Solr 不能对中文进行分词,ikanalyzer可以。
1.下载 jar形式
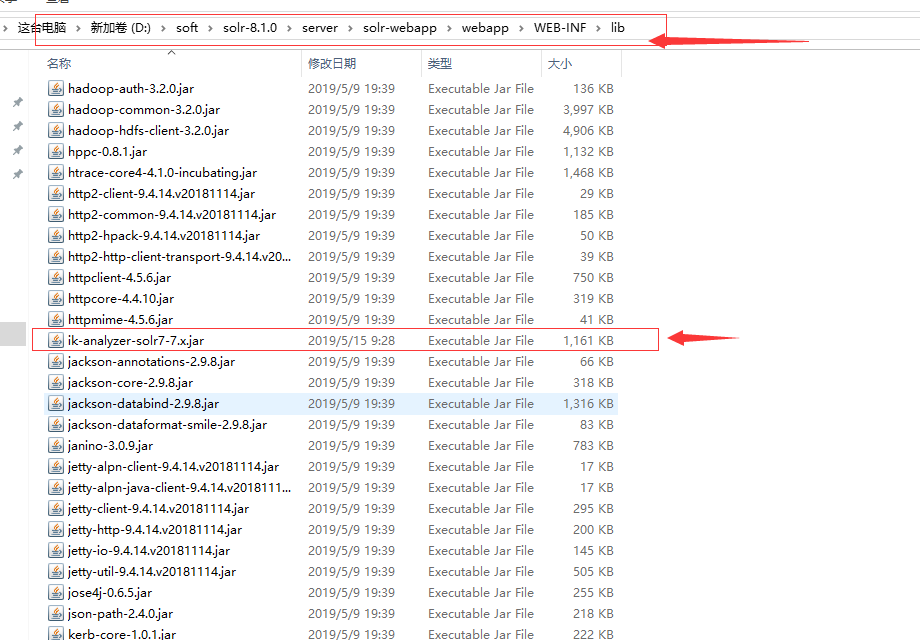
2.放到D:softsolr-8.1.0serversolr-webappwebappWEB-INFlib路径下
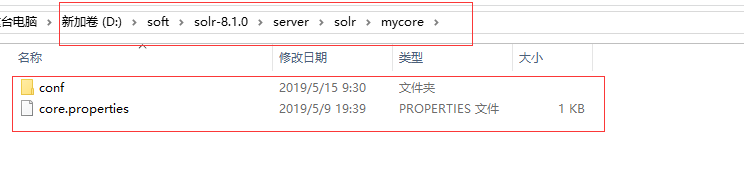
3.在路径D:softsolr-8.1.0serversolr下,新建一个mycore
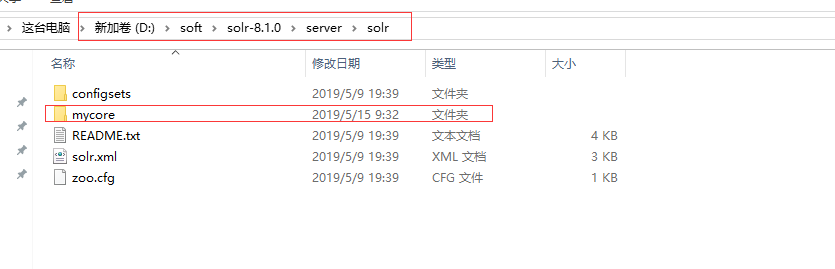
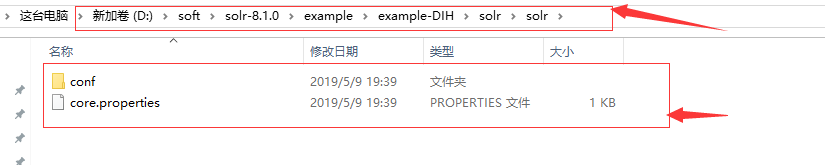
