1、数据仓库ETL
https://www.cnblogs.com/yjd_hycf_space/p/7772722.html
2、数据仓库分层
ODS:原始数据层
数据来源可能是通过Flume监控、Sqoop导入.......
Flume可以定义拦截器,进行数据ETL。
Sqoop可以通过sql语句,进行数据ETL。
所以很多情况下ods存放的ETL之后的原始数据。
作用:在业务系统和数据仓库之间形成一个隔离层,保存的是原始数据或者ETL之后的原始数据
DWD:数据明细层
是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合,是一个包含所有主题的通用的集合
会在ods层基础上,可能做三件事:
①结构和粒度与ods保持一致,对ods层数据进行再次清洗(去空、去脏数据,去超过极限的数据)
②调整压缩算法、存储格式:
1、存储格式:
HIve的文件存储格式有四种:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET,前面两种是行式存储,后面两种是列式存储。
行式存储:
优点:
a)相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录
b)这种存储格式比较方便进行INSERT/UPDATE操作
缺点:
a)如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能
b)由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高
列式存储
优点:
a)查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询
b)由于每列的数据格式一样,所以压缩率高效,不仅节省储存空间也节省计算内存和CPU
c)任何列都可以作为索引
缺点:
a)INSERT/UPDATE很麻烦或者不方便
b)不适合扫描小量的数据
压缩比:ORC > Parquet > textFile(textfile没有进行压缩)
查询速度:当数据量较大时,列式存储快,数据量小的时候,查询速度无明显区别。
2、压缩:
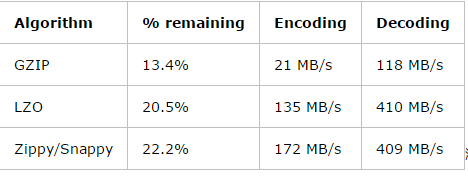
在ods层,我们希望压缩算法的压缩比特别高,用以节省空间!!所以有条件的话会选择gizp压缩,文件存储格式无所谓!!
DWD、DWS中,我们期望的文件格式是解压和压缩速度快,用以提高查询效率!!一般会选择Snappy + (orc或者parquet) //其中如果和spark sql集成了,那么推荐parquet
例子:
create external table t(
.......
.......
)comment '测试表'
partitioned by('dt' string)
stored as parquet //存储格式
location '/warehouse/online_trade/dwd/dwd_t'
tblproperties("parquet.compression"="snappy") //压缩算法
③看是否能进行维度退化
比如说大学这个维度,在mysql中分了大学、学院、专业三个维度,那么将其合并成一个维度!
sql语句比较好实现,也就是三张表合并为一张表(第三范式变为第一范式,直接用join on,这里不写例子)
降维的缺点和优点:
优点:减少shuffle,更贴近星型模型
缺点:增加了冗余,有些维度表不能共用(比如专业很多学校都开设了,如果变为第一范式(一张表),那么不能共用)
注:这里说的降维并不是全部弄成一张大表,还是需要区分事实表和维度表,是将雪花模型的多级维度表进行合并!!!
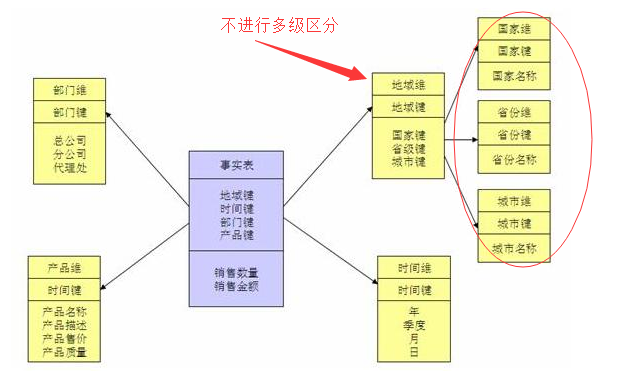
④建模
这个算是这一层最主要的功能了,在这一层的建模中,你必须:
①确定建模方式(雪花模型、星型模型等)
②根据建模的方式抽取维度表和事实表
数据建模请参考上一篇文章:https://www.cnblogs.com/lihaozong2013/p/10725830.html
DWS:数据服务层
以dwd为基础,进行轻度汇总,一般聚集到以用户当日、设备当日、商家当日、商品当日等等的粒度。
在这层通常会有以某一维度为线索,组成跨主题的宽表,比如一个用户的当日签到数、收藏数、评论数、抽奖数、订阅数、浏览商品数、添加购物车数、下单数、支付数等组成的多列表
注:其实这一层就是一张行为宽表,以时间(每天、每周、每月)统计用户(商品、商家)所做的所有事!!!(是最重要的中间表)
注:意义:如果有了这一层,那么对于DM层的什么地区签到、收藏、总评论数等指标都能灵活实现!!
create external table dws_user_action(
user_id string comment '用户id',
order_count bigint comment '下单次数',
order_amount decimal(16,2) comment '下单总金额',
payment_id bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付总金额',
addcart_ct bigint comment '购物车添加次数',
favorite_ct bigint comment '收藏次数',
comment_ct bigint comment '评论次数',
.................. //还有很多列,对于sql,可以先一个指标一个指标求出来,然后根据user_id join
)comment '用户行为宽表'
partitioned by('dt' string)
stored as parquet //存储格式
location '/warehouse/online_trade/dws/dws_user_action'
tblproperties("parquet.compression"="snappy") //压缩算法
ADS:数据应用层
也叫DM:数据集市
也叫APP:数据应用层
数据集市,以某个业务应用为出发点而建设的局部dw,dw只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用。每个应用有自己的DM。
也就是说,面向实际的数据需求,以DWD或者DWS层的数据为基础,组成的各种统计报表。