一、线性
线性的组织形式对程序的性能是非常重要的。

gridDim.x 线程网格X维度上线程块
gridDim.y 线程网格Y维度上线程块的数量
blockDim.x 一个线程块X维度上的线程数量
blockDim.y 一个线程块Y维度上的线程数量
blockIdx.x 线程网格X维度上的线程块索引
blockIdx.y 线程网格Y维度上的线程块索引
threadIdx.x 线程块X维度上的线程索引
threadIdx.y 线程块Y维度上的线程索引
二、线程索引
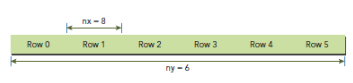
通常,一个矩阵以线性存储在global memory 中,并且以行来实现线性:
在kernel中,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
• 线程和block索引
• 矩阵中元素坐标
• 线性global memory的偏移
1. 将thread和block索引映射到矩阵坐标
ix = thredIdx.x + blockIdx.x * blockDim.x;
iy = threadIdx.y + blockIdx.y * blockDim.y;
2.利用上述的变量计算线性地址:
idx = iy * nx + ix
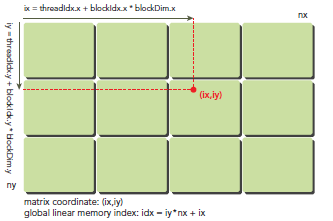
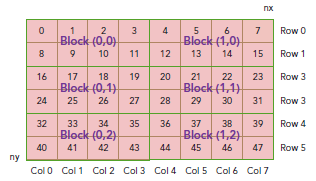
上图t是block 和 thread索引, 矩阵坐标以及线性地址之间的关系。
相邻的thread拥有连续的threadIdx.x,即索引为(0,0)(1,0)(2,0)...的thread连续
不是(0,0)(0,1) (0,2)..连续,与线代中的矩阵不同
例如:可以验证下面的关系:
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
三、 CUDA应用案例
1. 查看GPU的一些硬件配置情况
1 #include "device_launch_parameters.h" 2 #include <iostream> 3 4 int main() 5 { 6 int deviceCount; 7 cudaGetDeviceCount(&deviceCount); 8 for(int i=0;i<deviceCount;i++) 9 { 10 cudaDeviceProp devProp; 11 cudaGetDeviceProperties(&devProp, i); 12 std::cout << "使用GPU device " << i << ": " << devProp.name << std::endl; 13 std::cout << "设备全局内存总量: " << devProp.totalGlobalMem / 1024 / 1024 << "MB" << std::endl; 14 std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl; 15 std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl; 16 std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl; 17 std::cout << "设备上一个线程块(Block)种可用的32位寄存器数量: " << devProp.regsPerBlock << std::endl; 18 std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl; 19 std::cout << "每个EM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl; 20 std::cout << "设备上多处理器的数量: " << devProp.multiProcessorCount << std::endl; 21 std::cout << "======================================================" << std::endl; 22 23 } 24 return 0; 25 }
利用nvcc来编译程序
nvcc test.cu -o test
输出结果:

2.计算任务:将两个元素数目为1024*1024的float数组相加
用CPU是如何串行完成任务:

#include <iostream> #include <stdlib.h> #include <sys/time.h> #include <math.h> using namespace std; int main() { struct timeval start, end; gettimeofday( &start, NULL ); float*A, *B, *C; int n = 1024 * 1024; int size = n * sizeof(float); A = (float*)malloc(size); B = (float*)malloc(size); C = (float*)malloc(size); for(int i=0;i<n;i++) { A[i] = 90.0; B[i] = 10.0; } for(int i=0;i<n;i++) { C[i] = A[i] + B[i]; } float max_error = 0.0; for(int i=0;i<n;i++) { max_error += fabs(100.0-C[i]); } cout << "max_error is " << max_error << endl; gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }

用GPU做并行计算,速度的变化:
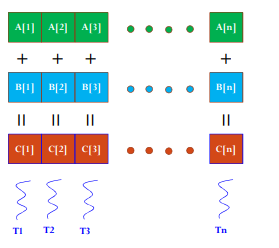
编程的要点:
每个block中的Thread数最大不超过512
为了充分利用SM,Block数尽可能多,>100
# include "cuda_runtime.h" # include <stdlib.h> # include <iostream> # include <sys/time.h> using namespace std; __galbal__ void add(float A[], float B[],float C[], int n) { int i = blockDim.x * blockIdx.x + threadIdx.x; C[i] = A[i] + B[i]; } int main() { struct timeval start , end; gettimeofday (&start,NULL) float*A, *Ad, *B, *Bd, *C, *Cd; int n = 1024 * 1024; int size = n * sizeof(float); // CPU端分配内存 A = (float*)malloc(size); B = (float*)malloc(size); C = (float*)malloc(size); // 初始化数组 for(int i=0;i<n;i++) { A[i] = 90.0; B[i] = 10.0; } // GPU端分配内存 cudaMalloc((void**)&Ad, size); cudaMalloc((void**)&Bd, size); cudaMalloc((void**)&Cd, size); // CPU的数据拷贝到GPU端 cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice); // 定义kernel执行配置,(1024*1024/512)个block,每个block里面有512个线程 dim3 dimBlock(512); dim3 dimGrid(n/512); // 执行kernel Plus<<<dimGrid, dimBlock>>>(Ad, Bd, Cd, n); // 将在GPU端计算好的结果拷贝回CPU端 cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost); // 校验误差 float max_error = 0.0; for(int i=0;i<n;i++) { max_error += fabs(100.0 - C[i]); } cout << "max error is " << max_error << endl; // 释放CPU端、GPU端的内存 free(A); free(B); free(C); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }

从这个程序中,使用CUDA编程时没有for循环,因为CPU编程的循环已经被分散到各个thread上做了,所以没有for一类的语句了。从结果可知,CPU的循环计算的速度比GPU计算快多了,原因在于CUDA中有大量的内存拷贝操作(数据的传输花费了大量时间,但计算时间却非常少),如果计算量比较小的话,CPU计算会更合适。
接下来案例:矩阵加法,两个矩阵对应坐标的元素相加后的结果存储在第三个的对应位置的元素上。
这个计算任务采用二维数据的计算方式,注意一下二维数组在CUDA编程中的写法。
CPU版本:


1 #include <stdlib.h> 2 #include <iostream> 3 #include <sys/time.h> 4 #include <math.h> 5 6 #define ROWS 1024 7 #define COLS 1024 8 9 using namespace std; 10 11 int main() 12 { 13 struct timeval start, end; 14 gettimeofday( &start, NULL ); 15 int *A, **A_ptr, *B, **B_ptr, *C, **C_ptr; 16 int total_size = ROWS*COLS*sizeof(int); 17 A = (int*)malloc(total_size); 18 B = (int*)malloc(total_size); 19 C = (int*)malloc(total_size); 20 A_ptr = (int**)malloc(ROWS*sizeof(int*)); 21 B_ptr = (int**)malloc(ROWS*sizeof(int*)); 22 C_ptr = (int**)malloc(ROWS*sizeof(int*)); 23 24 //CPU一维数组初始化 25 for(int i=0;i<ROWS*COLS;i++) 26 { 27 A[i] = 80; 28 B[i] = 20; 29 } 30 31 for(int i=0;i<ROWS;i++) 32 { 33 A_ptr[i] = A + COLS*i; 34 B_ptr[i] = B + COLS*i; 35 C_ptr[i] = C + COLS*i; 36 } 37 38 for(int i=0;i<ROWS;i++) 39 for(int j=0;j<COLS;j++) 40 { 41 C_ptr[i][j] = A_ptr[i][j] + B_ptr[i][j]; 42 } 43 44 //检查结果 45 int max_error = 0; 46 for(int i=0;i<ROWS*COLS;i++) 47 { 48 //cout << C[i] << endl; 49 max_error += abs(100-C[i]); 50 } 51 52 cout << "max_error is " << max_error <<endl; 53 gettimeofday( &end, NULL ); 54 int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; 55 cout << "total time is " << timeuse/1000 << "ms" <<endl; 56 57 return 0; 58 }

