论文相似度计算系统
相关链接
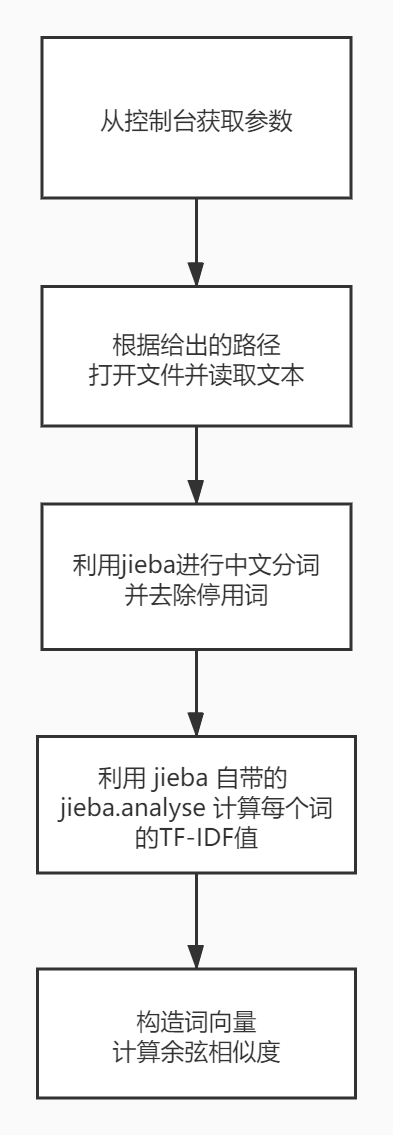
算法及流程图
-
在不断地使用搜索引擎和翻看各路大佬的博客之后,决定使用比较简单的算法(老懒狗了),直接用jieba分词(关于jieba的使用,GitHub上有详细的说明)并计算各个词的TF-IDF值(停用词表采用的是jieba自带的,TF-IDF语料库也是采用jieba自带的),再用TF-IDF值构造词向量,最后计算余弦相似度(虽然算法简单,但貌似效果还不错)。
有关 TF-IDF 具体可以参考阮一峰老师的两篇博客:
我和博客中的算法稍稍有些不一样,博客中的相似度计算的方法,是先从两篇文章中各提取出TF-IDF值最高的20个关键字,取并集,然后根据这些关键词的出现频率生成两个词向量。
-
流程图
计算模块接口的设计与实现过程
(这么头疼的玩意当然是用 Python 比较爽了)
-
类的定义
只定义了一个 Document 类,用来存放读取后的文本,分词的结果及每个词对应的 TF-IDF 的字典。
- 初始化的时候从给定的路径中读取文本,然后调用 self.__analyse( ) 方法分析文本
def __init__(self, path): self.__path = path self.__words = [] self.__tfidf = {} # read txt file try: self.__file = open(path, encoding='utf-8') self.__text = self.__file.read() self.__file.close() except: print("无法读取 %s"%(self.__path)) raise # analyse text self.__analyse()- self.__analyse( ) 方法通过调用 jieba.analyse.extract_tags( ) 分词并获取各个词的TF-IDF值