4. 复制 路径D:softsolr-8.1.0exampleexample-DIHsolrsolr下所有文件,放到D:softsolr-8.1.0serversolrmycore
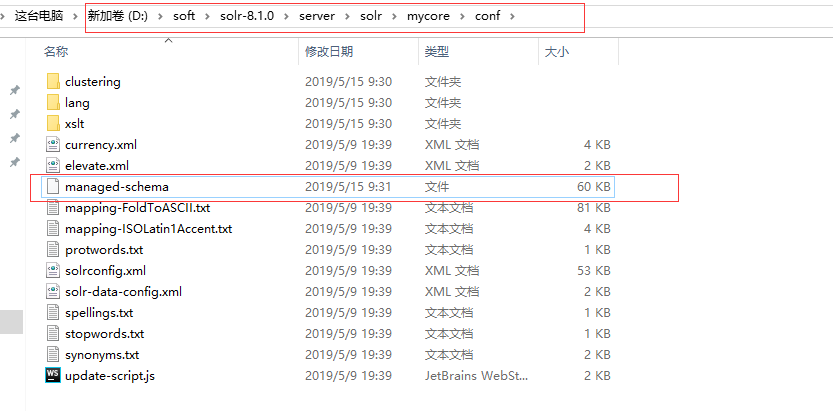
5.找到D:softsolr-8.1.0serversolrmycoreconf 路径下的managed-schema文件,打开,加入下面的代码
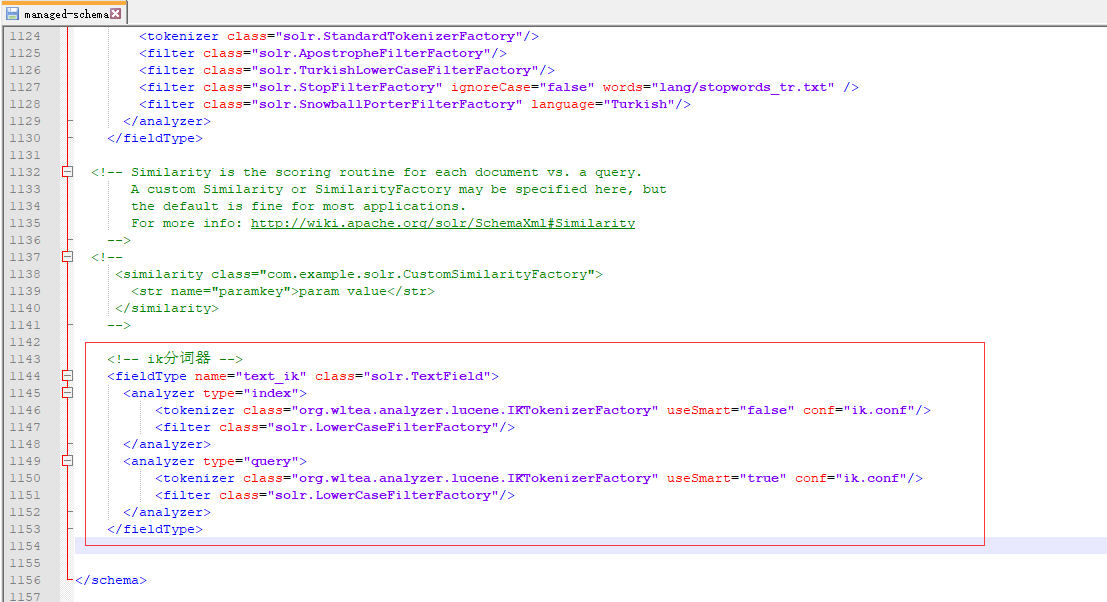
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>


7.自定义分词索引
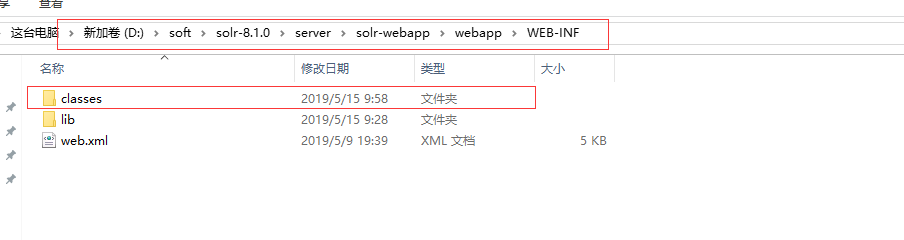
