算法、数据结构、金融 算法ppt ,72页!
day30 算法(algorithm):11个py文件 (查找和排序)
1.简介--算法必考
一个计算过程,解决问题的方法
时间复杂度:用来估算算法运行时间的一个式子(单位),一般来说,时间
复杂度高的算法比复杂度低的算法慢。
空间复杂度:用来评估算法内存占用大小的一个式子----一般不讨论了
时间复杂度小结:


时间复杂度是用来估计算法运行时间的一个式子(单位)。 一般来说,时间复杂度高的算法比复杂度低的算法慢。 常见的时间复杂度(按效率排序) O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n2logn)<O(n3) 不常见的时间复杂度(看看就好) O(n!) O(2n) O(nn) … 如何一眼判断时间复杂度? 循环减半的过程O(logn) 几次循环就是n的几次方的复杂度
递归:调用自身,结束条件
# 斐波那契数列
# 1 1 2 3 5 8 13
# 1 2 3 4 5 # def func(x): # if x>0: # func(x-1) # print(x) # # func(5) # 斐波那契数列 # 1 1 2 3 5 8 13 # def fib(n): # if n == 0 or n == 1: # return 1 # else: # return fib(n-1) + fib(n-2) # print(fib(100)) # def fib(n): # li = [1,1] # for i in range(2,n+1): # li.append(li[-1]+li[-2]) # return li[-1] # print(fib(100)) def fib(n): if n == 0 or n == 1: return 1 a = 1 b = 1 c = 1 for i in range(2, n + 1): a = b b = c c = a + b return c print(fib(100))
汉诺塔问题:移盘子
def hanoi(n, A, B, C): if n > 0: hanoi(n-1, A, C, B) print('%s->%s' % (A, C)) hanoi(n-1, B, A, C) hanoi(5, 'A', 'B', 'C')
走楼梯,递归问题,类似于斐波那契,按照最后一步是一阶或者两阶去算
铺砖问题同理
列表查找:顺序查找、二分查找(需要是有序列表)
第21页ppt两个查找代码
def linear_search(data_set, value): for i in range(range(data_set)): if data_set[i] == value: return i return 时间复杂度:O(n) def bin_search(li, val): low = 0 high = len(li) - 1 while low <= high: mid = (low + high) // 2 if li[mid] > val: high = mid - 1 elif li[mid] < val: low = mid + 1 else: # = return mid return None 时间复杂度:O(logn) 应用: li = [1,3,4,5,6,8,9,80] print(bin_search(li,5))
递归版二分查找
列表是对象,可以按照key去查
列表排序:冒泡,选择,插入;快速排序,堆排序,归并排序
算法关键点:有序区、无序区
1.冒泡:必须要会
一趟之后,最大的元素在最上面,共需要n-1趟
顺序: [0,n-i-1]
箭头到n-i-2,但前包后不包,for循环写n-i-1
import random from timewrap import cal_time @cal_time # def bubble_sort(li): # for i in range(len(li)-1): # i表示第i趟 # for j in range(len(li)-i-1): # j表示箭头位置, # if li[j] > li[j+1]: # li[j], li[j+1] = li[j+1], li[j] # print(li) # li = list(range(10)) # random.shuffle(li) #将函数打乱 # print(li) #这10个数开始的顺序 # bubble_sort(li) @cal_time def bubble_sort_2(li): for i in range(len(li)-1): # i表示第i趟 exchange = False for j in range(len(li)-i-1): # j表示箭头位置 if li[j] > li[j+1]: li[j], li[j+1] = li[j+1], li[j] exchange = True if not exchange: return li = list(range(1000)) random.shuffle(li) #将函数打乱 # print(li) bubble_sort_2(li) #print(li)
import time def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() result = func(*args, **kwargs) t2 = time.time() print("%s running time: %s secs." % (func.__name__, t2-t1)) return result return wrapper
2.选择排序:每次选出一个最小的,比冒泡少了交换,所以速度快一些
import random from timewrap import cal_time def find_min(li): #找最小值 min_val = li[0] for i in range(1, len(li)): if li[i] < min_val: min_val = li[i] return min_val def find_min_pos(li): #找最小值位置 min_pos = 0 for i in range(1, len(li)): if li[i] < li[min_pos]: min_pos = i return min_pos @cal_time def select_sort(li): #排序方法 for i in range(len(li)-1): # i表示第i趟 # 无序区的范围 [i, len(li)) min_pos = i for j in range(i+1, len(li)): if li[j] < li[min_pos]: min_pos = j li[i], li[min_pos] = li[min_pos], li[i] # print(li) #每趟结束之后打印 li = list(range(10000)) #random.shuffle(li) # print(li) select_sort(li) #print(li)
3.插入排序:类似于摸牌插入(摸到的牌,手里的牌) 共需要n-1趟
时间复杂度:n方级别,速度与选择差不多
选择速度最快只能是n方,插入和冒泡可能是n
import random from timewrap import cal_time # 何时插入? 1. j位置的值小于tmp 2.j=-1 li[j+1]=tmp @cal_time def insert_sort(li): for i in range(1, len(li)): j = i - 1 tmp = li[i] while j >= 0 and li[j] > tmp: # 循环继续的条件 li[j + 1] = li[j] j -= 1 li[j + 1] = tmp # print(li) li = list(range(10000)) # random.shuffle(li) # print(li) insert_sort(li)
# 布尔值的短路问题 def func(): print('aaa') x = -3 x > 0 and func() # func()不执行 #证明快排空间复杂度 def A(a, b): return a + b def B(a, b): return A(a + b, b) def C(x): return B(x // 2, x + 5) x = C(10) print(x)
4.快速排序:重点!必须掌握!
