一、元组
1、什么是元组?
元组是一个固定长度,不可改变的Python序列对象。创建元组的最简单方式,是用逗号分隔一列值:
In [1]: tup = 4, 5, 6 In [2]: tup Out[2]: (4, 5, 6)
当用复杂的表达式定义元组,最好将值放到圆括号内,如下所示:
In [3]: nested_tup = (4, 5, 6), (7, 8) In [4]: nested_tup Out[4]: ((4, 5, 6), (7, 8))
2、拆分元组
将元组赋值给类似元组的变量,Python会试图拆分等号右边的值,即使含有元组的元组也会被拆分:
In [23]: tup = 3,5,(8,9) In [24]: a,b,(c,d) = tup In [25]: c Out[25]: 8
替换变量的名字:
In [26]: a,b = 1,2 In [27]: a Out[27]: 1 In [28]: a,b = b,a In [29]: a Out[29]: 2
变量拆分常用来迭代元组或列表序列:
In [21]: seq = [(1,2,3),(4,5,6),(7,8,9)] In [22]: for a,b,c in seq: ...: print('a={0},b={1},c={2}'.format(a,b,c)) ...: a=1,b=2,c=3 a=4,b=5,c=6 a=7,b=8,c=9
从元组的开头“摘取”几个元素。它使用了特殊的语法*rest,这也用在函数签名中以抓取任意长度列表的位置参数:
In [35]: values = 1,2,3,4,5 In [36]: a,b,*rest = values In [37]: a,b Out[37]: (1, 2) In [38]: rest Out[38]: [3, 4, 5]
rest的部分是想要舍弃的部分,rest的名字不重要,可以取任意名字。
3、tuple方法
因为元组的大小和内容不能修改,它的实例方法都很轻量。其中一个很有用的就是count(也适用于列表),它可以统计某个值得出现次数:
In [43]: tup = (2,3,6,1,4,7,9,3,2,4,2) In [44]: tup.count(2) Out[44]: 3
二、Numpy
numpy学习路线及知识点
1、numpy性能
基于NumPy的算法要比纯Python快10到100倍(甚至更快),并且使用的内存更少。
In [45]: import numpy as np In [46]: my_arr = np.arange(1000000) In [47]: my_list = list(range(1000000)) In [48]: %time for _ in range(10): my_arr2 = my_arr * 2 Wall time: 23.9 ms In [49]: %time for _ in range(10): my_list2 = [x * 2 for x in my_list] Wall time: 815 ms
2、ndarray:一种多维数组对象
NumPy最重要的一个特点就是其N维数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器。ndarray是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象)。
注:当你在本书中看到“数组”、“NumPy数组”、"ndarray"时,基本上都指的是同一样东西,即ndarray对象。
2.1、创建ndarry
(1)使用array函数
In [57]: data1 = [4,5,6,7,9,8] In [58]: data1 = [4,5.3,6,7,9,8] In [59]: arr1 = np.array(data1) In [60]: arr1 Out[60]: array([4. , 5.3, 6. , 7. , 9. , 8. ])
(2)嵌套序列
In [61]: data2 = [[1,3,4,5],[6,7,8,9]] In [62]: arr2 = np.array(data2) In [63]: arr2 Out[63]: array([[1, 3, 4, 5], [6, 7, 8, 9]])
np.array会尝试为新建的这个数组推断出一个较为合适的数据类型。数据类型保存在一个特殊的dtype对象中。
比如说,在上面的两个例子中,我们有:
In [65]: arr1.dtype Out[65]: dtype('float64') In [66]: arr2.dtype Out[66]: dtype('int32')
(3)zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组。要用这些方法创建多维数组,只需传入一个表示形状的元组即可。
(4)arange是Python内置函数range的数组版。
下表为一些数组创建函数,如果没有特别指定,数据类型基本都是float64(浮点数)。
 表2-1-1 数组创建函数
表2-1-1 数组创建函数
2.2、Numpy的数据类型dtype
(1)下表NumPy所支持的全部数据类型:
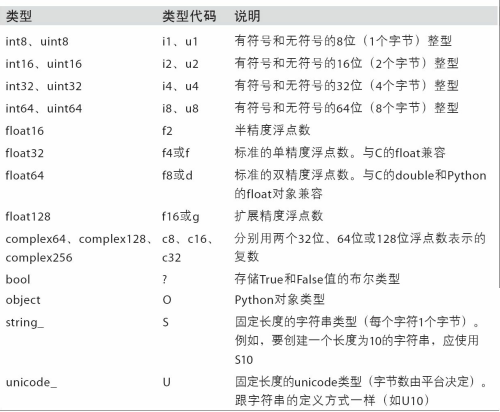
表2-1-1 Numpy支持的数据类型
(2)数据类型的相互转换
In [5]: arr = np.array([2,3,5,6,1]) In [6]: arr.dtype Out[6]: dtype('int32')
In [7]: float_arr = arr.astype(np.float64) In [8]: float_arr.dtype Out[8]: dtype('float64')
In [13]: arr = np.array([2.3 ,5.6 ,5.1 ,7.8]) In [14]: arr Out[14]: array([2.3, 5.6, 5.1, 7.8]) In [15]: arr.astype(np.int32) Out[15]: array([2, 5, 5, 7])
2.3、Numpy数组的运算
不用编写循环即可对数据执行批量运算,称其为矢量化(vectorization)。大小相等的数组之间的任何算术运算都会将运算应用到元素级:
(1)数组与标量的算术运算会将标量值传播到各个元素;
(2)大小相同的数组之间的比较会生成布尔值数组:
In [21]: arr1 = np.array([[1,2,3],[8,4,9]]) In [22]: arr2 = np.array([[6,2,1],[5,8,7]]) In [23]: arr2 > arr1 Out[23]: array([[ True, False, False], [False, True, False]])
2.4、基本的索引和切片
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。
切片[ : ]会给数组中的所有值赋值,“只有冒号”表示选取整个轴,因此你可以像下面这样只对高维轴进行切片。
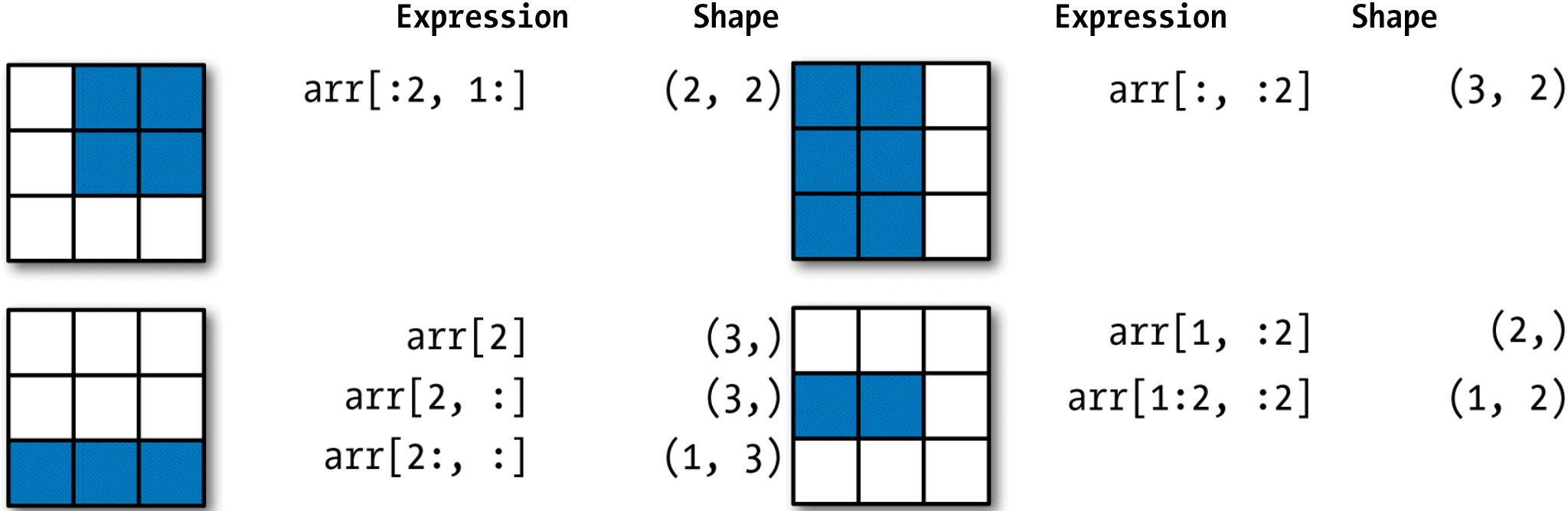
图2-4-1 二维数组切片
2.5、布尔型索引
假设我们有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)。在这里,我将使用numpy.random中的randn函数生成一些正态分布的随机数据:
In [29]: names = np.array(['lf','hg','yc','lf']) #存储姓名的数组 In [30]: data = np.random.randn(4,4) #存储数据的数组 In [31]: names Out[31]: array(['lf', 'hg', 'yc', 'lf'], dtype='<U2') In [32]: data #标红的数据为对应‘lf’的行 Out[32]: array([[ 0.01043648, 0.44103911, 0.47307017, -0.24815588], [ 0.6013753 , 0.57293908, 0.94169844, -1.4131715 ], [ 0.1938855 , -0.78327988, -0.41211459, -1.17359429], [ 1.33697091, -0.60614391, 0.86125283, -0.66521007]]) In [33]: names == 'lf' #判断名字为‘lf’ Out[33]: array([ True, False, False, True]) In [34]: data[names == 'lf'] #从data中,得到名字对应‘lf’的数据 Out[34]: array([[ 0.01043648, 0.44103911, 0.47307017, -0.24815588], [ 1.33697091, -0.60614391, 0.86125283, -0.66521007]]) In [35]: data[~(names == 'lf')] #除"lf"以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定,得到除‘lf’的其余数据。 Out[35]: array([[ 0.6013753 , 0.57293908, 0.94169844, -1.4131715 ], [ 0.1938855 , -0.78327988, -0.41211459, -1.17359429]]) In [36]: data[names == 'lf', 2:] #也可以进行切片操作 Out[36]: array([[ 0.47307017, -0.24815588], [ 0.86125283, -0.66521007]])
data[(names == 'lf') & (names == 'yc')] #选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可。 Out[37]: array([], shape=(0, 4), dtype=float64) #注意:Python中,关键字 and 和 or 在布尔型数组中无效,必须使用 & 与 | 。 data[(names == 'lf') | (names == 'yc')] Out[38]: array([[ 0.01043648, 0.44103911, 0.47307017, -0.24815588], [ 0.1938855 , -0.78327988, -0.41211459, -1.17359429], [ 1.33697091, -0.60614391, 0.86125283, -0.66521007]])
通过布尔型数组设置值是一种经常用到的手段。我们只需要将满足我们所需条件的行,设置为所需的值即可。
2.6、花式索引
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索引。
