pip install pyspider 安装成功后需要把 werkzeug 版本降低到 0.16.1 pip install werkzeug==0.16.1 # 查看 pyspider pyspider --help # 启动 pyspider pyspider all
pyspider web界面高度不够
找到pyspider包下面的 debug.min.css 文件
找到
iframe{border-width:0;width:100%}
改为
iframe{border-width:0;width:100%;height:900px; !important}
中文乱码 需要自己在项目中转码一下即可
response.content = (response.content).decode('gb2312') # 目标网站编码
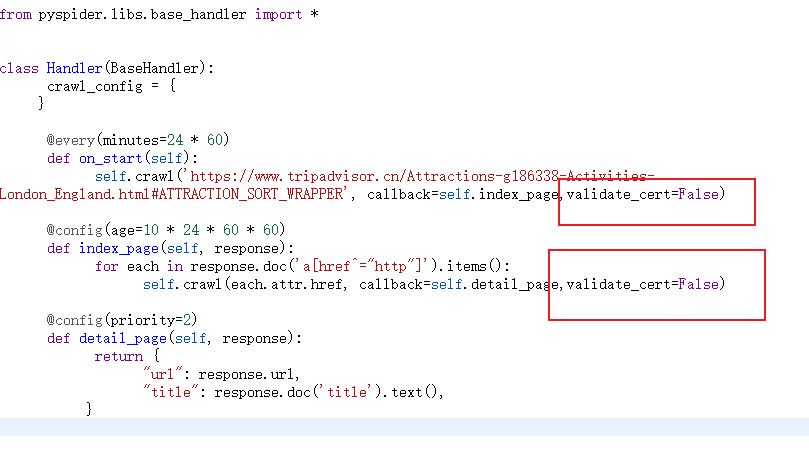
出现ssl证书找不到的错误 599,
只需要在self.crawl()方法中添加
,validate_cert=False
但是有一点得注意,Handler方法中,
不止一个self.crawl()方法,
应在全文中的self.crawl()方法中都添加validate_cert=False.
# 例子: from pyspider.libs.base_handler import * from string import Template # 连接数据库 import pymysql class Handler(BaseHandler): crawl_config = { 'itag':'v235444' } def __init__(self): self.db = pymysql.connect(host='localhost', port=3306,user='root', password='root',db='shootdb',charset='utf8') def save_in_mysql(self, obj): try: cursor = self.db.cursor() #print('obj',obj) sql = Template('INSERT INTO goods(g_date,g_title,g_bigUrl,g_smallUrl,g_class) VALUE("$date","$title","$bigUrl","$smallUrl","$g_class")') sql = sql.substitute(date=obj.get('date'),title=obj['title'],bigUrl=obj['BigUrl'],smallUrl=obj['smallUrl'],g_class=obj['g_class']) #sql = 'INSERT INTO table(date,title,url) VALUES ()' # 插入数据库的SQL语句 print(sql) cursor.execute(sql) self.db.commit() except Exception as e: #print(e) self.db.rollback() @every(minutes=24 * 60) def on_start(self): self.crawl('http://www.ry520.com/photo/list_5.html', callback=self.index_page,validate_cert=False) # 进入大图页面,爬取大图字段信息 @config(age=10 * 24 * 60 * 60) def index_page(self, response): for b,each in enumerate(response.doc('.a-zuopin li a').items()): doc = { 'BigUrl':each.attr.href, 'title':each.find('.cite h3').text(), 'date':each.find('.cite p').text(), 'smallUrl':[], 'g_class':'婚纱客照' } #print(each.attr.href) a = each.find('img').attr.src self.crawl(a,callback=self.bigImg,save=[doc,b+19],validate_cert=False) #self.save_in_mysql(doc) def bigImg(self,response): self.crawl(response.save[0]['BigUrl'],callback=self.smallImg,save=[response.save[0],response.save[1],'/images/Wedding/WeddingGuestBig-'+ str(response.save[1]) +'.jpg'],validate_cert=False) def smallImg(self,response): obj = response.save[0] for i,each in enumerate(response.doc('.entry img').items()): detail = '/images/Wedding/WeddingGuestBig-'+ str(response.save[1])+ '-' + str(i+1) +'.jpg' #print(detail) obj['smallUrl'].append(detail) obj['BigUrl'] = response.save[2] self.save_in_mysql(obj)