希望大家还是在实践当中感受效率,理解效率,写出高质量的代码和算法,仅仅作为参考,不要误导大家。排版尽量舒服吧,尽力了。
一般而言分析算法效率的方式有两种,即:时间效率和空间效率。时间效率也称为时间复杂度;空间效率也称为空间复杂度。在计算机技术发展的几十年中,空间资源变得不是非常重要了,因此在一般的算法分析中,讨论的主要是时间复杂度,当然空间复杂度的分析也是如此。
在算法分析中,我们不使用时间的标准单位(例如:秒,毫秒等)来衡量算法的快慢,而是使用基本操作的次数来衡量时间复杂度。并且,我们在分析时间复杂度的时候仅关注执行次数的增长次数及其常数倍。
对于大规模的输入,增长次数是非常重要的,下面表中第一列给出输入数据的规模,后面的每列是不同时间复杂度对应的执行次数。可以看出logn是最快的,n!是最慢的。
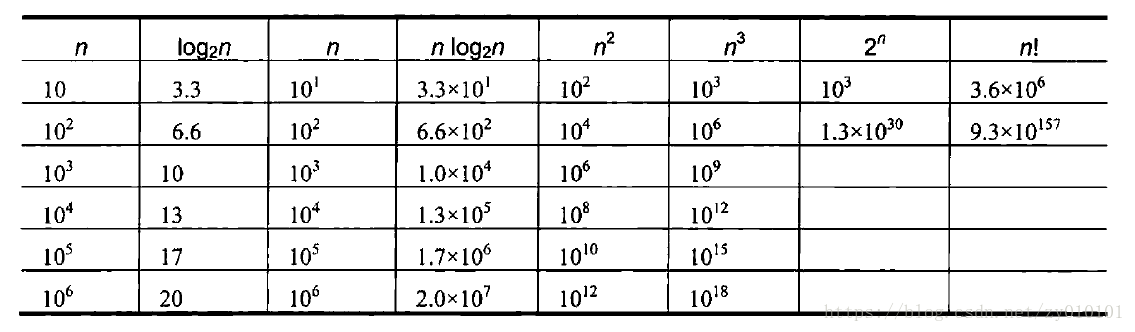
有些时候时间复杂度不仅仅取决于输入数据的规模,还取决于输入数据的一些特定的细节(例如:快速排序算法的最快情况仅需要nlogn,而最坏情况下需要n²。这种差异就取决于原来的序列是随机的还是较为有序的)因此,我们还需要最坏,平均,最优这三种时间复杂度来刻画一个算法的实际情况。所以当一个算法的最优时间复杂度都不能满足要求的时候,那么该算法就可以立即被抛弃。最坏时间复杂度刻画的最坏的情况并不是经常出现的,因此在分析的时候,往往采用的是平均时间复杂度来刻画一个实际问题。


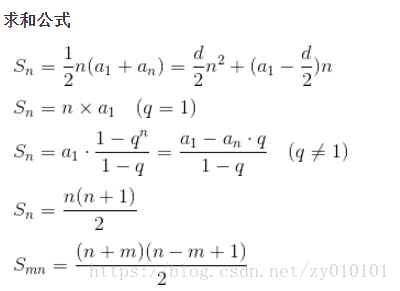

算法效率衡量方法:
1、算法采用的策略和方案
2、编译产生的代码质量
3、问题的输入规模
有三种符号表示的作为分析时间复杂度的方式,分别是O,Ω,θ。简单来说,它们的含义是这样的
O(n)表示增长次数小于等于n的算法;
Ω(n)表示增长次数大于等于n的算法;
θ(n)表示增长次数等于n的算法;
如果一个算法是由两部分组成的,那么他的时间复杂度应该由下面的定理给出:

该定理说明了一个算法整体效率是由具有较大增长次数那部分决定的(效率差的那部分)。
有时候分析算法的时间复杂度需要比较两个函数的极限情况,根据高等数学的知识,我们知道有高阶无穷小,同阶无穷小,以及低阶无穷小。它们对应如下的增长次数

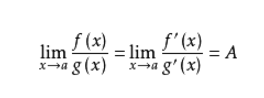
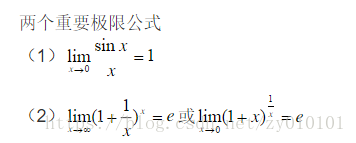
当然,在实际情况下如果输入规模较小的话,那么不同算法之间的时间复杂度几乎对执行没有什么影响,当n的规模大的时候必须认真考虑算法的时间复杂度。下表给出了基本的效率类型

非递归算法的通用效率分析方案:
1、决定使用哪些量作为输入的数据规模;
2、找出算法的基本操作(一般都是在最内层的循环中,并且这个操作每次都要被执行);
3、检查基本操作的次数是否只依赖于输入数据的规模,而与其他东西无关。(若与其他事物有关,那么则应分析出最坏,最优,平均这三种复杂度);
4、建立基本操作执行次数的求和表达式;
5、利用求和运算的公式和法则来建立一个操作次数的闭合公式,或者至少确定它的增长次数。


