本博客是学习爬虫的笔记,里面的代码来自崔庆才老师的爬虫课程。
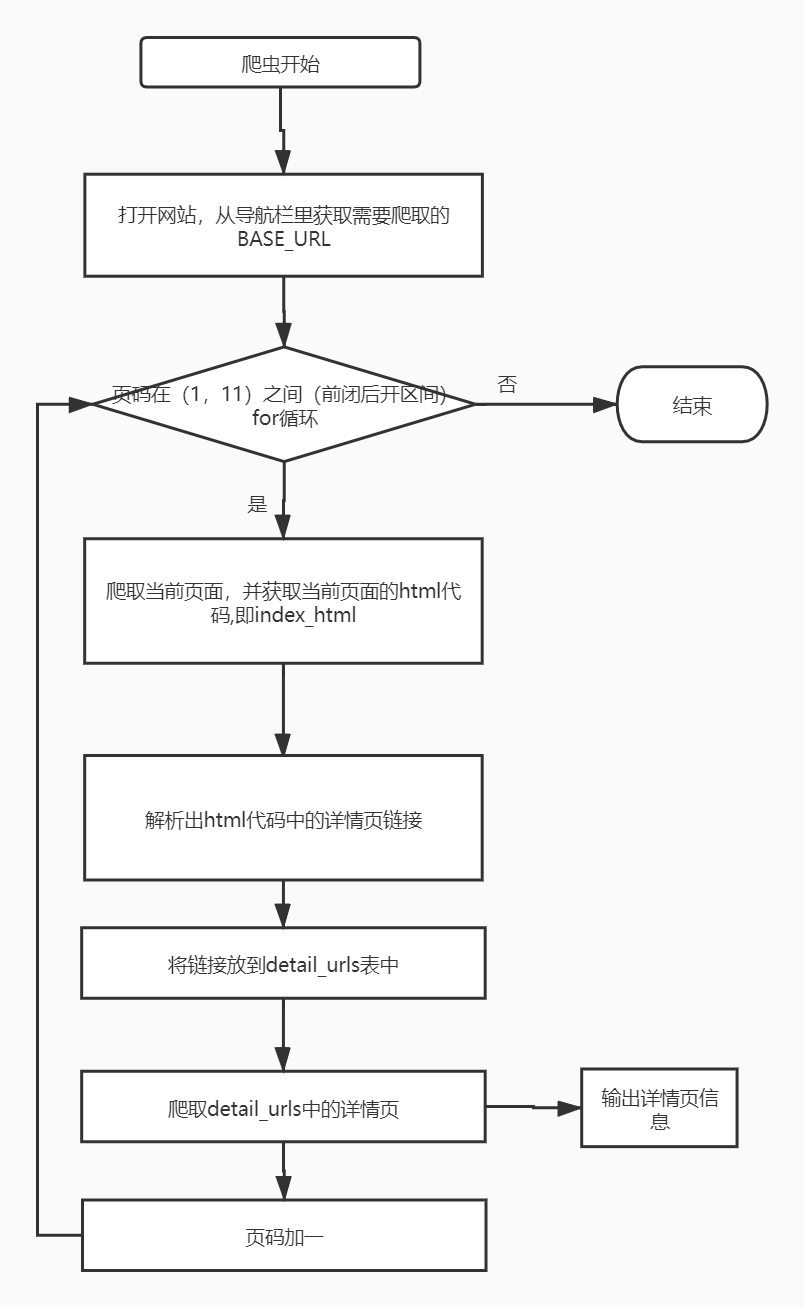
一个网站的内容非常的丰富,爬虫的目的是爬取我们想了解的信息并做处理,因此我们编写爬虫的第一步必须要明确目标。这一步是建立在对网页内容的理解上。以https://static1.scrape.cuiqingcai.com/为例,我们先打开网站(其实我截取的是第二页,不是第一页),看到如下页面。
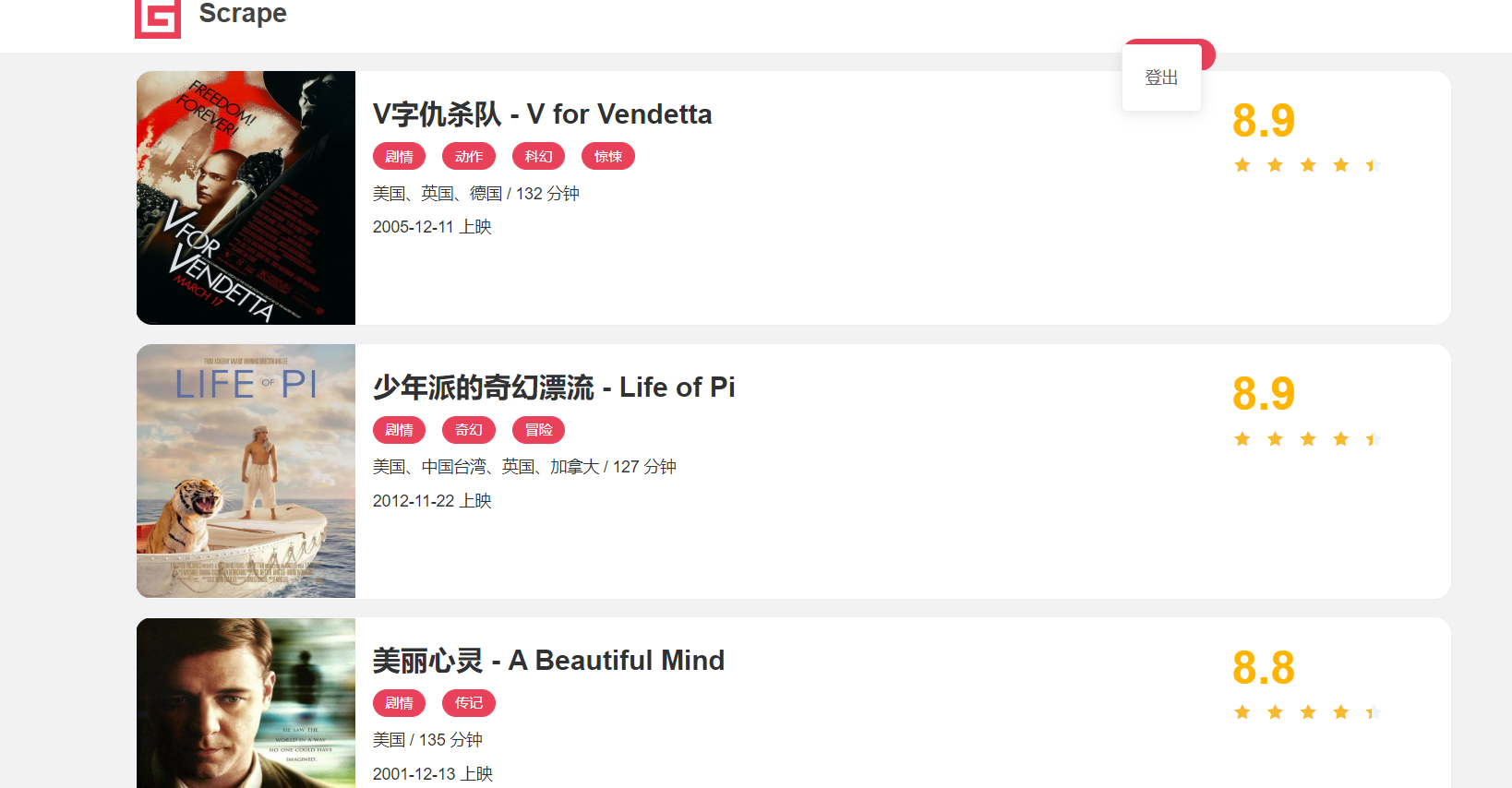
该页的最后是如下页面,表示总共有10页内容,100条,说明每页有十条电影信息。
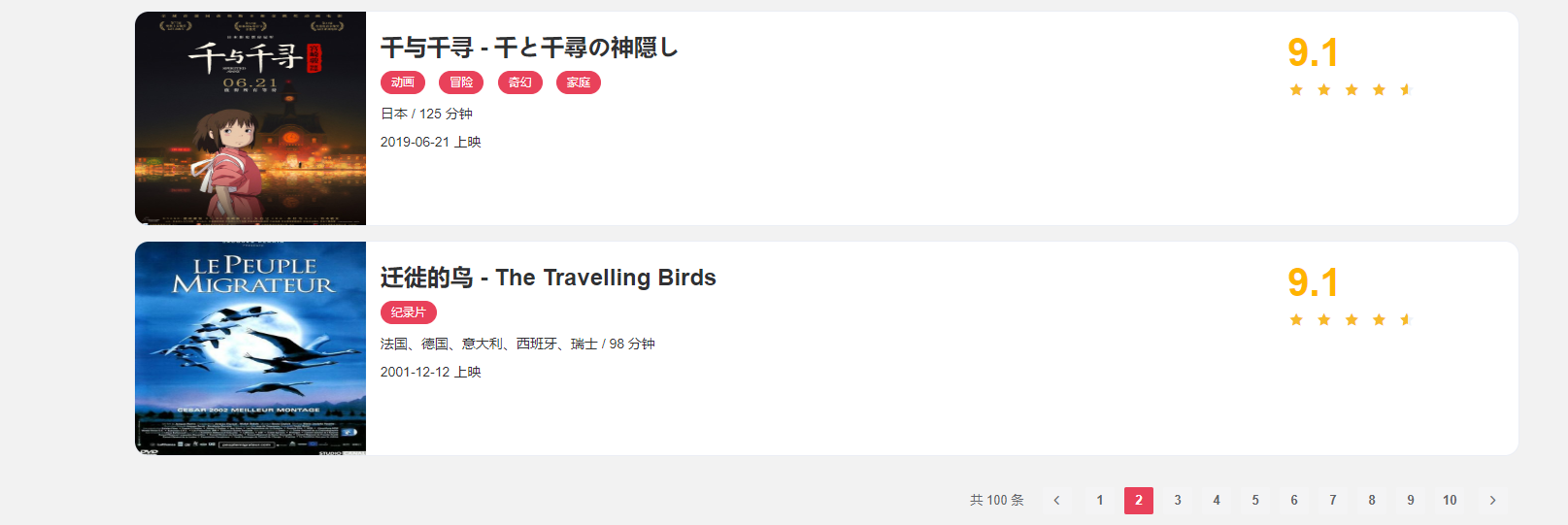
点开第一个电影,我们会看到详情页面,如下