In [47]: arr = np.arange(63).reshape(9,7) #reshape():数组重塑 In [48]: arr Out[48]: array([[ 0, 1, 2, 3, 4, 5, 6], [ 7, 8, 9, 10, 11, 12, 13], [14, 15, 16, 17, 18, 19, 20], [21, 22, 23, 24, 25, 26, 27], [28, 29, 30, 31, 32, 33, 34], [35, 36, 37, 38, 39, 40, 41], [42, 43, 44, 45, 46, 47, 48], [49, 50, 51, 52, 53, 54, 55], [56, 57, 58, 59, 60, 61, 62]]) In [49]: arr[[1, 5, 7, 2], [0, 3, 1, 2]] #最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2)。无论数组是多少维的,花式索引总是一维的。 Out[49]: array([ 7, 38, 50, 16])
注:向数组的实例方法reshape传入一个表示新形状的元组即可实现将数组从一个形状转换为另一个形状,称为“数组重塑”。
将一维数组转换为多维数组的运算过程相反的运算通常称为扁平化(flattening)或散开(raveling)。
得到矩形区域的结果:
In [50]: arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]] Out[50]: array([[ 7, 10, 8, 9], [35, 38, 36, 37], [49, 52, 50, 51], [14, 17, 15, 16]])
花式索引跟切片不一样,它总是将数据复制到新数组中。
2.7、数组转置和轴对换
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性:
(1)二维数组
In [52]: arr = np.arange(15).reshape(5,3) In [53]: arr Out[53]: array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11], [12, 13, 14]]) In [54]: arr.T #使用T,实现数组转置 ,简单的转置可以使用.T,它其实就是进行轴对换而已。 Out[54]: array([[ 0, 3, 6, 9, 12], [ 1, 4, 7, 10, 13], [ 2, 5, 8, 11, 14]])
In [55]: np.dot(arr.T,arr) #使用np.dot()计算矩阵内积 Out[55]: array([[270, 300, 330], [300, 335, 370], [330, 370, 410]])
(2)高维数组
transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置:
In [56]: arr = np.arange(16).reshape(2,2,4) In [57]: arr Out[57]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7]], [[ 8, 9, 10, 11], [12, 13, 14, 15]]]) In [58]: arr.transpose((1,0,2)) #第一个轴被换成了第二个,第二个轴被换成了第一个,最后一个轴不变 Out[58]: array([[[ 0, 1, 2, 3], [ 8, 9, 10, 11]], [[ 4, 5, 6, 7], [12, 13, 14, 15]]]) In [60]: arr.transpose((2,0,1)) Out[60]: array([[[ 0, 4], [ 8, 12]], [[ 1, 5], [ 9, 13]], [[ 2, 6], [10, 14]], [[ 3, 7], [11, 15]]])
另:swapaxes也是返回源数据的视图(不会进行任何复制操作)。
3、通用函数:快速的元素级数组函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
如:一元函数(sqrt 和 exp),二元函数(add 和 maximum)等。
有的函数可以返回多个数组,如:modf ,它是Python内置函数divmod的矢量化版本,它会返回浮点数数组的小数和整数部分:
In [17]: arr = np.random.randn(5)*10 In [18]: arr Out[18]: array([ -3.21933715, -10.36535038, -10.67542382, -8.46654835, -9.11858314]) In [19]: xiaoshu ,zhengshu = np.modf(arr) In [20]: xiaoshu Out[20]: array([-0.21933715, -0.36535038, -0.67542382, -0.46654835, -0.11858314]) #使用函数 modf 返回的小数部分 In [21]: zhengshu Out[21]: array([ -3., -10., -10., -8., -9.]) #使用函数 modf 返回的整数部分
下表为一些常用一元函数:
 表3-1 一元函数
表3-1 一元函数

表3-2 二元函数
4、利用数组进行数据处理
4.1 简单的数据处理及数据可视化
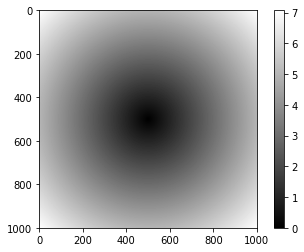
