一、背景介绍
在看spring源码和dubbo源码的时候,发现两者都用采用了JDK中spi的技术,发现都有大作用,所以就来分析下JDK中的SPI的使用方式及源码实现。
二、什么是SPI
SPI的全称是 Service Provider Interface。 一种从特定路径下,将实现了某些特定接口的类加载到内存中的方式(为什么会如此说,请看后面分析)。提供了另外一种方式加载实现类,也降低了代码的耦合程度,提升了代码的可扩展性。
实现SPI的地方主要有以下3处。主要的类和方法分别是:
- JDK
- java.util.ServiceLoader#load
- Spring
- org.springframework.core.io.support.SpringFactoriesLoader#loadFactories
- Dubbo
- org.apache.dubbo.common.extension.ExtensionLoader#
三、举例说明JDK SPI的使用方式
1. 自定义实现类, 实现数据库驱动 Driver.class


package com.fattyca1.driver; import java.sql.*; import java.util.Properties; import java.util.logging.Logger; /** * <br>自定义数据库操作</br> * * @author fattyca1 */ public abstract class CustomziedDriver implements Driver { public Connection connect(String url, Properties info) throws SQLException { return null; } public boolean acceptsURL(String url) throws SQLException { return false; } public DriverPropertyInfo[] getPropertyInfo(String url, Properties info) throws SQLException { return new DriverPropertyInfo[0]; } public int getMajorVersion() { return 0; } public int getMinorVersion() { return 0; } public boolean jdbcCompliant() { return false; } public Logger getParentLogger() throws SQLFeatureNotSupportedException { return null; } // 自定义方法 protected abstract void outDbName(); }
/** * <br>自定义实现数据库驱动</br> * * @author fattyca1 */ public class Fattyca1Driver extends CustomziedDriver { @Override public void outDbName() { System.out.println("fattyca1 db driver init ... "); } }
2. 在resources下创建META-INF/services文件夹,并在目录中创建文件。文件名称为实现接口名称,文件中内容为接口实现类。
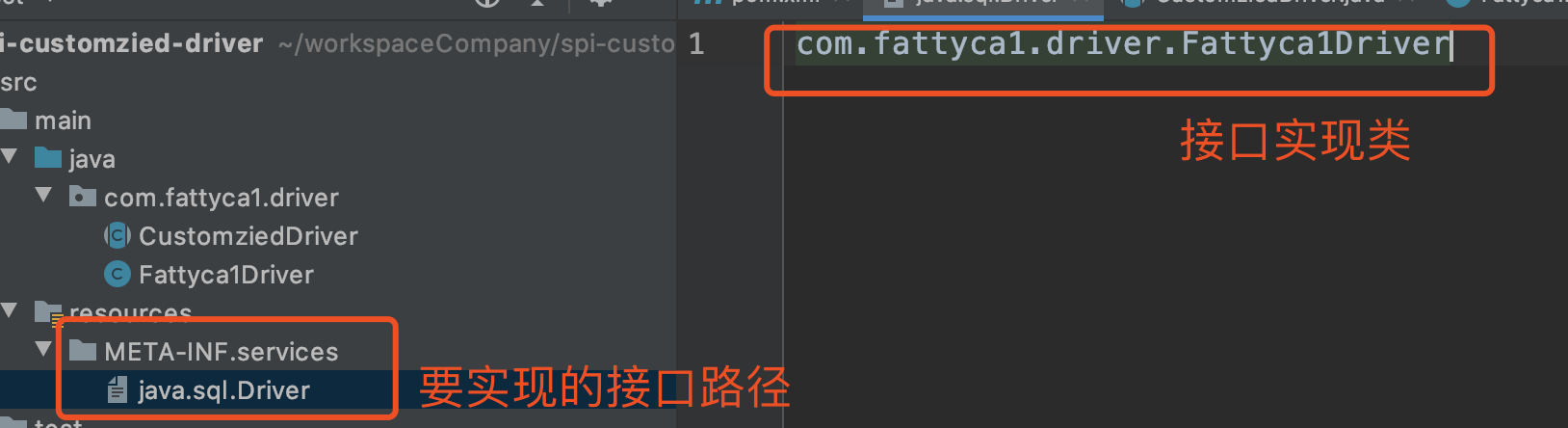
3. 建立一个main程序来测试结果
package com.lfc.demo.spi; import com.fattyca1.driver.Fattyca1Driver; import java.sql.Driver; import java.util.ServiceLoader; /** * <br>spi 测试客户端</br> * * @author fattyca1 */ public class SPIClient { public static void main(String[] args) { ServiceLoader<Driver> drivers = ServiceLoader.load(Driver.class); for (Driver driver : drivers) { if(driver instanceof Fattyca1Driver) { ((Fattyca1Driver) driver).outDbName(); } } } }
4. 实验结果。如下图:
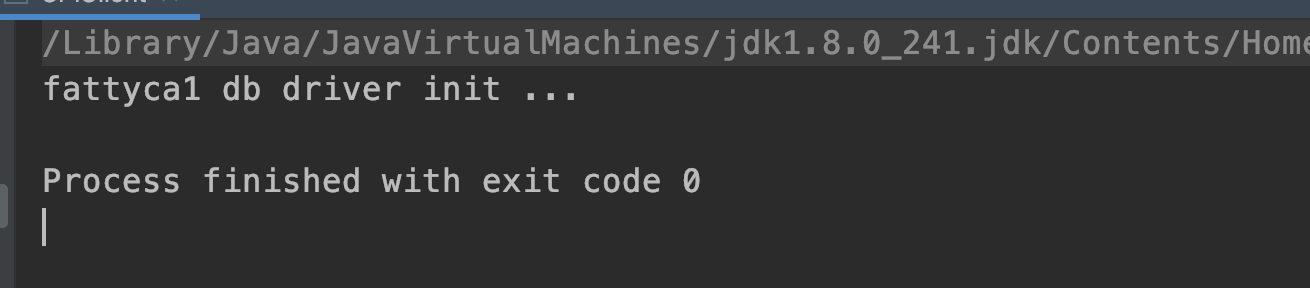
以上方式就是JDK中的SPI的实现方式,通过此方法,我们实现了自定义的Driver,可以使用自己定义的方式连接数据库。
四、JDK中ServiceLoader的源码分析
通过看上面例子, 大概了解到如果使用JDK中的SPI的实现方式,但是我们还不知道JDK是如何操作的。 接下来,我们就分析分析JDK的实现方式。
1. 从构造函数入口,发现其构造方法是私有,无法被外部初始化,所以我们直接从提供的静态方法入手
// ServiceLoader的构造函数
private ServiceLoader(Class<S> svc, ClassLoader cl) { ... }
2. 我们从ServiceLoader#load方法开始,一步步点进去,发现其最后调用的私有构造方法,构造中的核心方法是reload()。
private ServiceLoader(Class<S> svc, ClassLoader cl) { ... reload(); // 主要实现方法 }