取一个元素归位,递归完成排序
算法关键点:整理(partition)、递归()
空位的概念,左右寻找(从后开始)
降序排序,只需将两个while条件中的与tmp比较的大于小于号写反
import sys import random from timewrap import cal_time sys.setrecursionlimit(1100) #设置递归深度 def _quick_sort(li, left, right): # 递归函数 前面加_ if left < right: # 至少两个元素 mid = partition(li, left, right) _quick_sort(li, left, mid - 1) _quick_sort(li, mid + 1, right) @cal_time def quick_sort(li): #封装参数的非递归函数 _quick_sort(li, 0, len(li) - 1) def partition(li, left, right): i = random.randint(left, right) #随机化选一个,最坏概率降低 li[left], li[i] = li[i], li[left] #随机化选一个,最坏概率降低 tmp = li[left] while left < right: while left < right and li[right] >= tmp: right -= 1 li[left] = li[right] while left < right and li[left] <= tmp: left += 1 li[right] = li[left] li[left] = tmp return left # @cal_time # def sys_sort(li): #系统自带的排序,底层是c语言,所以速度快 # li.sort() li = list(range(100000, -1, -1)) #把数据倒着 random.shuffle(li) quick_sort(li) # sys_sort(li)
5.堆排序:难!
树与二叉树简介:树是一种数据结构,可以递归定义的数据结构
树的度:最多节点孩子的个数;根节点的度:其对应孩子的个数
二叉树:度不超过2的树(节点最多有两个叉),分左右孩子
满二叉树:每一个结点都达到最大值
完全二叉树:叶结点只能出现在最下层和次下层,且最下面一层的结点都集中在最左边
二叉树的存储方式:链式存储方式--存。。、顺序存储方式(列表)--存完全二叉树
i表示下标:左孩子:2i+1 右孩子:2i+2 孩子找父亲:(i-1)//2
堆:大根堆:一颗完全二叉树,任一节点都比孩子节点大 (排完升序)
小根堆:一颗完全二叉树,任一节点都比孩子节点小(排完降序)
堆的向下调整性质 :左右子树都是堆,但自身不是堆,一次调整即可成堆!