GPU版本
1 #include "cuda_runtime.h" 2 #include "device_launch_parameters.h" 3 #include <sys/time.h> 4 #include <stdio.h> 5 #include <math.h> 6 #define Row 1024 7 #define Col 1024 8 9 10 __global__ void addKernel(int **C, int **A, int ** B) 11 { 12 int idx = threadIdx.x + blockDim.x * blockIdx.x; 13 int idy = threadIdx.y + blockDim.y * blockIdx.y; 14 if (idx < Col && idy < Row) { 15 C[idy][idx] = A[idy][idx] + B[idy][idx]; 16 } 17 } 18 19 int main() 20 { 21 struct timeval start, end; 22 gettimeofday( &start, NULL ); 23 24 int **A = (int **)malloc(sizeof(int*) * Row); 25 int **B = (int **)malloc(sizeof(int*) * Row); 26 int **C = (int **)malloc(sizeof(int*) * Row); 27 int *dataA = (int *)malloc(sizeof(int) * Row * Col); 28 int *dataB = (int *)malloc(sizeof(int) * Row * Col); 29 int *dataC = (int *)malloc(sizeof(int) * Row * Col); 30 int **d_A; 31 int **d_B; 32 int **d_C; 33 int *d_dataA; 34 int *d_dataB; 35 int *d_dataC; 36 //malloc device memory 37 cudaMalloc((void**)&d_A, sizeof(int **) * Row); 38 cudaMalloc((void**)&d_B, sizeof(int **) * Row); 39 cudaMalloc((void**)&d_C, sizeof(int **) * Row); 40 cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col); 41 cudaMalloc((void**)&d_dataB, sizeof(int) *Row*Col); 42 cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col); 43 //set value 44 for (int i = 0; i < Row*Col; i++) { 45 dataA[i] = 90; 46 dataB[i] = 10; 47 } 48 //将主机指针A指向设备数据位置,目的是让设备二级指针能够指向设备数据一级指针 49 //A 和 dataA 都传到了设备上,但是二者还没有建立对应关系 50 for (int i = 0; i < Row; i++) { 51 A[i] = d_dataA + Col * i; 52 B[i] = d_dataB + Col * i; 53 C[i] = d_dataC + Col * i; 54 } 55 56 cudaMemcpy(d_A, A, sizeof(int*) * Row, cudaMemcpyHostToDevice); 57 cudaMemcpy(d_B, B, sizeof(int*) * Row, cudaMemcpyHostToDevice); 58 cudaMemcpy(d_C, C, sizeof(int*) * Row, cudaMemcpyHostToDevice); 59 cudaMemcpy(d_dataA, dataA, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); 60 cudaMemcpy(d_dataB, dataB, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); 61 dim3 threadPerBlock(16, 16); 62 dim3 blockNumber( (Col + threadPerBlock.x - 1)/ threadPerBlock.x, (Row + threadPerBlock.y - 1) / threadPerBlock.y ); 63 printf("Block(%d,%d) Grid(%d,%d). ", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y); 64 addKernel << <blockNumber, threadPerBlock >> > (d_C, d_A, d_B); 65 //拷贝计算数据-一级数据指针 66 cudaMemcpy(dataC, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); 67 68 int max_error = 0; 69 for(int i=0;i<Row*Col;i++) 70 { 71 //printf("%d ", dataC[i]); 72 max_error += abs(100-dataC[i]); 73 } 74 75 //释放内存 76 free(A); 77 free(B); 78 free(C); 79 free(dataA); 80 free(dataB); 81 free(dataC); 82 cudaFree(d_A); 83 cudaFree(d_B); 84 cudaFree(d_C); 85 cudaFree(d_dataA); 86 cudaFree(d_dataB); 87 cudaFree(d_dataC); 88 89 printf("max_error is %d ", max_error); 90 gettimeofday( &end, NULL ); 91 int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; 92 printf("total time is %d ms ", timeuse/1000); 93 94 return 0; 95 }

从结果看出:CPU计算时间还是比GPU的计算时间短。
这种二维数组的程序写法的效率并不高(比较符合我们的思维方式),因为我们做了两次访存操作。
一般而言,做高性能计算一般不采取这种编程方式。
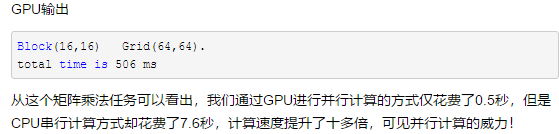
案例:矩阵乘法