3. 查看reload()方法的具体实现,发现并无多余代码,主要是清除了cacheMap, 实例化了lookupIterator,。
public void reload() { providers.clear(); // 清除缓存中的对象 lookupIterator = new LazyIterator(service, loader); // 初始化迭代器,此迭代器被调用时,才会加载类。 }
4.分析LazyIterator. 从名字可以看出,这是懒加载的类(命名清晰的好处)。此代码实现起来比较简单。 通过给定的class名称, 读取资源文件, 然后加载文件中的实现类。通过反射,生成实现类,放入cacheMap中。
private class LazyIterator implements Iterator<S> { Class<S> service; ClassLoader loader; Enumeration<URL> configs = null; Iterator<String> pending = null; String nextName = null; private LazyIterator(Class<S> service, ClassLoader loader) { this.service = service; this.loader = loader; } private boolean hasNextService() { if (nextName != null) { return true; } if (configs == null) { try { String fullName = PREFIX + service.getName(); if (loader == null) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); } catch (IOException x) { fail(service, "Error locating configuration files", x); } } while ((pending == null) || !pending.hasNext()) { if (!configs.hasMoreElements()) { return false; } pending = parse(service, configs.nextElement()); } nextName = pending.next(); return true; } private S nextService() { if (!hasNextService()) throw new NoSuchElementException(); String cn = nextName; nextName = null; Class<?> c = null; try { c = Class.forName(cn, false, loader); } catch (ClassNotFoundException x) { fail(service, "Provider " + cn + " not found"); } if (!service.isAssignableFrom(c)) { fail(service, "Provider " + cn + " not a subtype"); } try { S p = service.cast(c.newInstance()); providers.put(cn, p); return p; } catch (Throwable x) { fail(service, "Provider " + cn + " could not be instantiated", x); } throw new Error(); // This cannot happen } public boolean hasNext() { if (acc == null) { return hasNextService(); } else { PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() { public Boolean run() { return hasNextService(); } }; return AccessController.doPrivileged(action, acc); } } public S next() { if (acc == null) { return nextService(); } else { PrivilegedAction<S> action = new PrivilegedAction<S>() { public S run() { return nextService(); } }; return AccessController.doPrivileged(action, acc); } } public void remove() { throw new UnsupportedOperationException(); } }
五、SPI使用场景
- jdk中数据库驱动的加载
- spring中各种组件的插拔
- dubbo中自定义rpc协议,序列化方式,过滤器等
六、总结
至此,我们分析完JDK源码中的SPI的实现(代码实现简单,没有很仔细),发现实现简单,功能d强大,大家是否学习到了呢? 我们在自己实现代码的时候,可以多考虑学习此方式,也可以给代码松耦合,提升自己的代码质量。spring和dubbo中的源码和JDK中的源码都十分相似,实现起来大同小异,大家有时间可以自己比较比较。