用的是腾讯云学生机
系统是ubuntu18.04
安装anacondas
是从清华大学的镜像源里找到自己喜欢的版本
https://repo.anaconda.com/archive
使用wget来直接安装指定版本的anacondas
wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.sh
运行安装包的脚本文件
bash Anaconda3-5.3.1-Linux-x86_64.sh
按提示完成安装~
配置anacondas环境变量
打开配置文件
sudo vim ~/.bashrc
在最后一行中加入自己安装的anaconda下bin的路径
#set Anaconda3 environment
export PATH="/home/ubuntu/anaconda3/bin:$PATH"
使文件立即生效
source ~/.bashrc
配置jupyter
生成一个sha1加密的密文
vim generateSha.py
在里边写入
from notebook.auth import passwd
print(passwd('google'))
运行py文件得到一串sha1加密的密文,记下来
sha1:eb9b3623beca:60166d5389186cff356195341f2b92c77735caf8
python generateSha.py
查看jupyter配置文件的路径
jupyter notebook --generate-config
打开jupyter配置文件
vim /home/ubuntu/.jupyter/jupyter_notebook_config.py
加入以下内容
c.NotebookApp.ip = '*'
c.NotebookApp.port = 8888
c.NotebookApp.open_browser = False
c.NotebookApp.password = u'sha1:175857feb4bc:81edf72d2ad0f8f634dc8aa3ca8f195f2580219a'
意外:通常Xshell如果断开连接后需要重新使文件立即生效
source ~/.bashrc
创建一个jupyter-workplace的工作空间,用存放咋们的工程
mkdir jupyter-workplace
进入jupyter-workplace文件夹
cd jupyter-workplace
启动jupyter,让其在后台运行并输出日志到jupyter.log中
nohup jupyter notebook --allow-root > jupyter.log 2>&1 &
修改jupyter权限,否则会出现创建ipynb被拒绝的情况
sudo chmod 777 ~/.local/share/jupyter/
安装请求库
requests安装
(anacandas已有)
pip安装
pip install -i https://pypi.doubanio.com/simple/ requests
Selenium安装
pip install -i https://pypi.doubanio.com/simple/ Selenium
ChromeDriver安装
(嘤嘤嘤装不上,go die了)
假如你是国外的云服务器:下载指令,卧槽我忘了国内服务器访问不了谷歌平台。。嗨呀这条指令只适用海外的服务器
wget -O gdrive https://sites.google.com/site/wun913/Home/gdrive-linux-x64
假如你是国内的云服务器:
搭个梯子到这里下载以后,再用Xtfp啥的文件传输工具传到服务器吧。。
https://sites.google.com/site/wun913/Home/gdrive-linux-x64
root权限下:移动 gdrive 到 /usr/bin
mv gdrive-linux-x64 /usr/bin/gdrive
添加执行权限
chmod +x /usr/bin/gdrive
aiohttp安装
pip install -i https://pypi.doubanio.com/simple/ aiohttp
安装解析库
lxml安装
(忘了看anacondas有没有装了就报错了,好像是自带了0 0)
先安装必要的库
sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
再pip安装
pip install -i https://pypi.doubanio.com/simple/ lxml
Beautiful Soup安装
(anacondas自带了)
pip install -i https://pypi.doubanio.com/simple/ beautifulsoup4
pyquery安装
pip install -i https://pypi.doubanio.com/simple/ pyquery
tesserocr安装
安装各种版本的依赖
sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev
安装完以后可以用命令运行一下查看语言
tesseract --list-langs
他只支持几种语言,想要安装其他语言的话就得去为https://github.com/tesseract-ocr/tessdata下载
克隆到服务器上
git clone https://github.com/tesseract-ocr/tessdata.git
迁移到tesseract中
sudo mv tessdata/* /usr/share/tesseract-ocr/tessdata
再用pip安装
pip install -i https://pypi.doubanio.com/simple/ tesserocr
安装数据库
mysql安装
apt安装
sudo apt-get update
sudo apt-get install -y mysql-server mysql-client
MongoDB安装
apt安装
sudo apt install -y mongodb
使mongoDB在端口27017上运行,数据文件保存到/data/db路径下
mongod --port 27017 --dbpath /data/db
进入mongo数据库创建一个角色信息用于远程访问
进入mongo数据库
mongo --port 27017
创建一个数据库角色,名为moon,密码为123,权限为root,使用的数据库为admin
db.createUser({user:'moon',pwd:'123',roles:[{role:'root',db:'admin'}]})
