过拟合是机器学习中常见的问题之一,指的是一个模型由于过度复杂造成在训练集中表现良好而在测试集中表现很差的现象,通常是由于参数过多导致数据相对变小造成的。这是因为在采用极大似然估计的方式进行参数的点估计的时候,复杂的模型总是拟合出更好的结果。但是由于模型过于复杂,它的泛化能力并不一定好。频率派通常采用加一个正规项和交叉验证的方式处理过拟合问题。与此相对的贝叶斯学派用贝叶斯的方法给出一种自然的方法进行模型选择, 找到一个复杂度适中的模型,同时避免了过拟合和欠拟合问题,不需要预先留出一部分数据进行验证。
这里我们所说的模型是指给定数据集的概率分布,用M表示。一个模型的参数越多认为越复杂,模型比较指从不同参数的模型中选出最合适的那一个。贝叶斯模型比较成功的地方在于不是对参数进行点估计,而是边缘化模型中的参数(求和或者积分)从而直接对不同复杂度的模型进行直接比较。复杂的模型虽然可以更好的拟合出给定数据集,但是也为此付出了代价,因此并不是模型越复杂越好,下面对其原理进行分析。
用D表示训练集,表示参数个数为i的模型,现在我们需要比较
和
的大小,用贝叶斯方法计算后验概率
,如下:
对于不同的模型,我们假设其先验概率相等,因此后验概率的比较,取决于
,称为边缘似然函数或者模型证据。边缘似然函数可以通过边缘化似然函数的参数项得到:
现在我们分析并非复杂模型的边缘似然函数也一定高。我们作如下假设:
1. 参数的先验概率是均匀的,宽度是,那么我们有
;
2. 参数的后验概率分布在宽度范围内的概率密度是
;
得到如下结果:
取对数以后得到如下结果:
上式中的第一项表示了用后验概率对模型的拟合程度,第二项是一个惩罚项。因为我们总有,所以第二项是一个负数,当我们得到的数据越多,后验概率确定,第二项越小。上面考虑的是一个参数的情况,如果有M个参数,那么第二项要乘以一个M。可以看出,虽然模型复杂度的增加提高了第一项,但是也降低了第二项。因此我们需要找到一个平衡点,这个平衡点就是复杂度适中的模型。
这个过程可以进一步通过下图表示:
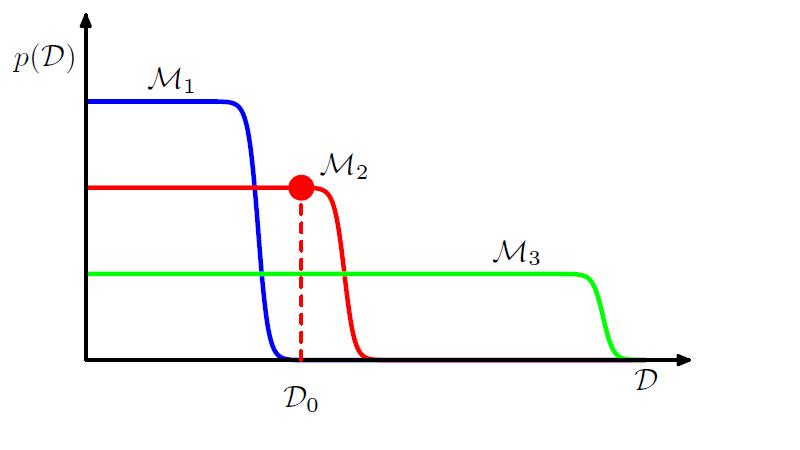
该图来自prml
因为简单的模型只能产生简单的数据,复杂的模型参数多,不仅可以产生简单的数据,同时可以产生复杂的数据。当给定的一个数据集后,简单的模型由于表现能力差,使用边缘似然函数比较小,同时由于过于复杂的模型可以产生更多的复杂数据,那么它产生该特定数据的概率就会相对变小,因此它的边缘似然函数同样不大。只有复杂度适中的模型的边缘似然函数最大。
最后指出,按照贝叶斯模型比较的方法,通常会获得正确的模型。假设一个数据是由产生的,我们计算贝叶斯因子的期望值,其中贝叶斯因子的定义为
,
上面正是相对熵的定义,相对熵是恒大于等0的,因此贝叶斯因子是一个非负数,从平均来看,贝叶斯模型选择正确的模型。
参数资料:
1. pattern recognition and machine learning