7.1 在路径D:softsolr-8.1.0serversolr-webappwebappWEB-INF下,新建classes文件。
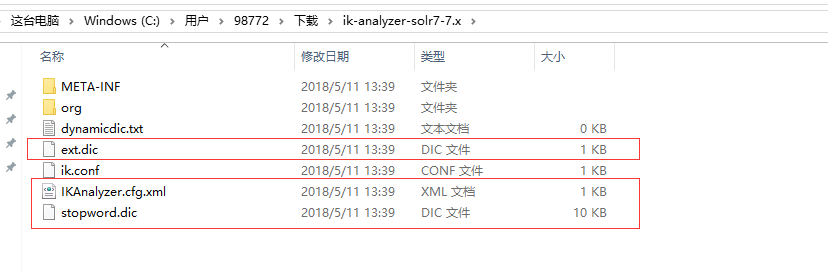
7.2 解压 ik-analyzer-solr7-7.x.jar ,复制 ext.dic,IKAnalyzer.cfg.xml,stopword.dic 这三个文件。
7.3 将上面复制的三个文件放到classes里。

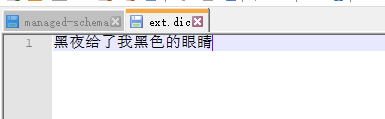
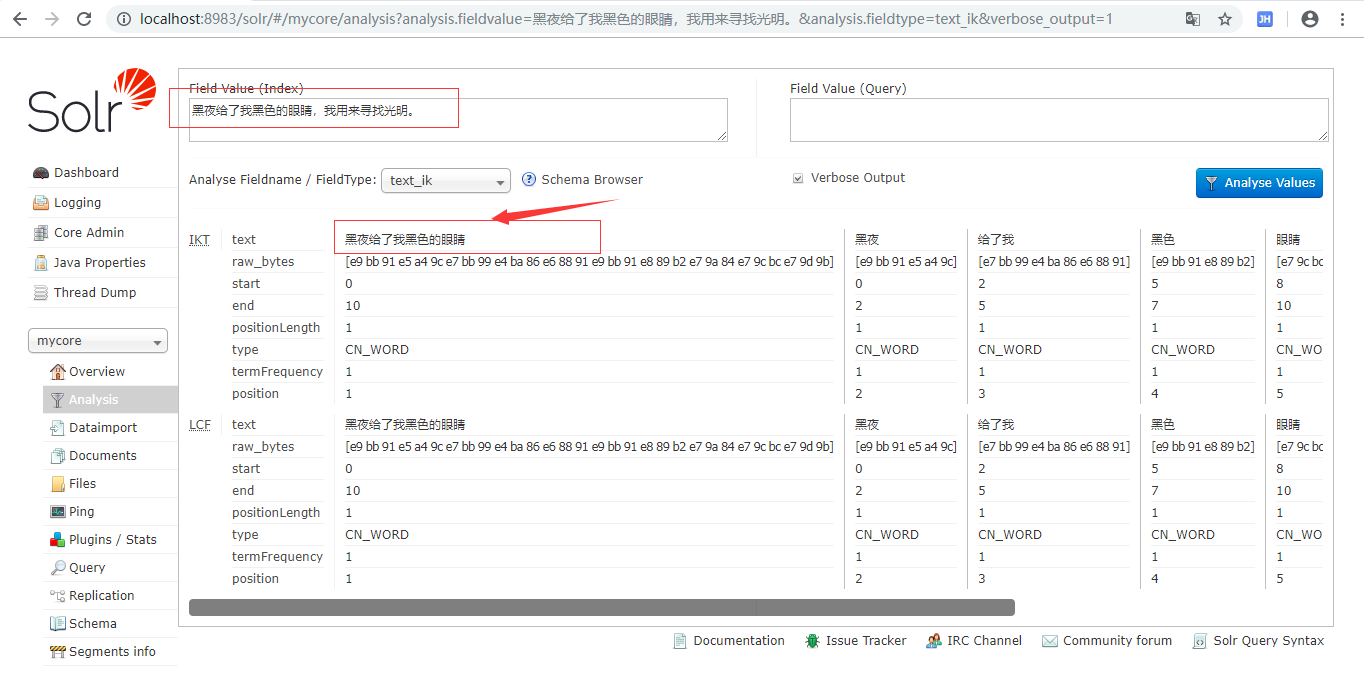
8.对比测试 在ext.dic文件里加上一个索引: 黑夜给了我黑色的眼睛,