代码:
统计出团队中文简介中词频
import jieba
txt=open("C:\Users\Administrator\Desktop\介绍.txt","r",encoding='utf-8').read()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(5):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))

画出词频分布图:
import numpy as np
import matplotlib.pyplot as plt
fracs = [5,4,4,4,4]
labels = 'xiwang', 'daima', 'biancheng','meiyou','xingqu'
explode = [ 0.1,0,0,0,0]
plt.axes(aspect=1)
plt.pie(x=fracs, labels=labels, explode=explode,autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle = 90,pctdistance = 0.6)
plt.show()
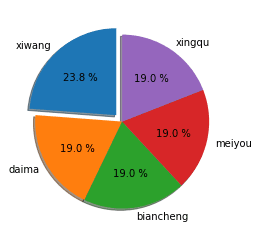
简介用词特点:能体现队员的特点,让大家更加充分了解每一个队员的兴趣,能力,以及想要负责的工作,更好地为团队做出贡献。