In [24]: arr1 = np.arange(-5,5,0.01) In [25]: x , y = np.meshgrid(arr1 ,arr1) #np.meshgrid函数接受两个一维数组,并产生两个二维矩阵 In [26]: y Out[26]: array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ], [-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99], [-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98], ..., [ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97], [ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98], [ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]]) In [27]: x Out[27]: array([[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99], [-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99], [-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99], ..., [-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99], [-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99], [-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99]]) In [28]: z = np.sqrt(x **2 + y**2) In [29]: z Out[29]: array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985, 7.06400028], [7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815, 7.05692568], [7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354, 7.04985815], ..., [7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603, 7.04279774], [7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354, 7.04985815], [7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815, 7.05692568]]) In [30]: import matplotlib.pyplot as plt #用 matplotlib 创建了这个二维数组的可视化 In [31]: plt.imshow(z, cmap=plt.cm.gray);plt.colorbar() #下图用 matplotlib 的 imshow 函数创建的 Out[31]: <matplotlib.colorbar.Colorbar at 0x1e3ca4c6e10>
4.2 将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本。
In [36]: x = np.random.randn(4) In [37]: y = np.random.randn(4) In [38]: x Out[38]: array([ 1.48118742, -1.96970611, 2.25096645, -0.54246986]) In [39]: y Out[39]: array([-1.02410078, -0.11525904, -3.04483051, 0.39291614]) In [40]: c = ([True,False,False,True]) In [41]: result = np.where(c , x, y) #np.where()当c中条件满足,取x;否则,取y。 In [42]: result Out[42]: array([ 1.48118742, -0.11525904, -3.04483051, -0.54246986])
np.where的第二个和第三个参数不必是数组,它们都可以是标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组。
In [45]: arr = np.random.randn(3,3) In [46]: arr Out[46]: array([[ 0.2914581 , -1.36593999, -0.31432138], [-0.93846987, -0.20832555, 0.89131944], [-0.61511922, 0.92639632, 0.70555075]]) In [47]: np.where(arr<0 , '负数' , '非负数') #使用np.where(),将<0的数替换为“负数”,否则替换为“非负数” Out[47]: array([['非负数', '负数', '负数'], ['负数', '负数', '非负数'], ['负数', '非负数', '非负数']], dtype='<U3')
