Rock Paper Scissors
https://www.freecodecamp.org/learn/machine-learning-with-python/machine-learning-with-python-projects/rock-paper-scissors
简单的竞赛游戏, 使用算法,学习对手的规则,战胜对手。
For this challenge, you will create a program to play Rock, Paper, Scissors. A program that picks at random will usually win 50% of the time. To pass this challenge your program must play matches against four different bots, winning at least 60% of the games in each match.
You can access the full project description and starter code on repl.it.
马尔科夫链解法
https://forum.freecodecamp.org/t/cant-beat-abbey-rock-paper-scissors-project/447449/2
https://github.com/marius-mm/freeCodeCampProjects/blob/main/Machine%20Learning%20with%20Python/RockPaperScissors/RPS.py
作者生成四个对手中能打败3个,但是实际测试只能打败两个。以60%为标准。
import random import mchmm as mc import numpy as np winDict = {"R": "P", "S": "R", "P": "S"} strategy = 1 def player(prev_play, opponent_history=[]): global strategy # firstCall if len(opponent_history) <= 0: opponent_history.append("R") opponent_history.append("S") if len(prev_play) <= 0: prev_play = "P" # /firstCall opponent_history.append(prev_play) if strategy == 1: memory = 800 guess = predict(prev_play, opponent_history, memory) return guess def predict(prev_play, oppnent_history, memoryLength): if len(oppnent_history) > memoryLength: oppnent_history.pop(0) chain = mc.MarkovChain().from_data(oppnent_history) predictionNextItem = giveMostProbableNextItem(chain, prev_play) winningMove = winDict[predictionNextItem] return winningMove def contains_duplicates(X): X = np.round(X,4) return len(np.unique(X)) != len(X) def giveIndexOfState(chain, item): return np.where(chain.states == item)[0][0] def giveMostProbableNextItem(chain, lastItem): retval = chain.states[ np.argmax(chain.observed_p_matrix[giveIndexOfState(chain, lastItem)]) ] return retval
据介绍需要增加马尔科夫链的长度。
do you mean with chain length like different states? RS RR RP SR … instead of S R P ?
That’s exactly what I mean. That’s also what Abbey is doing, so you will have to use a longer chain than she does or use her chain against her to win.
https://forum.freecodecamp.org/t/rock-paper-scissors-help-with-abbey/452902
abbey使用的是长度为2的马尔科夫链, 作为对手需要使用不小于二的链去竞赛。
Abbey is a Markov chain player, using a length of 2, so you’ve got a good example there. A longer Markov chain can defeat her or an appropriate length 2 chain will work as well. As I have mentioned here before, it is possible to know who you are playing, through various means, and employ the correct algorithm against them. It’s possible to beat all the players more than 80% of the time. As you can see from reading Abbey’s code, a Markov chain algorithm isn’t very complex.
A Markov chain isn’t the only algorithm that will work here, but it is one of the simpler ones. This project is not current fashionable machine learning (think neural nets) but old school machine learning. There is quite a bit of information on RPS strategy on the web once you get past all the RPS bot tutorials that use neural nets to recognize human hands playing RPS.
mchmm 库
https://github.com/maximtrp/mchmm
Discrete Markov chains
Initializing a Markov chain using some data.
>>> import mchmm as mc >>> a = mc.MarkovChain().from_data('AABCABCBAAAACBCBACBABCABCBACBACBABABCBACBBCBBCBCBCBACBABABCBCBAAACABABCBBCBCBCBCBCBAABCBBCBCBCCCBABCBCBBABCBABCABCCABABCBABC')Now, we can look at the observed transition frequency matrix:
>>> a.observed_matrix array([[ 7., 18., 7.], [19., 5., 29.], [ 5., 30., 3.]])And the observed transition probability matrix:
>>> a.observed_p_matrix array([[0.21875 , 0.5625 , 0.21875 ], [0.35849057, 0.09433962, 0.54716981], [0.13157895, 0.78947368, 0.07894737]])You can visualize your Markov chain. First, build a directed graph with
graph_make()method ofMarkovChainobject. Thenrender()it.>>> graph = a.graph_make( format="png", graph_attr=[("rankdir", "LR")], node_attr=[("fontname", "Roboto bold"), ("fontsize", "20")], edge_attr=[("fontname", "Iosevka"), ("fontsize", "12")] ) >>> graph.render()Here is the result:

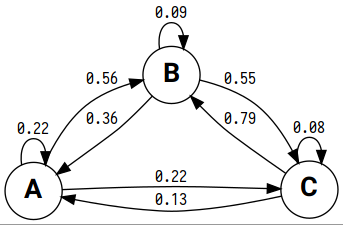
隐马尔科夫链方法
使用hmmlearn来学习观测序列, 获得隐藏的状态规律。
效果
运行结果如下。
从中可以看出,对于1 和 4 选手, 规律性出招的, 预测效果很好。
对于2 和 3 具有对抗性质的选手, 预测效果不好。
说明 hmm 是用于学习隐藏规律的。
--------- you vs quincy ----------
Final results: {'p1': 749, 'p2': 103, 'tie': 148}
Player 1 win rate: 87.91079812206573%
--------- you vs abbey ----------
Final results: {'p1': 331, 'p2': 392, 'tie': 277}
Player 1 win rate: 45.78146611341632%
--------- you vs kris ----------
Final results: {'p1': 455, 'p2': 398, 'tie': 147}
Player 1 win rate: 53.341148886283705%
--------- you vs mrugesh ----------
Final results: {'p1': 776, 'p2': 187, 'tie': 37}
Player 1 win rate: 80.5815160955348%
code
import random from hmmlearn import hmm import numpy as np import math states = ["0", "1", "2", "3", "4"] n_states = len(states) observations_dict = { 0: "R", 1: "P", 2: "S" } n_features = len(observations_dict) def player(prev_play, opponent_history=[], verbose=False): # print("call player") # print(prev_play) # print(len(opponent_history)) global n_states play_list = ["R", "P", "S"] win_dict = {"R": "P", "P": "S", "S": "R"} if prev_play in play_list: opponent_history.append(prev_play) # default me_play = random.choice(play_list) learning_point = 40 look_back = 4 if len(opponent_history) > learning_point: if verbose: print("now enter learn and predict mode") print(f"enter learn stage, with learning window {learning_point}") # observations = opponent_history[-learning_point:] observations = opponent_history[:] observations = [[play_list.index(x)] for x in observations] observations = np.array(observations) model = hmm.MultinomialHMM(n_components=n_states, n_iter=100, tol=1, verbose=False, init_params="ste") model_trained = model.fit(observations) start = model_trained.startprob_ if verbose: print("-------- start ---------") print(start) transition = model_trained.transmat_ if verbose: print("-------- transition ---------") print(transition) emission = model_trained.emissionprob_ if verbose: print("-------- emission ---------") print(emission) if verbose: print(f"enter predict stage, with look back {look_back}") obs_now = opponent_history[-look_back:] obs_now = "".join(obs_now) # print(obs_now) options = [obs_now + v for v in play_list] options_prob = [0, 0, 0] for i, one_option in enumerate(options): one_option = list(one_option) one_option = [[play_list.index(x)] for x in one_option] one_option = np.array(one_option) one_prob = model_trained.score(one_option) options_prob[i] = one_prob if verbose: print(f"possible option {one_option} with probability {one_prob}") options_prob = np.array(options_prob) best_index = np.argmax(options_prob) best_play = play_list[best_index] if verbose: print(f"opponent most possible next play is {best_play}") me_play = win_dict[best_play] return me_play
API
https://hmmlearn.readthedocs.io/en/latest/api.html#multinomialhmm
MultinomialHMM
- class
hmmlearn.hmm.MultinomialHMM(n_components=1, startprob_prior=1.0, transmat_prior=1.0, algorithm='viterbi', random_state=None, n_iter=10, tol=0.01, verbose=False, params='ste', init_params='ste')Hidden Markov Model with multinomial (discrete) emissions.
