爬虫基础
目录
一、什么是爬虫
爬虫是一种应用程序,用于从互联网中获取有价值的数据,从本质上来看,属于client客户端程序。
二、爬虫的原理
通常我们所谓的上网,其实本质就是用计算机通过网络去访问另一台计算机上的数据,而这些数据通常以网页的形式存在于服务器上,网页本质上就是一个文本文件,要想得到有价值的数据,第一步就是要得到这些网页数据,这就需要分析浏览器与服务器之间到底是如何通讯的,然后模拟浏览器来与服务器通讯,从而获取数据。当然爬虫不仅限于爬取网页,还可爬取移动设备常用的json数据等等,以及其他格式的二进制数据等等。
三、爬虫的目的
互联网中最宝贵的就是数据了,例如淘宝的商品数据,链家的房源信息,拉钩的招聘信息等等,这些数据就像一座矿山,爬虫就像是挖矿的工具,掌握了爬虫技术,你就成了矿山老板,各网站都在为你免费提供数据。
四、爬虫爬取的过程
模拟浏览器 -- 获取服务器返回的数据 -- 解析数据 -- 存储
五、爬虫与HTTP协议
首先爬虫的核心原理就是模拟浏览器发送HTTP协议来获取服务器上的数据,那么要想服务器接受你的请求,则必须将自己的请求伪装的足够像,这就需要我们去分析浏览器是如何发送的HTTP请求
其次:HTTP协议是基于请求响应模型的,客户端发送请求到服务器,服务器接受请求,处理后返回响应数据,只有服务器认为合格合法的请求才会得到服务器的响应。
六、请求流程
1、请求地址url
浏览器发送的请求URL地址
2、请求方法
get 中文需要URL编码,参数跟在url后面
post 参数放在body中
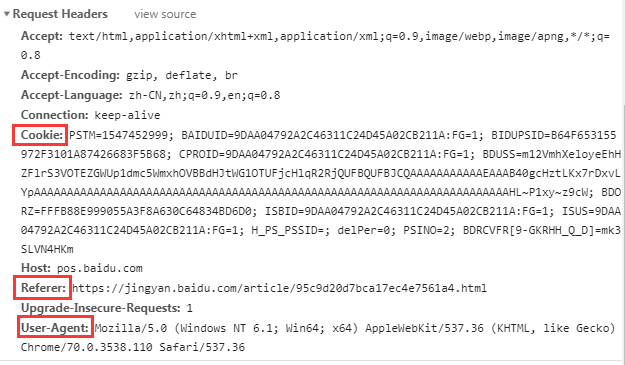
3、请求头
请求的头部,包括了cookie、user-agent、referer信息
cookie 用于识别用户的身份,通常在访问一些私有的页面时需要使用cookie
user-agent 用户代理,用于标识是由什么客户端发起的请求,一般不同浏览器的用户代理不同
referer 引用页面,判断是从哪个页面点击过来的
4、请求体
只在 post 请求时需要关注,通常post请求参数都放在请求体中,例如登录时的用户名和密码
5、响应头
1. location 重定向的目标地址,仅在状态码为3XX时出现,需要考虑重定向时的方法,参数等,浏览器会自动重定向,request模块也会
2. set-cookie 服务器返回的cookie信息,在访问一些隐私页面是需要带上cookie
6、响应体
服务器返回的数据,可能以下几种类型:
1. HTML格式的静态页面 需要解析获取需要的数据
2. json个格式的结构化数据 直接就是纯粹的数据
3. 二进制数据 通过文件操作直接写入文件
七、爬取梨视频
import requests
import re
base_url = 'https://www.pearvideo.com/'
def get_index():
res = requests.get(base_url, headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'referer': 'https: // www.baidu.com / link?url = fUq54ztdrrLaIUXa - p6B9tuWXC3byFJCyBKuvuJ_qsPw8QLrWIfekFKGgmhqITyF & wd = & eqid = c5366da10000199a000000025c45768a"'
})
# print(res.text)
return res.text
def parse_index(text):
res = re.findall('<a href="(.*?)" class="actcont-detail actplay">', text)
# print(res)
urls = [base_url + i for i in res]
# print(urls)
return urls
def get_details(url):
res = requests.get(url)
# print(res.text)
return res.text
def parse_details(details):
title = re.search('<h1 class="video-tt">(.*?)</h1>', details).group(1)
print(title)
date = re.search('<div class="date">(.*?)</div>', details).group(1)
count = re.search('<div class="fav" data-id=".*?">(.*?)</div>', details).group(1)
content = re.search('<div class="summary">(.*?)</div>', details).group(1)
# print(title, date, count, content)
dic = {'title': title, 'date': date, 'count': count, 'content': content}
return dic
if __name__ == '__main__':
data = get_index()
videos_urls = parse_index(data)
for videos_url in videos_urls:
details = get_details(videos_url)
details_dic = parse_details(details)
print(details_dic)
八、模拟GitHub登录
"""
1.请求登陆页面 获取token cookie
2.发生登陆的post请求,将用户名密码 和token 放在请求体中,cookie放在请求头中
"""
import requests
import re
login_url = "https://github.com/login"
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
res1 = requests.get(login_url,headers=headers)
print(res1.status_code)
# 从响应体中获取token
token = re.search('name="authenticity_token" value="(.*?)"',res1.text).group(1)
print(token)
# 保存cookie
login_cookie = res1.cookies.get_dict()
print(login_cookie)
# 发送登陆请求
res2 = requests.post("https://github.com/session",
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"},
cookies = login_cookie,
data={
"commit": "Sign in",
"utf8": "✓",
"authenticity_token": token,
"login": "xxxxxx",
"password": "xxxxxxxxxx"},
# 是否允许自动重定向
allow_redirects = False)
print(res2.status_code)
# 用户登录成功后的cookie
user_cookie = res2.cookies.get_dict()
# 访问主页
res3 = requests.get("https://github.com/settings/profile",cookies = user_cookie,headers = headers)
print(res3.status_code)
print(res3.text)
# "https://github.com/settings/profile"