查看mongo配置文件路径
ps -ax | grep mongod
修改mongo配置文件使得能够远程访问
sudo vi /etc/mongod.conf
net部分和security修改如下:
net:
port: 27017
bindip: 0.0.0.0
security:
authorization:enabled
重启mongoDB服务
sudo systemctl restart mongodb
其他相关指令
更新用户密码
use admin
db.changeUserPassword('tank2','test');
查看服务当前状态
sudo systemctl status mongodb
停止服务
sudo systemctl stop mongodb
启动服务
sudo systemctl restart mongodb
禁用自启动
sudo systemctl disable mongodb
开启自启动
sudo systemctl enable mongodb
Redis安装
apt安装
sudo apt-get -y install redis-server
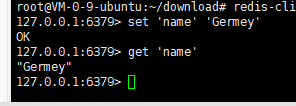
进入Redis命令行验证是否安装成功
进入Redis命令行
redis-cli
输入两条指令
set 'name' 'Germey'
get 'name'
这样就成功了,但是还没有办法远程连接,于是接着。。
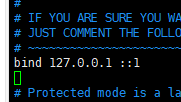
打开本地文件
vim /etc/redis/redis.conf
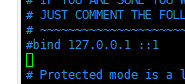
注释掉这一行
bind 127.0.0.1
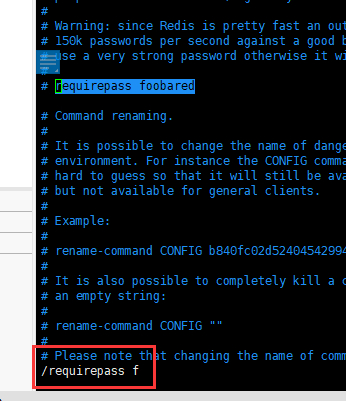
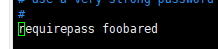
取消注释这一行
requirepass foobared
可以在vim搜索来找到这一行,foobared为当前密码,自行修改成自己想要的密码
之后重启Redis服务
sudo /etc/init.d/redis-server restart

其他指令
关闭Redis服务
sudo /etc/init.d/redis-server stop
开启Redis服务
sudo /etc/init.d/redis-server start
安装存储库
PyMySQL安装
pip install -i https://pypi.doubanio.com/simple/ pymysql
PyMongo安装
pip install -i https://pypi.doubanio.com/simple/ pymongo
Redis-py安装
pip install -i https://pypi.doubanio.com/simple/ redis
RedisDump安装
如果没有Ruby,先apt安装
sudo apt-get install ruby-full
再使用gem来安装RedisDump
gem install redis-dump
安装Web库
Flask安装
(已自带)
pip install -i https://pypi.doubanio.com/simple/ flask
Tornado安装
(已自带)
pip install -i https://pypi.doubanio.com/simple/ tornado
安装App爬取相关库
Charles安装
这个好像没必要装在服务器上,因为是图形化界面的
mitmproxy安装
方法一:
到https://github.com/mitmproxy/mitmproxy/releases/下载二进制包
用Xftp传到服务器后解压,
tar -zxvf mitmproxy-5.1.0.tar.gz
进入安装的根目录,将三个文件移动到/usr/bin
sudo mv mitmproxy mitmdump mitmweb /usr/bin
方法二:
先安装必要的库
sudo apt-get install openssl
sudo apt-get install libssl-dev
sudo apt-get install libc6-dev gcc
sudo apt-get install -y make build-essential zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm tk-dev
再用pip安装,一定要注意把--ignore-installed加上
pip install mitmproxy --ignore-installed
原文链接:https://blog.csdn.net/qq_39889867/article/details/83477480
Appium安装
ubuntu就是舒服。。只需要三条指令
先安装nodejs
sudo apt-get install nodejs
再安装npm
sudo apt-get install npm
最后用npm安装appium
npm install -g appium
npm --registry http://registry.cnpmjs.org install -g appium
安装爬虫框架
pyspider安装
pip install -i https://pypi.doubanio.com/simple/ pyspider
Scrapy安装
确保这些库已经安装
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
之后使用Pip安装
pip install Scrapy
Scrapy-Splash安装
通过docker来安装,安装好以后会自动启动服务运行,按ctrl+c退出
docker run -p 8050:8050 scrapinghub/splash
再加个参数-d使得Docker以守护态运行,这样的话它就一直在服务器上运行了
docker run -d -p 8050:8050 scrapinghub/splash
再用pip安装它的库
pip install scrapy-splash
Scrapy-Redis安装
pip install scrapy-redis
安装部署相关库
Docker安装
方法一:
curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -
curl -sSL https://get.daocloud.io/docker | sh
验证docker是否安装成功
