开始尝试sparkSQL的尝试编程。
SparkSQL总体来说就是spark中的hive,但麻烦的一点是spark官网下载的并不自带对hive的支持,所以不能使用外部的hive。之后解决。
所以这次主要关注dataframe的编程。
首先创建了一个json文件用来创建DataFrame,内容为:
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
编写程序的开头。
import findspark findspark.init() from pyspark.sql import SparkSession spark = SparkSession.builder.getOrCreate()
SparkSession是sparksql的入口。
然后就是可以进行操作。
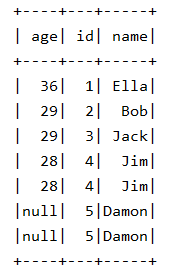
显示所有数据:
df=spark.read.json("file:///usr/local/spark/mycode/exp5/employee.json") df.show()
排序:
df = spark.read.json("file:///usr/local/spark/mycode/exp5/employee.json") df.sort(df.age.desc()).show()

求均值:
df = spark.read.json("file:///usr/local/spark/mycode/exp5/employee.json") df.groupBy().avg("age").show()
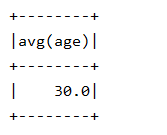
值得一提,python中的dataframe可以直接调用其中的列作为迭代器,但只能作为dataframe函数的参数。看了源代码之后发现dataframe函数和groupBy之后的函数不一样,就想avg、max等函数只有在groupBy之后才能使用,但这时不能使用迭代器(也就是df.age这类),只能使用string。
具体函数可以参考文档。
在值得一提,发现一个很有用的功能。
df.agg({"age": "max"}).show()
from pyspark.sql import functions as F df.agg(F.min(df.age)).show()
agg(*exprs)[source]这个函数可以免去group的麻烦()。