使用np.where,可以将标量和数组结合起来。
In [48]: arr = np.random.randn(3,3) In [49]: arr Out[49]: array([[-1.64514297, -0.75800804, 2.75419085], [-2.10894613, 0.88960921, 0.61008557], [-0.35183569, -0.76112232, -0.88589693]]) In [50]: np.where(arr<0 , 0 ,arr) #利用np.where()将数组中小于0的,替换成0 Out[50]: array([[0. , 0. , 2.75419085], [0. , 0.88960921, 0.61008557], [0. , 0. , 0. ]])
4.3 数学和统计
sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction))既可以当做数组的实例方法调用,也可以当做顶级NumPy函数使用。
arr.mean() 和 np.mean(arr)是相同的,mean和sum这类的函数可以接受一个axis选项参数,用于计算该轴向上的统计值,最终结果是一个少一维的数组。
其他,在多维数组中,累加函数(如cumsum)返回的是同样大小的数组,但是会根据每个低维的切片沿着标记轴计算部分聚类:
In [57]: arr = np.arange(9).reshape(3,3) #将0-8,依次放入3x3的数组 In [58]: arr Out[58]: array([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) In [59]: arr.cumsum(axis=0) #当axis=0时,cumsum表示,x轴累加 Out[59]: array([[ 0, 1, 2], [ 3, 5, 7], [ 9, 12, 15]], dtype=int32) In [60]: arr.cumprod(axis=1) #当axis=1时,cumprod表示,y轴累积 Out[60]: array([[ 0, 0, 0], [ 3, 12, 60], [ 6, 42, 336]], dtype=int32) In [61]: arr.cumsum(axis=1) #当axis=1时,cumsum表示,y轴累加 Out[61]: array([[ 0, 1, 3], [ 3, 7, 12], [ 6, 13, 21]], dtype=int32)
 表4.3 基本数组统计方法
表4.3 基本数组统计方法
4.4 用于布尔型数组的方法
any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True:
In [62]: bools = np.array([True,False,False,False]) In [63]: bools.any() Out[63]: True In [64]: bools.all() Out[64]: False
4.5 排序
NumPy数组也可以通过sort方法就地排序,多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可。计算数组分位数最简单的办法是对其进行排序,然后选取特定位置的值。
4.6 唯一化,集合逻辑
(1)np.unique():用于找出数组中的唯一值并返回已排序的结果。
In [65]: arr = np.array([3,4,7,3,5,2,2,3]) In [66]: np.unique(arr) Out[66]: array([2, 3, 4, 5, 7])
(2)np.in1d():测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组。
arr = np.array([3,4,7,3,5,2,2,3]) np.in1d(arr , [1,2,5]) Out[68]: array([False, False, False, False, True, True, True, False])
 表4.6 数组的集合运算
表4.6 数组的集合运算
5、数组的文件输入输出
NumPy能够读写磁盘上的文本数据或二进制数据。
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的。如果文件路径末尾没有扩展名.npy,则该扩展名会被自动加上。然后就可以通过np.load读取磁盘上的数组。
In [69]: arr = np.arange(10) In [70]: np.save('test_arry',arr) #np.save(),写入文件 In [71]: np.load('test_arry.npy') #np.load(),读取文件 Out[71]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [72]: np.savez('tttest_arry', a=arr , b=arr) #np.savez()可以将多个数组保存到一个未压缩文件中,将数组以关键字参数的形式传入。 In [73]: arch = np.load('tttest_arry.npz') #加载.npz文件时,你会得到一个类似字典的对象. In [74]: arch['a'] #就像读取字典 Out[74]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [75]: np.savez_compressed('array_savez_compressed', a=arr, b=arr) #使用numpy.savez_compressed,可以将数据压缩。