递归算法的数学分析,由于递归是直观的,我们必须找出递归过程中的初始条件和递推关系。根据初始条件和递推关系求出通项公式。对通项公式分析可以得出算法执行的次数,当然和循环不同的是递归过程中会产生额外的空间开销和时间开销。这就是简单带来的坏处吧!递归算法的分析步骤如下:
-
决定使用哪些量作为输入的数据规模;
-
找出算法的基本操作;
-
检查基本操作的次数是否只依赖于输入数据的规模,而与其他东西无关。(若与其他事物有关,那么则应分析出最坏,最优,平均这三种复杂度);
-
建立一个递推关系式,并且求出初始条件,这样就明确了基本操作执行的次数;
-
由递推关系求出基本操作的关系式,或者至少确定它的增长次数;
大多是递归算法的递推公式是由类型与f(n)= f(x) + C;或者是f(n)= f(x)*C;这种类型的递推公式它在等号右边只会出现一个f(x),这种类型的大都可以用迭代的方式求出其通项公式。但是像斐波那契数列这种递推公式,F(N) = F(N-1)+F(N-2)(这种递推公式被归类为常系数齐次二阶线性递推式)。这种形式的递推公式可以看做是一个二阶常系数线性差分方程来对待。通过求其特解和通解,然后求出全解。

这样我们就得到了斐波那契数列的通项公式。使用递归求解斐波那契数列总是做了很多重复计算:F(N) = F(N-1)+F(N-2)因为算F(N-1)需要算F(N-2)。所以对于数值运算,通常最好不要使用递归。
算法的经验分析
即使我们掌握了上面的这些分析技术,但是在实际中,某些算法还是无法分析的。数学方式并不总是有效的。经验分析是对一些样本输入进行时间或者是操作次数的统计,做出他们的平均值,可以看做是平均效率。也可以使用语言本身提供的系统函数来计算程序执行的时间。
时间复杂度: 排序的时间复杂度可用算法执行中的数据比较次数与数据移动次数来衡量。后面一般都按平均情况进行估算。对于那些受对象关键字序列初始排列及对象个数影响较大的,需要按最好情况和最坏情况进行估算。
空间复杂度:排序过程中需要使用的辅助存储空间。
快速排序时间复杂度
把排序算法想象成二叉树结构

一个数组的容量是N,第一层递归遍历的次数是N,因为数组里每个数字都需要和key比较,那么接下来遍历分出来的两个区间,总的遍历次数还会是近似是N,以此类推,直到分为最后一个,也就是说树的高度是lgn,也就是递归次数,所以时间复杂度是N*lgN.
逆序和有序的时间复杂度为n^2属于最差的情况,辅助空间为n*logn。平均复杂度和最好的情况都为n*logn。
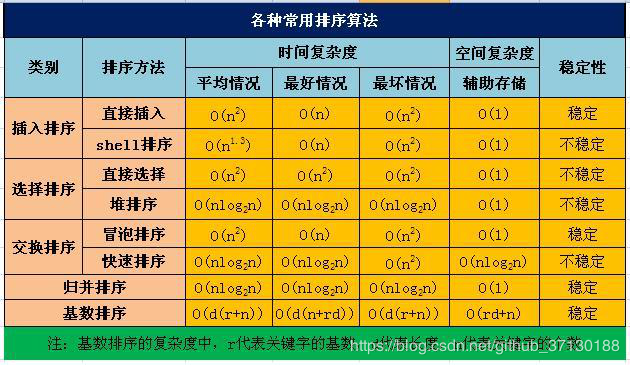
直接插入1+2+........+n=n*(n+1)/2约等于n^2为平均复杂度,最好的情况为正序的时候直接扫描一遍就可以为n,最坏是完全逆序n^2,辅助空间为1.
冒泡排序 n-1 +n-2 + ,,,,,+ 1=n*(n-1)/2为平均复杂度,最好的时间复杂度为正序不发生交换比较就可以了n,最坏的情况是逆序时间复杂度为n^2,辅助空间为1.
直接选择排序n-1+n-2+,,,,+1=(n-1)*n/2为平均复杂度,正序和逆序情况还有最好和最坏的时间复杂度都为n^2,辅助空间为1
堆排序是类似一颗完全二叉树,时间复杂度=递归次数*每次递归遍历次数=n*logn,最好最坏情况都是一颗完全二叉树时间复杂度都为n*logn,注意是“空间复杂度”指占内存大小,堆排序每次只对一个元素操作,是就地排序,所用辅助空间O(1)。
希尔排序最好的情况时间复杂度为n^2,最坏的情况为n。辅助空间为1.对希尔排序的时间复杂度分析很困难,在特定情况下可以准确的估算排序码的比较次数和元素移动的次数,但要想弄清楚排序码比较次数和元素移动次数与增量选择之间的依赖关系,并给出完整的数学分析,还没有人能够做到。