不用手动删除了。内容如下:
package com.mrtest.hadoop;
import java.io.File;
/**
* Created by bee on 3/25/17.
*/
public class FileUtil {
public static boolean deleteDir(String path) {
File dir = new File(path);
if (dir.exists()) {
for (File f : dir.listFiles()) {
if (f.isDirectory()) {
deleteDir(f.getName());
} else {
f.delete();
}
}
dir.delete();
return true;
} else {
System.out.println("文件(夹)不存在!");
return false;
}
}
}编写WordCount的MapReduce程序WordCount.java,内容如下:
package com.mrtest.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
/**
* Created by bee on 3/25/17.
*/
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i = values.iterator(); i.hasNext(); sum += val.get()) {
val = (IntWritable) i.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
FileUtil.deleteDir("output");
Configuration conf = new Configuration();
String[] otherArgs = new String[]{"input/dream.txt","output"};
if (otherArgs.length != 2) {
System.err.println("Usage:Merge and duplicate removal <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setReducerClass(WordCount.IntSumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行完毕以后,会在工程根目录下增加一个output文件夹,打开output/part-r-00000,内容如下:
I 1
a 2
dream 2
have 1这里在main函数中新增了一个String类型的数组,如果想用main函数的args数组接受参数,在运行时指定输入和输出路径也是可以的。运行WordCount之前,配置Configuration并指定Program arguments即可。

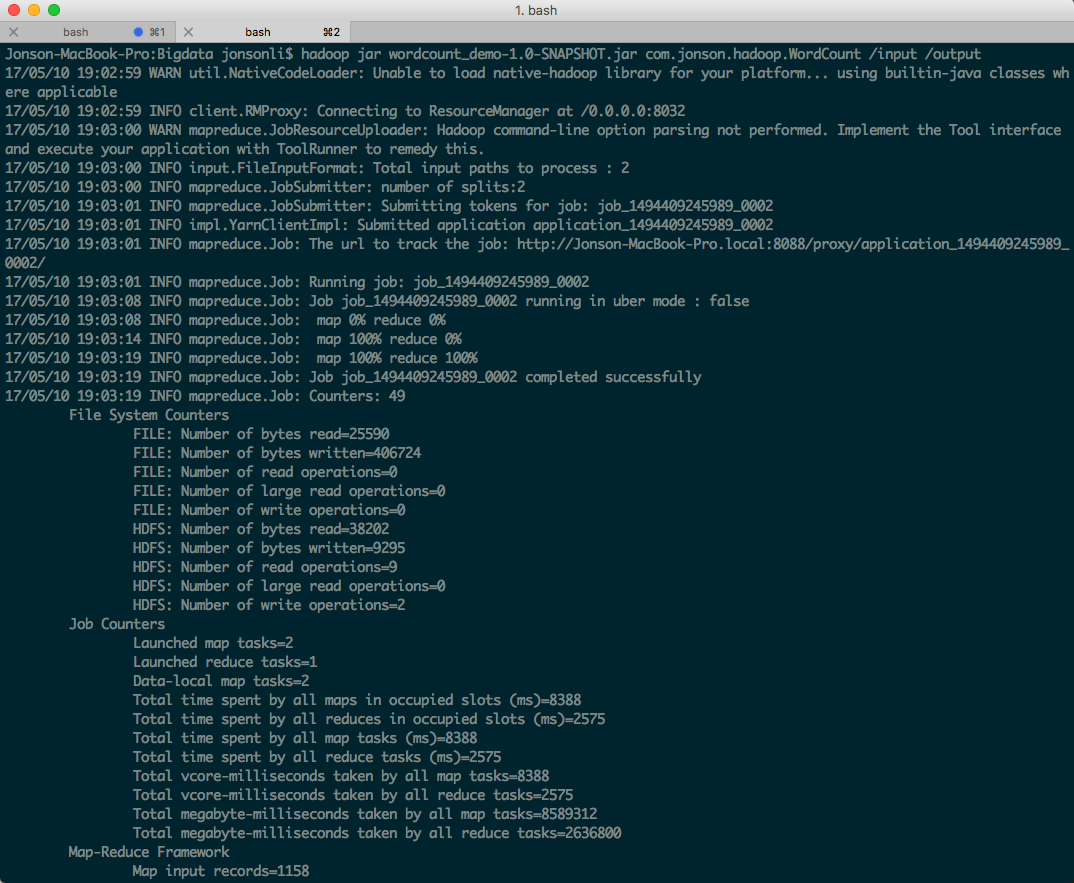
七、运行WordCount(从HDFS读取文件)
在HDFS上新建文件夹:
hadoop fs -mkdir /worddir如果出现Namenode安全模式导致的不能创建文件夹提示:
mkdir: Cannot create directory /worddir. Name node is in safe mode.运行以下命令关闭safe mode:
hadoop dfsadmin -safemode leave上传本地文件:
hadoop fs -put dream.txt /worddir修改otherArgs参数,指定输入为文件在HDFS上的路径:
String[] otherArgs = new String[]{"hdfs://localhost:9000/wo
验证过程: