一、搭建规划
使用4台CentOS-7进行集群搭建
|
主机名 |
IP地址 |
角色 |
|
master |
192.168.56.100 |
NameNode,JournayNode |
|
slave1 |
192.168.56.101 |
NameNode,DataNode,ResourceManager,NodeManager,zooKeeper,JournayNode |
|
slave2 |
192.168.56.102 |
DataNode,,ResourceManager,NodeManager,zooKeeper,JournayNode |
|
slave3 |
192.168.56.103 |
DataNode,NodeManagerr,zooKeeper,JournayNode,JobHistoryServer |
规划用户:root
规划安装目录:/opt/hadoop/apps
规划数据目录:/opt/hadoop/data
二、准备工作
已完成全分布式搭建,参考:https://www.cnblogs.com/lina-2015/p/14355664.html
1.两个namenode可以相互免密登录
#master已经可以免密登录slave1了,还需设置slave1免密登录master #在slave1端的操作 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cp ~/.ssh/id_dsa_pub ~/.ssh/slave1_pub scp ~/.ssh/slave1_pub master:~/.ssh/ rm ~/.ssh/slave1_pub #在master端的操作 cat ~/.ssh/slave1_pub >> ~/.ssh/authorized_keys
2.ZooKeeper集群
2.1解压包
#解压 zxvf tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/hadoop/apps/zookeeper
2.2配置文件
#1.分别在slave1,slave2,slave3配置myid cd /opt/data/zookeeper #slave1操作 vim myid 1 #slave2操作 vim myid 2 #slave3操作 vim myid 3 #2.在conf配置zoo.cfg cp zoo.cfg.template zoo.cfg vim zoo.cfg tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/hadoop/data/zookeeper # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 server.1=c1:2888:3888 server.2=c2:2888:3888 server.3=c3:2888:3888 #说明:2888是集群间通讯的端口,3888是选举的端口
#3.设置环境变量
vim ~/.bashrc
export ZOOKEEPER_HOME=/opt/hadoop/apps/zookeeper-3.4.6/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source ~/.bashrc
2.3测试
zkServer.sh start #启动
zkServer.sh status #查看状态
zkServer.sh stop #停止
三、搭建工作
1.修改配置
1.1修改core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> <description>集群的名称是mycluster</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>slave1:2181,slave2:2181,slave3:2181</value> </property>
1.2修改hdfs-site.xml
#删除secordaryNameNode的配置信息
#<property> # <name>dfs.namenode.secondary.http-address</name> # <value>slave1:50090</value> #</property>
