Elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/6.0/getting-started.html
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements.
document operation api
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/docs.html
This section starts with a short introduction to Elasticsearch’s data replication model, followed by a detailed description of the following CRUD APIs:
Single document APIs
Multi-document APIs
full text query api
https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html
The full text queries enable you to search analyzed text fields such as the body of an email. The query string is processed using the same analyzer that was applied to the field during indexing.
The queries in this group are:
intervalsquery- A full text query that allows fine-grained control of the ordering and proximity of matching terms.
matchquery- The standard query for performing full text queries, including fuzzy matching and phrase or proximity queries.
match_bool_prefixquery- Creates a
boolquery that matches each term as atermquery, except for the last term, which is matched as aprefixquerymatch_phrasequery- Like the
matchquery but used for matching exact phrases or word proximity matches.match_phrase_prefixquery- Like the
match_phrasequery, but does a wildcard search on the final word.multi_matchquery- The multi-field version of the
matchquery.commonterms query- A more specialized query which gives more preference to uncommon words.
query_stringquery- Supports the compact Lucene query string syntax, allowing you to specify AND|OR|NOT conditions and multi-field search within a single query string. For expert users only.
simple_query_stringquery- A simpler, more robust version of the
query_stringsyntax suitable for exposing directly to users.
Dev Tool
https://zhuanlan.zhihu.com/p/54384152
安装 Kibana
这是一个官方推出的把 Elasticsearch 数据可视化的工具,官网在这里:【传送门】,不过我们现在暂时还用不到那些数据分析的东西,不过里面有一个 Dev Tools 的工具可以方便的和 Elasticsearch 服务进行交互,去官网下载了最新版本的 Kibana(6.5.4) 结果不知道为什么总是启动不起来,所以换一了一个低版本的(6.2.2)正常,给个下载外链:下载点这里,你们也可以去官网试试能不能把最新的跑起来:
等待一段时间后就可以看到提示信息,运行在 5601 端口,我们访问地址
http://localhost:5601/app/kibana#/dev_tools/console?_g=()可以成功进入到 Dev-tools 界面:
点击 【Get to work】,然后在控制台输入
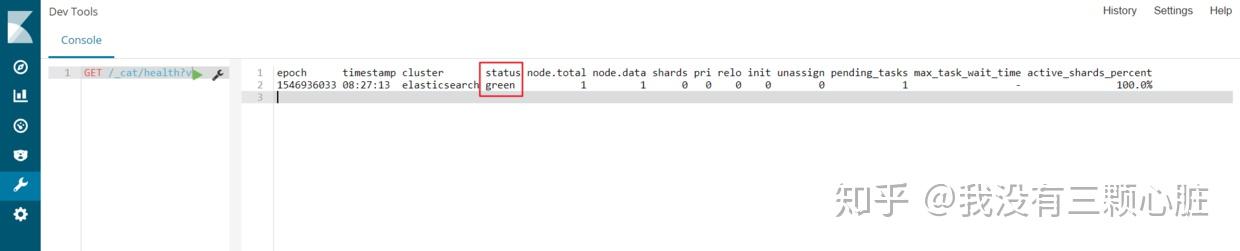
GET /_cat/health?v查看服务器状态,可以在右侧返回的结果中看到green即表示服务器状态目前是健康的:
安装
https://www.elastic.co/downloads/elasticsearch
https://www.elastic.co/guide/cn/kibana/current/targz.html
插件与分词工具
https://www.elastic.co/guide/en/elasticsearch/plugins/current/intro.html
Plugins are a way to enhance the core Elasticsearch functionality in a custom manner. They range from adding custom mapping types, custom analyzers, native scripts, custom discovery and more.
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-smartcn.html
The Smart Chinese Analysis plugin integrates Lucene’s Smart Chinese analysis module into elasticsearch.
It provides an analyzer for Chinese or mixed Chinese-English text. This analyzer uses probabilistic knowledge to find the optimal word segmentation for Simplified Chinese text. The text is first broken into sentences, then each sentence is segmented into words.
sudo bin/elasticsearch-plugin install analysis-smartcn
https://www.elastic.co/guide/en/elasticsearch/plugins/current/ingest-attachment.html
The ingest attachment plugin lets Elasticsearch extract file attachments in common formats (such as PPT, XLS, and PDF) by using the Apache text extraction library Tika.
You can use the ingest attachment plugin as a replacement for the mapper attachment plugin.
The source field must be a base64 encoded binary. If you do not want to incur the overhead of converting back and forth between base64, you can use the CBOR format instead of JSON and specify the field as a bytes array instead of a string representation. The processor will skip the base64 decoding then.
sudo bin/elasticsearch-plugin install ingest-attachment
TF/IDF
https://www.cnblogs.com/gongxijun/p/8673241.html
##TF-IDF
TF(词频): 假定存在一份有N个词的文件A,其中‘明星‘这个词出现的次数为T。那么 TF = T/N;
所以表示为: 某一个词在某一个文件中出现的频率.
TF-IDF(词频-逆向文件频率): 表示的词频和逆向文件频率的乘积.
比如: 假定存在一份有N个词的文件A,其中‘明星‘这个词出现的次数为T。那么 TF = T/N; 并且‘明星’这个词,在W份文件中出现,而总共有X份文件,那么
IDF = log(X/W) ;
而: TF-IDF = TF * IDF = T/N * log(X/W); 我们发现,‘明星’,这个出现在W份文件,W越小 TF-IDF越大,也就是这个词越有可能是该文档的关键字,而不是习惯词(类似于:‘的’,‘是’,‘不是’这些词),
而TF越大,说明这个词在文档中的信息量越大.
reference
http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
https://www.elastic.co/blog/a-practical-introduction-to-elasticsearch