docker run hello-world
方法二:
apt安装
sudo apt install docker.io
启动docker
systemctl start docker
验证docker是否安装成功
docker run hello-world
开机自启动
systemctl enable docker
修改默认配置文件,咋们换个下载源
sudo vim /etc/docker/daemon.json
加入以下内容,把源换成中科大的
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
重启一下docker
systemctl enable docker
systemctl start docker
Scrapyd安装
1.安装
首先pip安装
pip install scrapyd
找到配置文件
find / -name "default_scrapyd.conf"

2.配置文件
打开配置文件
vim /home/ubuntu/anaconda3/lib/python3.7/site-packages/scrapyd/default_scrapyd.conf
将bind_address = 127.0.0.1修改成bind_address = 0.0.0.0允许远程访问
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
3.启动服务
启动scrapyd服务
scrapyd
这时候可以看到
4.访问认证(nginx实现)
安装nginx
sudo apt install nginx
在nginx配置文件目录下,创建一个scrapyd配置文件,sites-enabled这个文件夹下后缀名有没有无所谓
vim /etc/nginx/sites-enabled/scrapyd
配置信息如下
server {
listen 6801;
location / {
proxy_pass http://127.0.0.1:6800/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
到/etc/nginx/conf.d创建一个用户名为moon的密码文件.htpasswd
cd /etc/nginx/conf.d
htpasswd -c .htpasswd moon
查看一下密码
cat .htpasswd
意外:假如还有没有htpasswd会找不到指令,得先安装一下
sudo apt install apache2-utils
重启nginx服务
sudo nginx -s reload
5.其他指令
按ctrl+c退出,执行指令让它在后台运行
setsid scrapyd
如果想停止他的进程可以查他的PID
ps -ef | grep -i scrapyd
结束它的生命
kill -9 PID
但是这样不方便,所以自己写脚本来管理它(不方便就方便了我配置不动了QAQ就是不行
在/etc/init.d下新建一个脚本文件
vim /etc/init.d/scrapyd
加入以下信息进行配置
#!/bin/bash
PORT=6800
#这里是你的scrapyd安装目录,在前面已经有过怎么查找到这个目录了
HOME="/home/ubuntu/anaconda3/lib/python3.7/site-packages/scrapyd"
#这里是通过python安装后,scrapyd的执行目录
BIN="/home/ubuntu/anaconda3/bin/scrapyd"
pid=`netstat -lnopt | grep :$PORT | awk '/python/{gsub(//python/,"",$7);print $7;}'`
start() {
if [ -n "$pid" ]; then
echo "server already start,pid:$pid"
return 0
fi
cd $HOME
nohup $BIN >> $HOME/scrapyd.log 2>&1 &
echo "start at port:$PORT"
}
stop() {
if [ -z "$pid" ]; then
echo "not find program on port:$PORT"
return 0
fi
#结束程序,使用讯号2,如果不行可以尝试讯号9强制结束
kill -9 $pid
echo "kill program use signal 9,pid:$pid"
}
status() {
if [ -z "$pid" ]; then
echo "not find program on port:$PORT"
else
echo "program is running,pid:$pid"
fi
}
case $1 in
start)
start
;;
stop)
stop
;;
status)
status
;;
*)
echo "Usage: {start|stop|status}"
;;
esac
exit 0
赋予可执行权限
chmod u+x scrapyd
测试
开启服务
service scrapyd start
查看状态
service scrapyd status
关闭状态
service scrapyd stop
Scrapyd-Client安装
pip安装
pip install scrapyd-client
验证安装是否成功
scrapyd-deploy -h
Scrapyd-API安装
pip安装
pip install python-scrapyd-api
验证安装是否成功
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://localhost:6800')
print(scrapyd.list_projects())
输出
Scrapyrt安装
pip安装
pip install scrapyrt
顺带记一下~启动scrapyrt服务
scrapyrt
Gerapy安装(么装上···
pip安装
pip install gerapy
呕了装了一天。。太难了把各种版本冲突,大部分是正常的了以后需要用的时候再装或者弄几个虚拟环境装来用吧。。
拓展:杀死后台进程和
查看进程号
ps -aux
查看进程占用的端口
netstat -atunp
include /etc/nginx/conf.d/*.conf
根据Pid杀死某个进程
kill pid
拓展:vim查找关键字
比如想找requirepass,先按一下ESC再输入/requirepass/,然后回车!
拓展:在linux下查找文件路径
find / -name "default_scrapyd.conf"