#新增 <property> <name>dfs.nameservices</name> <value>mycluster</value> <description>Nameservices: 服务的逻辑名称</description> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> <description>nameserviecs对应的namenode</description> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master:8020</value> <description>Namenode RPC地址:</description> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>slave1:8020</value> <description>Namenode RPC地址:</description> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master:50070</value> <description>Namenode HTTP Server配置</description> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>slave1:50070</value> <description>Namenode HTTP Server配置</description> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value> <description>edit log保存目录,也就是Journal Node集群地址,分号隔开</description> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop/data/ha/jn</value> <description>edit日志保存路径</description> </property> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>客户端故障转移代理类,目前只提供了一种实现</description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>fencing方法配置</description> </property> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
3.设置yarn-site.xml
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>slave1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>slave1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave2:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>slave1:2181,slave2:2181,slave3:2181</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name> <value>/yarn-leader-election</value> <description>Optional setting. The default value is /yarn-leader-election</description> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> <description>Enable automatic failover; By default, it is enabled only when HA is enabled.</description> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>slave1:8132</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>slave2:8132</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>slave1:8130</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>slave2:8130</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>slave1:8131</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>slave2:8131</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>slave1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave2:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志保留时间(7天) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
2.初始化
#1.在slave1,slave2,slave3上启动zookeeper zkServer.sh start #2.在master,slave1,slave2上启动日志节点 hadoop-daemon.sh start journalnode #3.在master或slave1上格式化并启动namenode,另外一个节点同步 hdfs namenode -format#如果从来没有格式化过,如果格式化过了,可以不用格式化 hadoop-daemon.sh start namenode hdfs namenode -bootstrapStandby #4.初始化ZKFC
hdfs zkfc -formatZK
#5.在master启动集群
start-all.sh
#如果自己登陆自己失败,试一下ssh master
#如果resourcemanager没有启动成功,需要手动启动和关闭,可以修改start-yarn.sh和stop-yarn.sh
#在start-yarn.sh中,将"$bin"/yarn-daemon.sh --config $YARN_CONF_DIR start resourcemanager
#修改成"$bin"/yarn-daemons.sh --config $YARN_CONF_DIR start resourcemanager
#yarn-deamon.sh是在本节点启动,yarn-daemons.sh是在所有节点启动
#参考网址:https://blog.csdn.net/pineapple_C/article/details/108812317
#6.启动日志服务器
mr-jobhistory-daemon.sh start historyserver
3.验证
#master下的进程 [root@master sbin]# jps 4304 JournalNode 4099 NameNode 4474 DFSZKFailoverController 4636 Jps #slave1下的进程 [root@localhost sbin]# jps 3536 NameNode 3698 JournalNode 3604 DataNode 4136 Jps 3899 ResourceManager 3821 DFSZKFailoverController 830 QuorumPeerMain 3966 NodeManager #slave2下的进程 [root@localhost sbin]# jps 2178 JournalNode 2645 Jps 2087 DataNode 714 QuorumPeerMain 2269 ResourceManager 2334 NodeManager #slave3下的进程 [root@localhost sbin]# jps 32755 QuorumPeerMain 1667 Jps 1637 JobHistoryServer 1270 DataNode 1453 NodeManager
查看master节点和slave1节点的webUI
master http://master:50070
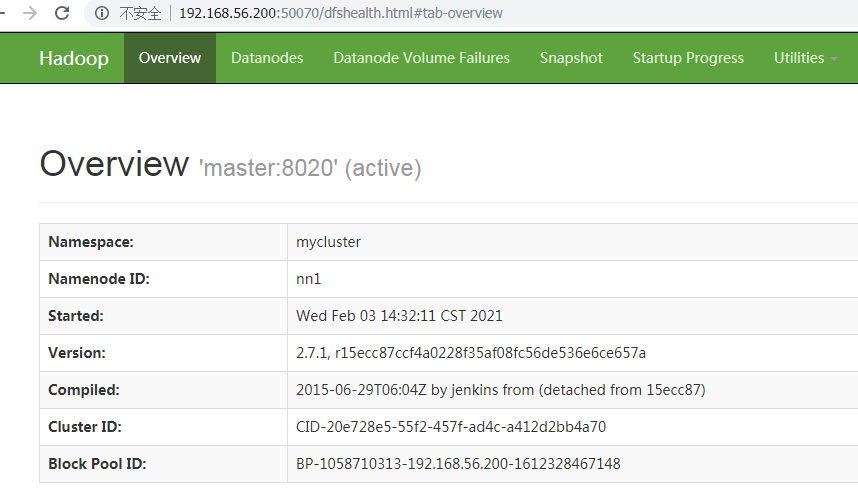
slave1 http://slave1:50070
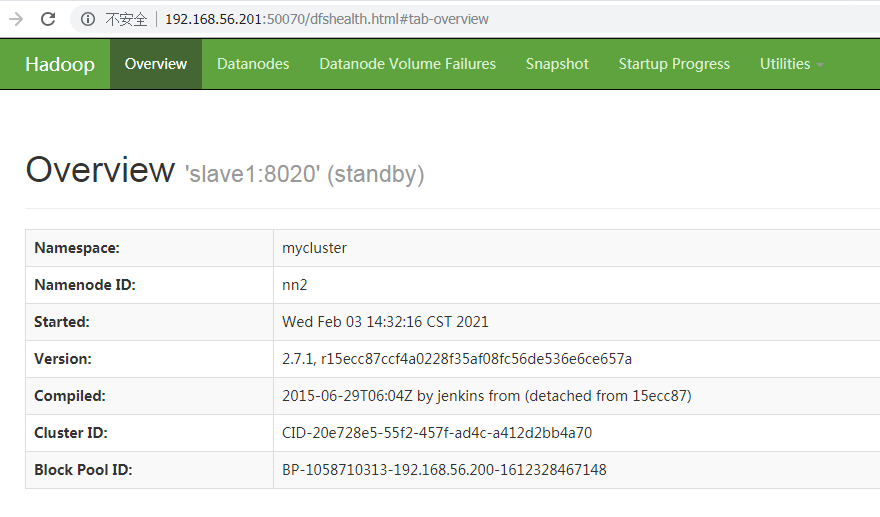
停止其中active的那台,查看页面变化
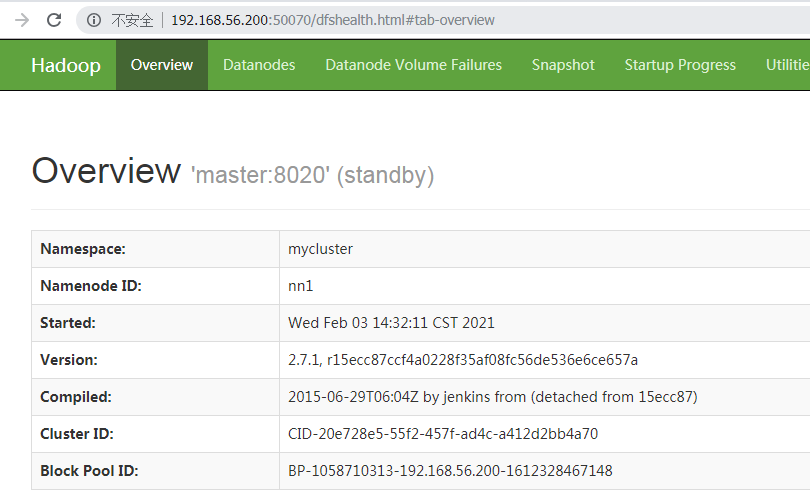
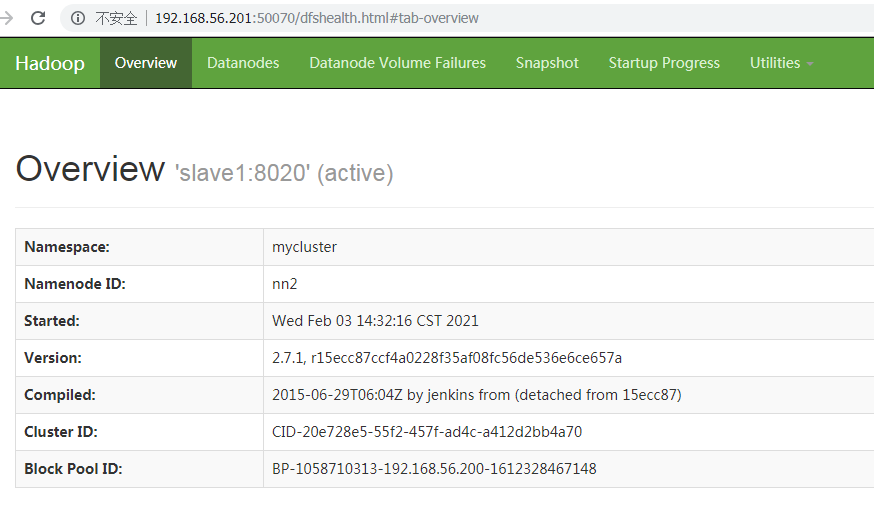
4.日常启动和停止
#启动集群 start-all.sh #查看master,slave1,slave2,slave3的进程 jps #停止集群 stop-all.sh
#启动日志服务器
mr-jobhistory-daemon.sh start historyserver