# analyse text def __analyse(self): for word,tfidf in jieba.analyse.extract_tags(self.__text, topK=0, withWeight=True): self.__words.append(word) self.__tfidf[word] = tfidf # print(self.__words)-
提供了两个接口函数
get_words( ) 用来获取文本中的词汇,返回的是一个列表。
# get words list def get_words(self) -> list: return self.__words get_tfidf( ) 用来查询某个词在该文本中的TF-IDF值,如果文本中没有该词则返回0。
# get TF-IDF def get_tfidf(self, word) -> float: return self.__tfidf.get(word, 0) -
相似度计算函数
参数为两个 Document 对象,返回两个文本的余弦相似度。
# caculate similiarity def caculate_similarity(doc_1:Document, doc_2:Document) -> float: keywords_1 = set(doc_1.get_words()) keywords_2 = set(doc_2.get_words()) if len(keywords_1) == 0 or len(keywords_2) == 0: print("文本无有效词汇,请输入包含有效词汇的文本路径") raise keywords = keywords_1 and keywords_2 # build vector vector = [] for keyword in keywords: vector.append((doc_1.get_tfidf(keyword), doc_2.get_tfidf(keyword))) # caculate cosine_similiarity v_1 = 0 v_2 = 0 v = 0 for i in vector: v_1 += i[0] ** 2 v_2 += i[1] ** 2 v += (i[0] * i[1]) similiarity = v / math.sqrt(v_1 * v_2) # return caculate result return similiarity
计算模块接口部分的性能改进
-
用pycharm自带的 profile (pycharm永远滴神)分析了性能,生成了以下图片。
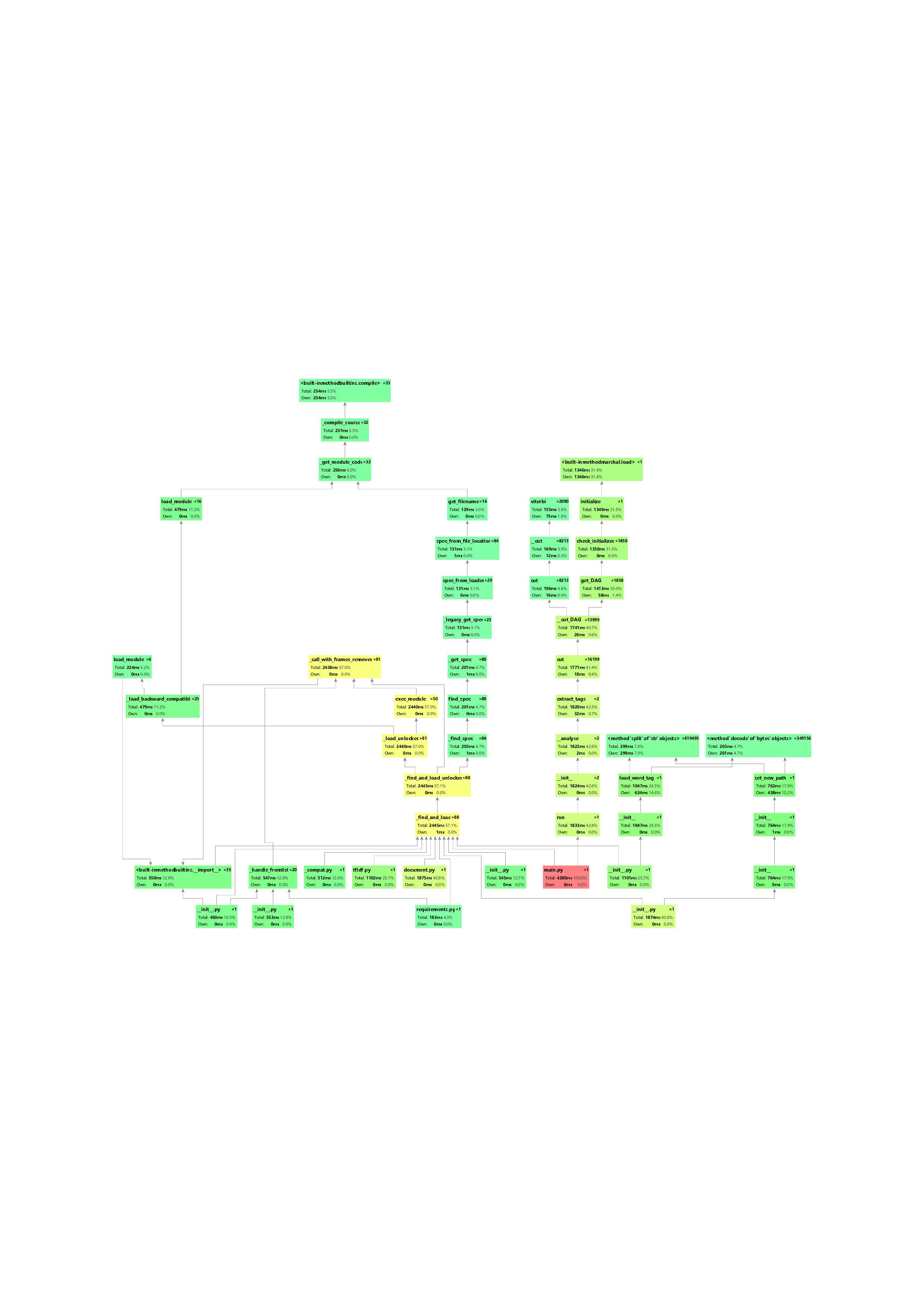
放大之后可以看到
总共耗时4秒多,说实话挺慢的。
但再细看各个部分

基本上是jieba占据了大部分时间开销。
jieba.analyse.extract_tags(self.__text, topK=0, withWeight=True)这个函数可以用来分词(自动去除了标点、停用词等)并返回各个词的TF-IDF值的,最开始我是采用分词后直接用词频率构造词向量去算相似度,虽然在效果上可能没有TF-IDF来的好,但明显快多了。(写完了才知道有gensim这玩意,应该会比这个快)
可以看到计算的部分其实耗时是非常少的:
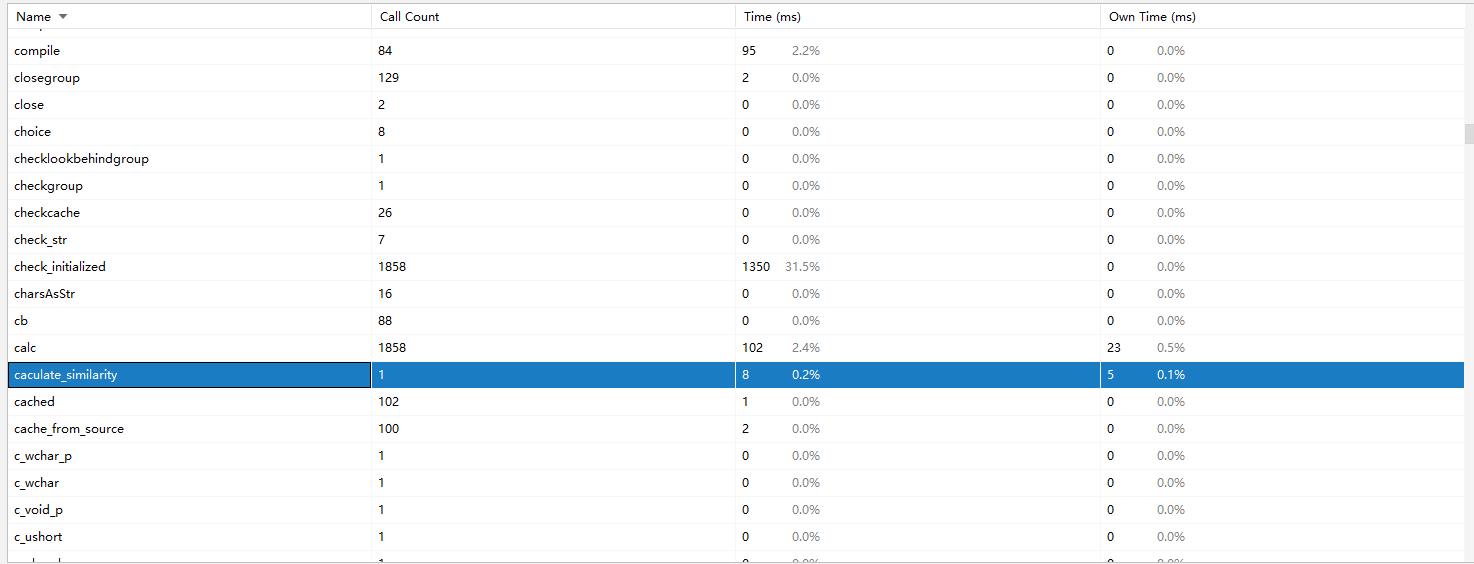
计算模块部分单元测试展示
-
看着别人的博客照葫芦画瓢写了几个测试,第一次搞这玩意属实很懵。
一共测试了提供的九个文本和两个异常处理,一个是文本为空的时候抛出 RuntimeError,还有一个是路径不存在时抛出 FileNotFoundError 。
C:Users小明venvScriptspython.exe "H:/Workspace/Software Engineering/paper_check_system/ut.py"
test add
0.8601768754747804
test over!