参考
https://github.com/alicelynch/hmm-python-meetup/blob/master/notebooks/Hidden%20Markov%20Model.ipynb
model = hmm.MultinomialHMM(n_components=n_states, n_iter=100, tol=1, verbose=True, init_params="ste") model_trained = model.fit(observations)
其它应用
自然语言生成器
https://github.com/mfilej/nlg-with-hmmlearn/blob/master/train.py
股票价格预测
https://github.com/HvyD/HMM-Stock-Predictor/blob/master/HMM%20Tesla%20Stock%20Predictor.ipynb
https://zhuanlan.zhihu.com/p/166552799
最大可能子序列预测法
https://forum.freecodecamp.org/t/machine-learning-with-python-projects-rock-paper-scissors/412794/4
比赛过程中,统计对手的最近N步,后的出手情况的次数, 根据最大概率, 来推测当前用户出手的可能性。
对于所有的对手都有很好的效果。
Unfortunately I don’t seem to have saved a copy
But basically you use the last n moves to predict what Abby will do next. The important step here ist to basically let your programme dynamically/on the fly build up a list of combinations containing the last n steps + entry n+1 (Abby’s reaction) and their counts. So you start with an empty list, and every time new data rolls in, you check, if you have this entry in the list: If yes increase it’s count by 1, otherwise set it to 1
Say, we have the following example (n=2 for simplicity, to beat Abby you’ll need to increase n): Incoming data: [P,P,R,S,P,P,R…]
Initially list contains
When we have [P,P,R],(length=n+1) we enter ‘PPR’ = 1 (elements 0 to n of incoming data) into our list
Then ‘PRS’ = 1 (elements 1 to n+1 of incoming data)
Then ‘RSP’ = 1 (elements 2 to n+2 of incoming data)
Then ‘SPP’ = 1
Then we see, we already have ‘PPR’ in our list, so we increase it to 2…
Hope this helps, otherwise please feel free to ask! Sorry, I don’t seem to have the code anymore

wtf = {} def player(prev_play, opponent_history=[]): global wtf n = 5 if prev_play in ["R","P","S"]: opponent_history.append(prev_play) guess = "R" # default, until statistic kicks in if len(opponent_history)>n: inp = "".join(opponent_history[-n:]) if "".join(opponent_history[-(n+1):]) in wtf.keys(): wtf["".join(opponent_history[-(n+1):])]+=1 else: wtf["".join(opponent_history[-(n+1):])]=1 possible =[inp+"R", inp+"P", inp+"S"] for i in possible: if not i in wtf.keys(): wtf[i] = 0 predict = max(possible, key=lambda key: wtf[key]) if predict[-1] == "P": guess = "S" if predict[-1] == "R": guess = "P" if predict[-1] == "S": guess = "R" return guess
RNN边赛边练法
https://github.com/fanqingsong/boilerplate-rock-paper-scissors/blob/master/RPS.py
采用RNN网络, 使用在线学习的技术, 在每次对方出手后, 进行在线学习, 然后根据学习后的模型, 进行预测对手下一步出手的可能性。
结果 -- 从中看出abbey还是很难使用RNN网络去对付
-------- you vs quincy -------------
Final results: {'p1': 988, 'p2': 6, 'tie': 6}
Player 1 win rate: 99.3963782696177%
-------- you vs abbey -------------
Final results: {'p1': 431, 'p2': 301, 'tie': 268}
Player 1 win rate: 58.879781420765035%
-------- you vs kris -------------
Final results: {'p1': 768, 'p2': 227, 'tie': 5}
Player 1 win rate: 77.1859296482412%
-------- you vs mrugesh -------------
Final results: {'p1': 828, 'p2': 169, 'tie': 3}
Player 1 win rate: 83.04914744232697%
code
# The example function below keeps track of the opponent's history and plays whatever the opponent played two plays ago. It is not a very good player so you will need to change the code to pass the challenge. import numpy as np import random from keras.models import Sequential from keras.layers import Dense, Input, LSTM from keras.layers.core import Dense, Activation, Dropout from keras.utils import np_utils import keras as K look_back = 4 win_dict = {"R": "P", "S": "R", "P": "S"} def create_nn_model(): init = K.initializers.glorot_uniform(seed=1) simple_adam = K.optimizers.Adam() model = Sequential() # model.add(Input(shape=(look_back,))) model.add(LSTM(10, input_shape=(1,look_back))) # model.add(Dense(20, activation='relu')) model.add(Dense(10, activation='relu')) # model.add(Dropout(0.3)) # model.add(Dense(5, activation='relu')) # model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy']) return model def player(prev_play, opponent_history, model, batch_x, batch_y, review_epochs=10): # print(f"now player1 is in turn, opponent play is {prev_play}") plays = ["R","P","S"] play_dict = {"R":0,"P":1,"S":2} plays_categorial = [[1, 0, 0], [0, 1, 0], [0, 0, 1]] opponent_history_len = len(opponent_history) # print(f"opponent_history_len = {opponent_history_len}") if opponent_history_len < look_back: if prev_play: opponent_history.append(prev_play) guess = random.randint(0,2) return plays[guess] one_x = [play_dict[move] for move in opponent_history[-look_back:]] one_y = play_dict[prev_play] one_y = plays_categorial[one_y] batch_x.append(one_x) batch_y.append(one_y) for i in range(0, review_epochs): # print(f"now train by epoch {i}") batch_x = np.array(batch_x) # print(batch_x.shape) batch_x_final = np.reshape(batch_x, (batch_x.shape[0], 1, batch_x.shape[1])) # print(batch_x.shape) batch_y = np.array(batch_y) # print(batch_y.shape) # print(batch_x_final.shape) # print(batch_y.shape) model.train_on_batch(batch_x_final, batch_y) opponent_history.append(prev_play) current_x = [play_dict[move] for move in opponent_history[-look_back:]] current_x = np.array([current_x]) current_x = np.reshape(current_x, (current_x.shape[0], 1, current_x.shape[1])) predict_y = model.predict_on_batch(current_x) predict_y = predict_y.tolist() # print(predict_y) predict_y = predict_y[0] guess = np.argmax(predict_y) # print(guess) opponent_play = plays[guess] me_play = random.choice(['R', 'P', 'S']) me_play = win_dict.get(opponent_play, me_play) return me_play
参考资料