针对这个网页,我们设计了如下的爬取目标:
- 用 requests 爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页。
- 用 pyquery 和正则表达式提取每部电影的名称、封面、类别、上映时间、评分、剧情简介等内容。
- 把以上爬取的内容存入 MongoDB 数据库。
- 使用多进程实现爬取的加速。
1、找到详情页的路径规律,遍历所有详情页
上面的目标,总结来看就是找到进入每个电影详情页的路径,然后爬取详情页里面的有用信息。我们点开详情页会发现上面的链接如下图,也就是在该页链接https://static1.scrape.cuiqingcai.com/的后面拼接了detail/1。

进一步分析网页的代码特点,我们可以在开发者工具上找到电影对应的详情页的相对路径href=‘/detail/1’,这就与我们上面的分析对应了。可以看到这个名称实际上是一个 h2 节点,其内部的文字就是电影的标题。h2 节点的外面包含了一个 a 节点,这个 a 节点带有 href 属性,这就是一个超链接,其中 href 的值为 /detail/1,这是一个相对网站的根 URL https://static1.scrape.cuiqingcai.com/ 路径,加上网站的根 URL 就构成了 https://static1.scrape.cuiqingcai.com/detail/1,也就是这部电影详情页的 URL。这样我们只需要提取这个 href 属性就能构造出详情页的 URL 并接着爬取了。
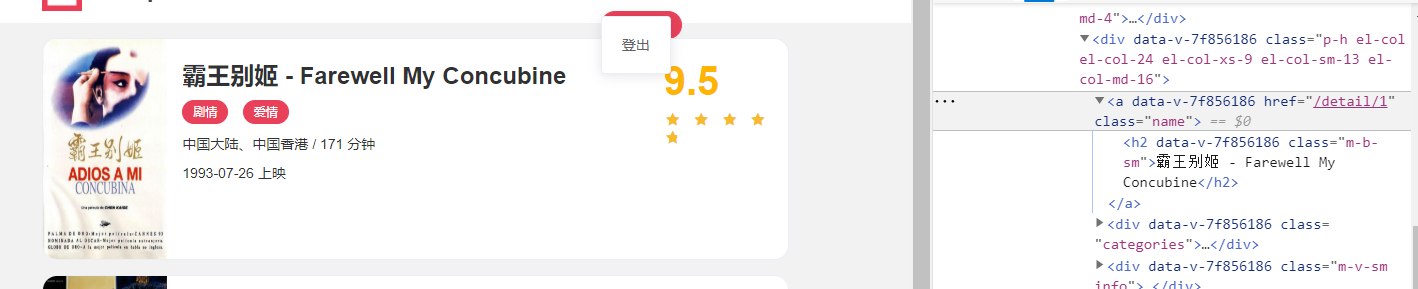
2、分析详情页,输出有用的信息
3、爬虫的流程图