<ignore_js_op>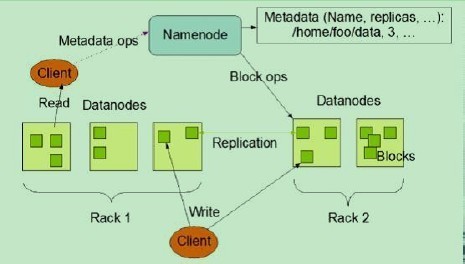
1)NameNode、DataNode和Client
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Client就是需要获取分布式文件系统文件的应用程序。
2)文件写入
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
3)文件读取
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
通信方式介绍:
在hadoop系统中,master/slaves/client的对应关系是:
master---namenode;
slaves---datanode;
client---dfsclient;
那究竟是通过什么样的方式进行通信的呢,在这里从大体介绍一下:
简单地讲:
client和namenode之间是通过rpc通信;
datanode和namenode之间是通过rpc通信;
client和datanode之间是通过简单的socket通信。
随便拔一下DFSClient的代码,可以看到它有一个成员变量public final ClientProtocolnamenode;
而再拔一下DataNode的代码,可以看到它也有一个成员变量public DatanodeProtocolnamenode
文章转自:http://www.aboutyun.com/thread-6794-1-1.html