使用keras进行鸢尾花种类预测
https://www.jianshu.com/p/1d88a6ed707e
https://machinelearningmastery.com/multi-class-classification-tutorial-keras-deep-learning-library/
RNN预测股票收盘价格示例
https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/blob/master/StockPricesPredictionProject/pricePredictionLSTM.py
# create and fit the LSTM network, optimizer=adam, 25 neurons, dropout 0.1 model = Sequential() model.add(LSTM(25, input_shape=(1, look_back))) model.add(Dropout(0.1)) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam') model.fit(trainX, trainY, epochs=1000, batch_size=240, verbose=1) # make predictions trainPredict = model.predict(trainX) testPredict = model.predict(testX)
Tensorflow 2.0 LSTM training model
https://www.programmersought.com/article/57304583087/
# Import library import tensorflow as tf from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics from tensorflow import keras import numpy as np from scipy import sparse import os # Only use gpu 0 os.environ["CUDA_VISIBLE_DEVICES"] = "1" # Set random number seed tf.random.set_seed(22) np.random.seed(22) assert tf.__version__.startswith('2.') batchsz = 256 # batch size # the most frequest words total_words = 4096 # Number of words in the dictionary to be encoded max_review_len = 1995 # How many words does the sequence contain embedding_len = 100 # Length of each word encoding units = 64 # The dimension of the parameter output in the lstm layer epochs = 100 #Train 100 epches # Read in the data, here is the data stored with sparse matrix matrixfile = "textword_numc_sparse.npz" # Import your own text sample, the text has been converted into digital representation targetfile = "target_5k6mer_tfidf.txt" # label, this is the second category allmatrix = sparse.load_npz(matrixfile).toarray() target = np.loadtxt(targetfile) print("allmatrix shape: {};target shape: {}".format(allmatrix.shape, target.shape)) x = tf.convert_to_tensor(allmatrix, dtype=tf.int32) x = keras.preprocessing.sequence.pad_sequences(x, maxlen=max_review_len) y = tf.convert_to_tensor(target, dtype=tf.int32) idx = tf.range(allmatrix.shape[0]) idx = tf.random.shuffle(idx) # Divide the training set, verification set, test set, according to the ratio of 7:1:2 x_train, y_train = tf.gather(x, idx[:int(0.7 * len(idx))]), tf.gather(y, idx[:int(0.7 * len(idx))]) x_val, y_val = tf.gather(x, idx[int(0.7 * len(idx)):int(0.8 * len(idx))]), tf.gather(y, idx[int(0.7 * len(idx)):int(0.8 * len(idx))]) x_test, y_test = tf.gather(x, idx[int(0.8 * len(idx)):]), tf.gather(y, idx[int(0.8 * len(idx)):]) print(x_train.shape,x_val.shape,x_test.shape) db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) db_train = db_train.shuffle(6000).batch(batchsz, drop_remainder=True).repeat() db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val)) db_val = db_val.batch(batchsz, drop_remainder=True) db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) db_test = db_test.batch(batchsz, drop_remainder=True) # Build a model network = Sequential([layers.Embedding(total_words, embedding_len,input_length=max_review_len), layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True), layers.LSTM(units, dropout=0.5, unroll=True), # If using gru, just replace the upper two layers with # layers.GRU(units, dropout=0.5, return_sequences=True, unroll=True), # layers.GRU(units, dropout=0.5, unroll=True), layers.Flatten(), #layers.Dense(128, activation=tf.nn.relu), #layers.Dropout(0.6), layers.Dense(1, activation='sigmoid')]) # View model sumaary network.build(input_shape=(None, max_review_len)) network.summary() # Compile network.compile(optimizer=keras.optimizers.Adam(0.001), loss=tf.losses.BinaryCrossentropy(), metrics=['accuracy']) #Training, note that setps_per_epoches is set here, repeat() is required in db_train, otherwise there is warning, see my article for details: https://blog.csdn.net/weixin_44022515/article/details/103884654 network.fit(db_train, epochs=epochs, validation_data=db_val,steps_per_epoch=x_train.shape[0]//batchsz) network.evaluate(db_test)
keras 在线学习接口 train_on_batch
https://www.programmersought.com/article/2809219970/
for batch_no in range(100): X_train, Y_train = np.random.rand(32, 3), np.random.rand(32, 1) logs = model.train_on_batch(X_train, Y_train)
https://keras.io/api/models/model_training_apis/#trainonbatch-method
Runs a single gradient update on a single batch of data.