转载请注明源出处:http://www.cnblogs.com/lighten/p/7074488.html
1.前言
按照字节流的顺序一样,字符流也提供了缓冲字符流,与字节流不同,Java虽然提供了FilterReader和FilterWriter类,但是缓冲字符流没有继承者两个类,而是直接继承了Reader和Writer类。
2.BufferedReader

构造函数接受一个Reader和一个缓冲字符数量,默认8192。

read方法不但使用了同步锁,还采取了for(;;)形式。nextChar是要读取的字符位置下标,nChars是当前缓存中字符数量。很显然,要读取的字符下标大于等于当前存在的字符,意味着缓存中的字符已经被读取完了,需要重新获取写入缓存。这个就是fill()方法。fill()之后还是没有,就意味着读取完了,返回-1。skipLF是否跳过换号符,默认false。然后就是返回位置为nextChar的cb字符数组的字符,自增1。

fill()方法需要考虑到mark方法产生的标记,有标记和无标记的情况是不同的,无标记的时候肯定就是buffer被使用完了,从0开始重新填数据。也就是最后一段了。有标记的时候就不能舍弃标记的数据了,所有需要计算dst的值,由于存在readAheanLimit参数所以mark的计算又有区别。这个参数的意思是重置标记的时候,之前读取过的数据最多出现多少。因此,fill方法计算了标记位到已读取完的长度,如果大于这个限制,这就是一个无效的标记(标记在1号位,读完到5号位,但只能出现两个历史字符readAheanLimit,这样标记位就没有用了,因为不能删除后面多余的字符吧,所以是一个无效标记)。有效标记又分为两种情况,一种是readAheanLimit小于当前缓存大小,这个就不要紧,拷贝从标记为开始的数据就可以了。标记为置为0,新数据要从delta开始写了。如果大于缓存,肯定就是重新创建缓存了。

read字符数组的方法也是一个常见的处理过程了,先执行一次,如果都完了就直接返回了,如果没读完,且没有读到需要的数量就通过while循环不断读,读完了流就直接break,或者读到所需的len长度。
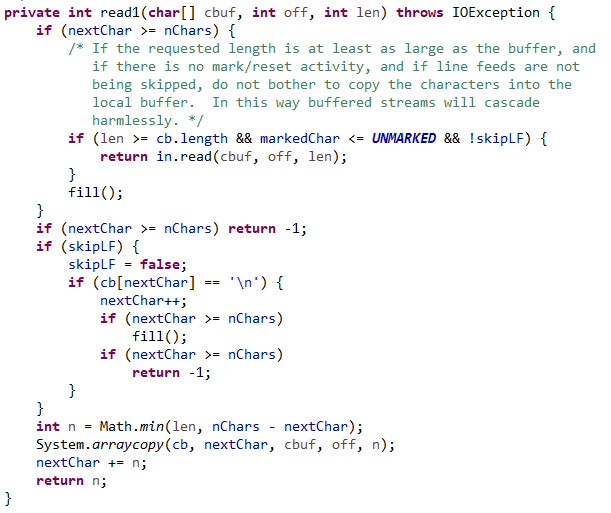
如果没有可读的缓存了当然要重新fill,但是这里也有一种情况,就是所要的长度超过缓存大小,这个时候就直接从原来的流中读取返回。重填了之后还是没有,就是读取完了,返回-1。后面就是把数据填充到给的字符数组了,可能缓冲区的数据不够,所以是选择了小的那个值,然后返回。
其它的方法没上面好讲的了。最后的一个lines方法,是JDK8才提供的,具体实现超过IO的范畴,作用是返回一个Stream<String>,里面就是所读取的流的一行行,懒加载的方式。
3.BufferedWriter
相比于BufferedReader,输出流BufferWriter较简单些。

一样接收一个Writer和缓存大小,默认也是8192个字符。

write方法,如果缓存写满了就刷入持有的writer。然后重置nextChar为0,写入当前的这个位置。
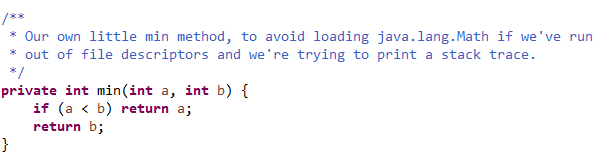
里面自己写了一个比较方法,而没有使用Math类的方法,理由上面也给了,使用完了文件描述符的时候,会尝试打印堆栈跟踪。
其它两个write方法都比较简单,思路一样,就不再继续介绍了。