Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
之前说到 Logistic 回归主要用于分类问题,我们以二分类为例,对于所给数据集假设存在这样的一条直线可以将数据完成线性可分。
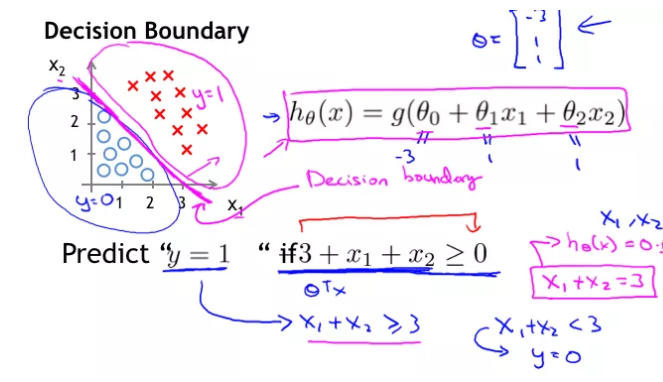
决策边界可以表示为 w1x1+w2x2+b=0 ,假设某个样本点hw(x)= w1x1+w2x2+b>0那么可以判断它的类别为 1,这个过程其实是感知机。Logistic 回归还需要加一层,它要找到分类概率 与输入向量 的直接关系,然后通过比较概率值来判断类别
考虑到 w^Tx+b取值是连续的,因此它不能拟合离散变量。可以考虑用它来拟合条件概率P(y=1/x) ,因为概率的取值也是连续的。

在这我们思考个问题,我们使用对数几率的意义在哪?通过上述推导我们可以看到 Logistic 回归实际上是使用线性回归模型的预测值逼近分类任务真实标记的对数几率,其优点有:
- 直接对分类的概率建模,无需实现假设数据分布,从而避免了假设分布不准确带来的问题;
- 不仅可预测出类别,还能得到该预测的概率,这对一些利用概率辅助决策的任务很有用;
- 对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解。



与其他模型的对比
2.1 与线性回归
逻辑回归是在线性回归的基础上加了一个 sigmoid函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
我们需要明确 sigmoid 函数到底起了什么作用:
- <g_{1,t},...,g_{c,t}...g_{n,t}>线性回归是在实数域范围内进行预测,而分类范围则需要在 <g_{1,t},...,g_{c,t}...g_{n,t}>,逻辑回归减少了预测范围;
- <g_{1,t},...,g_{c,t}...g_{n,t}>线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性。
2.2 与最大熵模型
逻辑回归和最大熵模型本质上没有区别,最大熵在解决二分类问题时就是逻辑回归,在解决多分类问题时就是多项逻辑回归。
最大熵的思想是,当你要猜一个概率分布时,如果你对这个分布一无所知,那就猜熵最大的均匀分布,如果你对这个分布知道一些情况,那么,就猜满足这些情况的熵最大的分布。




<g_{1,t},...,g_{c,t}...g_{n,t}>2.3 与 SVM
<g_{1,t},...,g_{c,t}...g_{n,t}>相同点:
- <g_{1,t},...,g_{c,t}...g_{n,t}>都是分类算法,本质上都是在找最佳分类超平面;
- <g_{1,t},...,g_{c,t}...g_{n,t}>都是监督学习算法;
- <g_{1,t},...,g_{c,t}...g_{n,t}>都是判别式模型,判别模型不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对给定的一个数据进行分类;
- <g_{1,t},...,g_{c,t}...g_{n,t}>都可以增加不同的正则项。
<g_{1,t},...,g_{c,t}...g_{n,t}>不同点:
- <g_{1,t},...,g_{c,t}...g_{n,t}>LR 是一个统计的方法,SVM 是一个几何的方法;
- <g_{1,t},...,g_{c,t}...g_{n,t}>SVM 的处理方法是只考虑 Support Vectors,也就是和分类最相关的少数点去学习分类器。而逻辑回归通过非线性映射减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重;
- <g_{1,t},...,g_{c,t}...g_{n,t}>损失函数不同:LR 的损失函数是交叉熵,SVM 的损失函数是 HingeLoss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。对 HingeLoss 来说,其零区域对应的正是非支持向量的普通样本,从而所有的普通样本都不参与最终超平面的决定,这是支持向量机最大的优势所在,对训练样本数目的依赖大减少,而且提高了训练效率;
- <g_{1,t},...,g_{c,t}...g_{n,t}>LR 是参数模型,SVM 是非参数模型,参数模型的前提是假设数据服从某一分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。所以 LR 受数据分布影响,尤其是样本不均衡时影响很大,需要先做平衡,而 SVM 不直接依赖于分布;
- <g_{1,t},...,g_{c,t}...g_{n,t}>LR 可以产生概率,SVM 不能;
- <g_{1,t},...,g_{c,t}...g_{n,t}>LR 不依赖样本之间的距离,SVM 是基于距离的;
- <g_{1,t},...,g_{c,t}...g_{n,t}>LR 相对来说模型更简单好理解,特别是大规模线性分类时并行计算比较方便。而 SVM 的理解和优化相对来说复杂一些,SVM 转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。

3.1 为什么适合离散特征
我们在使用逻辑回归的时候很少会把数据直接丢给 LR 来训练,我们一般会对特征进行离散化处理,这样做的优势大致有以下几点:离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- >LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- >离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化;
总的来说,特征离散化以后起到了加快计算,简化模型和增加泛化能力的作用。
