- 关于样本测试集和训练集数量上,一般是选择训练集数量不小于测试集,也就是说训练集选取6k可能还不够,大家可以多尝试得到更好的效果; 2. 有人提出归一化方面可能有问题,大家可以查查其他的归一化方法,但是归一化环境是不可少的; 3. 将部分代码传到了**github** 4. 听说阿里又改赛制了,哈哈。
最近好累啊,简单总结一下吧。
碎碎念
这个比赛自己真的是花时间花精力去做了,虽然在s1止步,但是可以说对自己的数据分析入门算是蛮有意义的。收获的东西也蛮多,学了下python,真是一门灵活的语言(感谢o神的入门指南和规范易懂的代码,回头自己也得整理下代码,放到github上,其实之前在github上搜过,目测有10个左右的repository,==);试着学习用了下git,每天提交的版本,不好好管理真的是会分不清最好成绩是那一版,git果然也是码农的神器;还接触了正则表达式(皮毛之皮毛),熟悉了sublime这款精美的编辑器,配上python简直高大上+爱不释手。算法方面,一开始面对这个题目,直接用了经验参数,8号的时候就到了6.8%,排名也蛮靠前,于是乎安安然,一直没去搞LR,cf等等算法,后来发现小伙伴们简直凶残,baseline 蹭蹭涨,排名蹭蹭往下掉。所以立马开始考虑转到LR,虽然之前也搞过一些分类问题,但是回头来看当时做的时候理解还是不够深的,这次索性从线性回归开始重新看了一遍Ng的视频,又加深了理解(但是还是喜欢直接调用,自己编的话太痛苦了吧),建立了逻辑回归模型,最后用纯LR线上到了6.5%吧,感觉还有提高的空间,但是调试的次数太少了。
关于比赛
大赛的赛题和数据在**这里**
关于比赛入门什么的就不应该提了,毕竟能进入s2的大牛应该占大多数。但是目测s2应该还有一些规则用户。我稍微结合自己对模式识别的理解,讲讲一些思路吧,希望能对小白有一点帮助,大牛可以无视了。 整个问题其实可以抽象成一个模式识别问题,对于任意的模式识别系统都可以套用如下的几个步骤:
数据采集->预处理->特征提取->特征选择->分类器选择->分类器评价->再改进分类器
数据采集
这一步当然就不必说,阿里已经给了我们所有的数据
预处理
o神的第一发**指南已经给出了明确的说明,如何数据处理成uid,bid,action_type,date** 其中date是离起始日4月15日的时差。然而模式识别中广义的预处理,除了将原始数据转换成可用的格式外,还包括数据清理,数据集成变换等等。比如说对于从未买过东西的Uid,从来没被买过的Bid直接删除(这对后面要说的正负样本采样很有意义),以及一些数据平滑,比如同一天点击数超过15就平滑为15,超过10次的购买平滑为10次。当然还有比较专业的平滑算法,如移动平滑,指数平滑。
特征提取
特征提取一般是整个系统的核心部分,好的特征是整个判别的关键,在图像处理领域,特征的提取一直是研究的热门。特征的提取一般是依靠个人的经验,这个例子中原始的点击数,购买数,搜藏数,以及加入购物车数,时间,很明显可以作为特征,但是单用这几个特征效果是不大好的。大家讨论的品牌热度,用户购买力,访问天数等等,都应该是不错的特征。这个阶段就需要靠你自己的购物体验,去提取出最好的特征。这样我们就可以得 大专栏 阿里大数据竞赛season1 总结到一个如下的特征矩阵:
---uid bid F1....Fn Label---- 12000 911 5 ... 0.8 0
同时,为了使各个特征的本身属性对分类的影响,比如说点击数一般都是一个很大的数,而某某率则是一个0~1之间的数,这样点击数肯定会对分类有更显著的影响,所以我们必须对特征进行归一化,我这里采用的是列模归一化,具体的做法就是每个值除以它所在列的平均值。
特征选择
特征是不是越多越好呢,这可不一定。特征数量较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
Ø 特征个数越多,分析特征、训练模型所需的时间就越长。 Ø 特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
S2里数据库更大,可玩性更高,估计大家要提前的特征也会更多,特征多的情况下,我们就要坐特征选择了。特征选择的意思就是通过算法能够得到前n个特征组合,使得分类器的error rate 最小,即这样组合最具有判别力。 一般特征选择是利用相关系数,好的特征子集所包含的特征应该是与分类的相关度较高(相关度高),而特征之间相关度较低的(亢余度低)。 可以使用线性相关系数(correlation coefficient) 来衡量向量之间线性相关度。
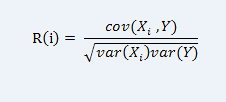
还有之前论文中用到过的mutual information (MI) based method mRMR (minimal-Redundancy-Maximal-Relevance),这个请参考【1】
分类器构造
首先在构建样本时,有个问题就是正负样本不平衡,常规的方法是重采用正样本,欠采样负样本。Bootstrap 采样是常用的重采样方法,简单的说就是又放回的抽样正样本。数据集第3月份的购买 数(即正样本)为215,我们可以通过放回的随机抽样出1k的正样本,未购买数由20000+条,我们可以无放回的随机抽样出5k条,当然正负样本比例1:5,1:10都可以构造。 构造完样本集,可以选择分类器了,貌似大部分选手都是选择的逻辑回归。逻辑回归的介绍请参见o神的**指南3**,实现起来也是比较方便的,当然由于之前选择样本时随机性较大,一般会取1000次LR的结果取平均的参数来减少随机性的影响。 最后就是分类器的评价了,我的训练集选择前2月的行为特征和第三个月的购买(不是所有购买,前两个月有记录且购买)作为label,这样测试集就是前三个月的行为,以及第四个月的购买行为作为label。这样就可以不停的测试本地的分类效果。
最后说几点:
- 模型融合会得到较好的效果,不要单纯的靠一种方法黑到底;
- 多种模型融合的时候,要注意这两种模型尽量不要在同一维度,这样会得到较好的效果
- 以上谈的数据集基本只能对出现过的历史行为做预测,对于没有出现的组合就无力了。如果要预测没有的组合就可以这样建矩阵:样本为所有 uid×bid,即摆出所有出现过的组合,特征还可以那样提,这样样本总数会变多,正样本数也会变多,对于未曾出现过的(uid,bid)组合其一些历史行为相关的特征可能为0,但是用户购买力,品牌热度的特征都是有的。所以也可以两类情况分开建模,没有试过,应该会有效果。当然cf之类的算法在预测未出现的组合上应该也会有不错的效果。排名靠前的港科同学们肯定也是发现了新组合这篇未开垦的处女地,预测数飙到270+。
- LR的结果作为特征再次进行迭代LR会怎么样,没有试过。
[1] H. Peng, F. Long, and C. Ding, “Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy,” Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 27, no. 8, pp. 1226-1238, 2005.