挨个出数:棋子从最后一个非叶子节点开始,退休,棋子,调整
构造堆:从子树开始从下往上调整
堆排序过程:1.建立堆2.得到最大元素3.去掉堆顶,将堆最后一个元素放到堆顶
4.堆顶元素为第二大元素 5.重复3,直到堆变空
代码书写:high表示最后元素的位置;堆排序函数,重点是两个条件
问题:topK问题,现在有n个数,设计算法找出前k大的数(k<n)
1.排序后切片 O(nlogn +k) 2.LowB三人组思想 O(kn)
3.堆排序:建立小根堆, O(nlogk) 建堆klogk +调整 (n-k)logk = O(nlogk)
或用内置模块
import random from timewrap import cal_time # def sift(li, low, high): #调整函数,重点是两个条件 logn # # low 表示根位置 high 表示最后元素的位置 # tmp = li[low] # i = low # i指向空位 # j = 2 * i + 1 # j指向孩子 # # 把tmp写回来有两种条件 1. tmp > li[j] 2. j位置没有值 (也就是i已经是叶子了) # while j <= high: # 对应退出条件2 # if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子存在且右孩子更大 # j += 1 # if li[j] > tmp: # li[i] = li[j] # i = j # j = 2 * i + 1 # else: # 对应退出条件1 # break # li[i] = tmp # # @cal_time # def heap_sort(li): # 堆排函数 # n = len(li) # # 1. 建立堆 # for low in range(n//2-1, -1, -1): #倒着走 # sift(li, low, n-1) # high=n-1 # # print(li) # # 2. 挨个出数 退休-棋子-调整 # for high in range(n-1, -1, -1): # li[0], li[high] = li[high], li[0] #退休 # sift(li, 0, high-1) #注意是high-1 # # print(li) # # # li = list(range(100000)) # random.shuffle(li) # #print(li) # heap_sort(li) import heapq li = [2, 5, 7, 8, 9, 6, 1, 4, 3] heapq.heapify(li) print(li) # 小根堆,建堆的过程 heapq.heappush(li, 0) # 往堆里加入 print(li) print(heapq.heappop(li)) # 返回最小的值 print(heapq.heappop(li)) # 返回最小的值 print(heapq.nlargest(5, li)) # 5个最大的 print(heapq.nsmallest(5, li)) # 5个最小的
6.归并排序:条件分两段有序,一次归并
一个列表一次归并;两个列表一次归并
递归归并 时间复杂度:O(nlogn) 空间复杂度:O(n)
import random from timewrap import cal_time # def merge_two(li1, li2): #两个有序列表 一次归并 # li = [] # i = 0 # j = 0 # while i < len(li1) and j < len(li2): # if li1[i] <= li2[j]: # li.append(li1[i]) # i += 1 # else: # li.append(li2[j]) # j += 1 # while i < len(li1): # li.append(li1[i]) # i += 1 # while j < len(li2): # li.append(li2[j]) # j += 1 # return li #不用写回,直接return即可 def merge(li, low, mid, high): # 一个列表 一次归并代码 li_tmp = [] i = low j = mid + 1 while i <= mid and j <= high: if li[i] <= li[j]: li_tmp.append(li[i]) i += 1 else: li_tmp.append(li[j]) j += 1 while i <= mid: # 左边剩下 li_tmp.append(li[i]) i += 1 while j <= high: # 右边剩下,两个while二选一 li_tmp.append(li[j]) j += 1 for i in range(len(li_tmp)): # 将tmp值写回,tmp值写回列表 li[i + low] = li_tmp[i] def _merge_sort(li, low, high): # 递归归并排序 if low < high: # 2个元素及以上 mid = (low + high) // 2 _merge_sort(li, low, mid) # 分解 _merge_sort(li, mid + 1, high) # 分解 # print(li[low:mid + 1], li[mid + 1:high + 1]) merge(li, low, mid, high) # 合并 # print(li[low:high + 1]) # li = [10, 4, 6, 3, 8, 2, 5, 7] # _merge_sort(li, 0, len(li) - 1) # print(li) @cal_time def merge_sort(li): _merge_sort(li, 0, len(li) - 1) li = list(range(100000)) random.shuffle(li) merge_sort(li)
1 三种排序算法的时间复杂度都是O(nlogn) 2 3 一般情况下,就运行时间而言: 4 快速排序 < 归并排序 < 堆排序 5 6 三种排序算法的缺点: 7 快速排序:极端情况下排序效率低 8 归并排序:需要额外的内存开销 9 堆排序:在快的排序算法中相对较慢
小结:挨着换的稳定
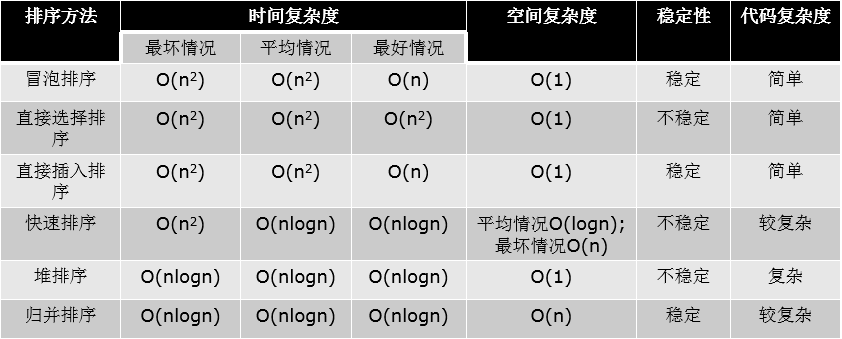
快排、归并必须理解!
排序理解:思路,代码写法,时间复杂度
下周:不常用的排序方式:希尔排序、计数排序、桶排序、基数排序