6、线性代数
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是任何数组库的重要组成部分。NumPy提供了一个用于矩阵乘法的dot函数(既是一个数组方法也是numpy命名空间中的一个函数),x.dot(y)等价于np.dot(x, y)。
一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组。
@符也可以用作中缀运算符,进行矩阵乘法,如:x @ np.ones(3) 。
numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西。
In [1]: import numpy as np In [2]: from numpy.linalg import inv, qr In [3]: x = np.random.randn(5,5) In [4]: mat = x.T.dot(x) In [5]: inv(mat) Out[5]: array([[10.74988502, -5.23823973, 3.4098932 , -4.01219508, 11.97285628], [-5.23823973, 2.79246653, -1.69907634, 2.17129017, -5.93229317], [ 3.4098932 , -1.69907634, 1.1877896 , -1.29521734, 3.83419893], [-4.01219508, 2.17129017, -1.29521734, 2.4106194 , -4.61201453], [11.97285628, -5.93229317, 3.83419893, -4.61201453, 13.47415598]]) In [6]: mat.dot(inv(mat)) Out[6]: array([[ 1.00000000e+00, 9.29519278e-15, 1.95410401e-15, -4.41590319e-15, 4.61147788e-15], [ 7.07066551e-16, 1.00000000e+00, -5.47843147e-16, 2.15026418e-15, -7.95052824e-15], [ 1.27735688e-15, -2.93361528e-15, 1.00000000e+00, -2.73367886e-15, 3.56280748e-15], [ 6.28103643e-16, -3.18294121e-16, 9.84088913e-17, 1.00000000e+00, 3.07491619e-16], [-1.08920071e-14, -2.31928826e-15, -3.79022227e-16, -1.56267753e-15, 1.00000000e+00]]) In [7]: q ,r = qr(mat) In [8]: r Out[8]: array([[-13.96664998, 3.71421781, -1.18244965, 1.19323932, 14.84179656], [ 0. , -6.67361393, -2.02000028, 1.34310676, -1.91257227], [ 0. , 0. , -10.59251334, 0.28032169, 3.12315558], [ 0. , 0. , 0. , -1.20613986, -0.42373857], [ 0. , 0. , 0. , 0. , 0.0502477 ]])
 表6.1 常用的numpy.linalg函数
表6.1 常用的numpy.linalg函数
7、伪随机数生成
numpy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。
In [1]: import numpy as np In [2]: samples = np.random.normal(size=(4,4)) #np.random.normal()得到一个标准正态分布的数组 In [3]: samples Out[3]: array([[ 1.6148936 , -1.08305526, 0.23173604, 0.95963586], [ 2.47264752, 0.95717801, 0.58122765, 0.10627349], [-0.66822577, -1.54174138, 2.06643621, -0.76198218], [-0.92518965, -1.57405853, -0.21520583, 0.2834875 ]])
Python内置的random模块则只能一次生成一个样本值。如果需要产生大量样本值,numpy.random快了不止一个数量级。
伪随机数,是因为它们都是通过算法基于随机数生成器种子,在确定性的条件下生成的。
可使用np.random.seed更改随机数生成种子,numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,你可以使用np.random.RandomState,创建一个与其它隔离的随机数生成器。
 表7.1 部分numpy.random函数
表7.1 部分numpy.random函数