test del
..0.8985891244539704
test over!
test dis_1
.0.9808112866546317
test over!
test dis_10
.0.9233929083371283
test over!
test dis_15
0.7122391923479036
test over!
test dis_3
..0.9613218437864147
test over!
test dis_7
..0.9511418312250954
test over!
test mix
..0.9368555273793027
test over!
test rep
0.7963167032716033
test over!
test err_1
无法读取 123
test over!
test err_2
文本无有效词汇,请输入包含有效词汇的文本路径
test over!
.
----------------------------------------------------------------------
Ran 11 tests in 6.066s
OK
Process finished with exit code 0
-
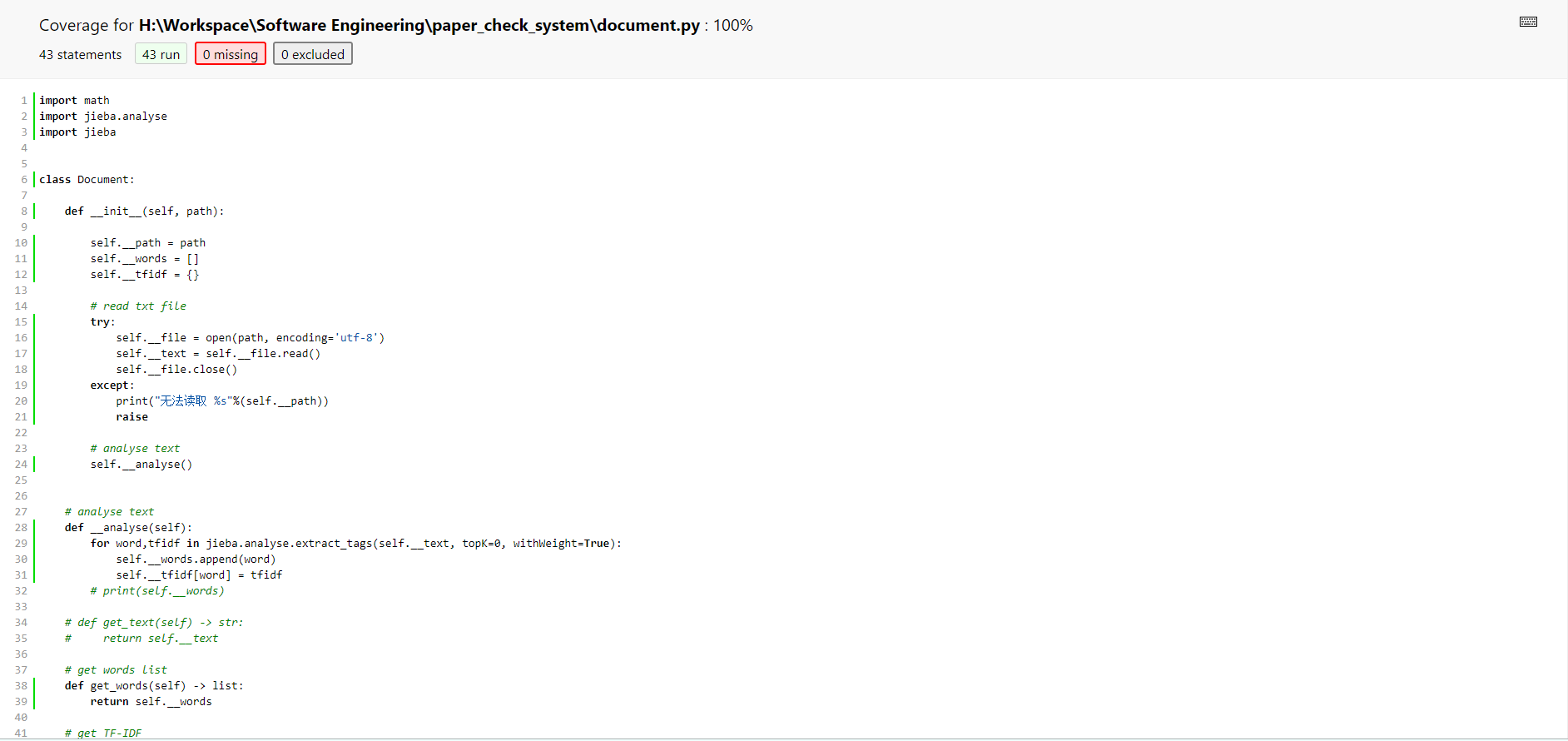
生成的 coverage 报告 可以看出 document.py已经100%覆盖
-
下面是单元测试的代码:
import unittest
import document
import logging
import jieba
class MyClassTest(unittest.TestCase):
def setUp(self) -> None:
jieba.setLogLevel(logging.INFO)
def tearDown(self) -> None:
print("test over!")
def test_add(self):
print('test add')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_add.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_del(self):
print('test del')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_del.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_dis_1(self):
print('test dis_1')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_dis_1.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_dis_3(self):
print('test dis_3')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_dis_3.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_dis_7(self):
print('test dis_7')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_dis_7.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_dis_10(self):
print('test dis_10')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_dis_10.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_dis_15(self):