CPU版本:
1 #include <iostream> 2 #include <stdlib.h> 3 #include <sys/time.h> 4 5 #define ROWS 1024 6 #define COLS 1024 7 8 using namespace std; 9 10 void matrix_mul_cpu(float* M, float* N, float* P, int width) 11 { 12 for(int i=0;i<width;i++) 13 for(int j=0;j<width;j++) 14 { 15 float sum = 0.0; 16 for(int k=0;k<width;k++) 17 { 18 float a = M[i*width+k]; 19 float b = N[k*width+j]; 20 sum += a*b; 21 } 22 P[i*width+j] = sum; 23 } 24 } 25 26 int main() 27 { 28 struct timeval start, end; 29 gettimeofday( &start, NULL ); 30 float *A, *B, *C; 31 int total_size = ROWS*COLS*sizeof(float); 32 A = (float*)malloc(total_size); 33 B = (float*)malloc(total_size); 34 C = (float*)malloc(total_size); 35 36 //CPU一维数组初始化 37 for(int i=0;i<ROWS*COLS;i++) 38 { 39 A[i] = 80.0; 40 B[i] = 20.0; 41 } 42 43 matrix_mul_cpu(A, B, C, COLS); 44 45 gettimeofday( &end, NULL ); 46 int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; 47 cout << "total time is " << timeuse/1000 << "ms" <<endl; 48 49 return 0; 50 }

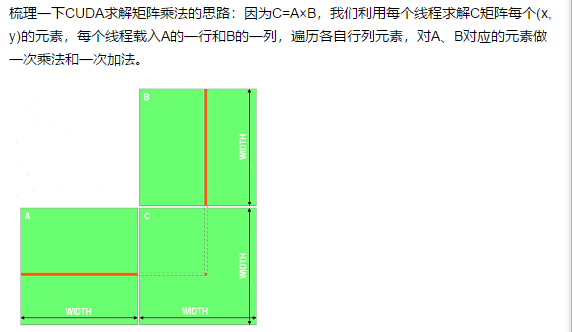
GPU版本:
1 #include "cuda_runtime.h" 2 #include "device_launch_parameters.h" 3 #include <sys/time.h> 4 #include <stdio.h> 5 #include <math.h> 6 #define Row 1024 7 #define Col 1024 8 9 10 __global__ void matrix_mul_gpu(int *M, int* N, int* P, int width) 11 { 12 int i = threadIdx.x + blockDim.x * blockIdx.x; 13 int j = threadIdx.y + blockDim.y * blockIdx.y; 14 15 int sum = 0; 16 for(int k=0;k<width;k++) 17 { 18 int a = M[j*width+k]; 19 int b = N[k*width+i]; 20 sum += a*b; 21 } 22 P[j*width+i] = sum; 23 } 24 25 int main() 26 { 27 struct timeval start, end; 28 gettimeofday( &start, NULL ); 29 30 int *A = (int *)malloc(sizeof(int) * Row * Col); 31 int *B = (int *)malloc(sizeof(int) * Row * Col); 32 int *C = (int *)malloc(sizeof(int) * Row * Col); 33 //malloc device memory 34 int *d_dataA, *d_dataB, *d_dataC; 35 cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col); 36 cudaMalloc((void**)&d_dataB, sizeof(int) *Row*Col); 37 cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col); 38 //set value 39 for (int i = 0; i < Row*Col; i++) { 40 A[i] = 90; 41 B[i] = 10; 42 } 43 44 cudaMemcpy(d_dataA, A, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); 45 cudaMemcpy(d_dataB, B, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); 46 dim3 threadPerBlock(16, 16); 47 dim3 blockNumber((Col+threadPerBlock.x-1)/ threadPerBlock.x, (Row+threadPerBlock.y-1)/ threadPerBlock.y ); 48 printf("Block(%d,%d) Grid(%d,%d). ", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y); 49 matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataB, d_dataC, Col); 50 //拷贝计算数据-一级数据指针 51 cudaMemcpy(C, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); 52 53 //释放内存 54 free(A); 55 free(B); 56 free(C); 57 cudaFree(d_dataA); 58 cudaFree(d_dataB); 59 cudaFree(d_dataC); 60 61 gettimeofday( &end, NULL ); 62 int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; 63 printf("total time is %d ms ", timeuse/1000); 64 65 return 0; 66 }