print('test dis_15')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_dis_15.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_mix(self):
print('test mix')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_mix.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_rep(self):
print('test rep')
doc_1 = document.Document(r"sim_0.8/orig.txt")
doc_2 = document.Document(r"sim_0.8/orig_0.8_rep.txt")
ans = document.caculate_similarity(doc_1, doc_2)
print(ans)
self.assertGreaterEqual(ans,0)
self.assertLessEqual(ans,1)
def test_err_1(self):
print('test err_1')
self.assertRaises(FileNotFoundError, document.Document, '123')
def test_err_2(self):
print('test err_2')
doc_1 = document.Document(r"1.txt")
doc_2 = document.Document(r"2.txt")
self.assertRaises(RuntimeError, document.caculate_similarity, doc_1, doc_2)
if __name__ == '__main__':
unittest.main()
计算模块异常处理
-
计算模块只写了一个文本为空的时候抛出异常,因为会导致计算余弦相似度的时候出现除以零的情况(想不到别的了)。
keywords_1 = set(doc_1.get_words()) keywords_2 = set(doc_2.get_words()) if len(keywords_1) == 0 or len(keywords_2) == 0: print("文本无有效词汇,请输入包含有效词汇的文本路径") raise
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 180 | 240 |
| Analysis | 需求分析 (包括学习新技术) | 480 | 600 |
| Design Spec | 生成设计文档 | 60 | 40 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 15 |
| Design | 具体设计 | 120 | 120 |
| Coding | 具体编码 | 180 | 240 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | 20 | 20 |
| Test Report | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1420 | 2025 |
总结
讲实话学算法和写代码的时间好像花的也并不是很多,到是折腾 git、单元测试、性能分析啥的折腾了挺久(都是第一次用,研究了好长时间)。为了写这次作业,疯狂的使用搜索引擎,各种看博客,才慢慢磨出了这结果,老折磨了。u1s1还是自己学得太少,才写一次作业就得各种补漏(要是以前没事的时候多学点东西多好)。虽然累,但是靠着百度的力量,不仅学到了很多从来没接触过的知识,很大程度上也提高自己解决问题的能力,也算是一次很不错的体验。还是希望以后别当懒狗了,积极一点,多学点知识,以后总用得上的。