在学习xpath()的过程中,除了学习xpath的基本语法外,我们最先遇到的往往是文档的格式化问题!因为只有正确格式化之后的文档,才能准确利用xpath寻找其中的关键信息。
对于文档格式化的问题,可能不同的人,会遇到不一样的情况,但是基本上只要搞懂了lxml.etree.HTML(),lxml.etree.fromstring()和lxml.etree.tostring()这三者之间的区别和联系,那么文档格式化这一步一定不会有问题!
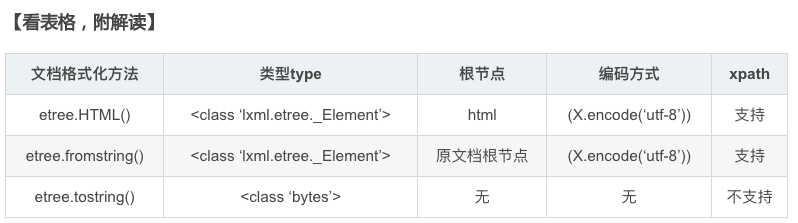
表格解读:
1.从三者的类型上可以看到,etree.HTML()和etree.fromstring()都是属于同一种“class类”,这个类型才会支持使用xpath。也就说etree.tostring()是“字节bytes类”,不能使用xpath!
2.从根节点看,etree.HTML()的文档格式已经变成html类型,所以根节点自然就是html标签【这属于html方面的知识点,不清楚的朋友可以查资料了解】
但是,etree.fromstring()的根节点还是原文档中的根节点,说明这种格式化方式并不改变原文档的整体结构,我比较推荐使用这种方式进行文档格式化,因为这样有利于我们有时使用xpath的绝对路径方式查找信息!
而etree.tostring()是没有所谓的根节点的,因为这个方法得到的文档类型是‘bytes’类,其实里面的tostring,我们可以理解成to_bytes,这样可以帮助理解记忆。
3.从编码方式上看,etree.HTML()和etree.fromstring()的括号内参数都要以“utf-8”的方式进行编码!表格中的X是表示用read()方法之后的原文档内容。
为了便于大家理解,我下面举个实例:
import lxml.etree as le with open(‘books.xml’,’r’,encoding=‘utf-8’) as b: contents=b.read() contents_html=le.HTML(contents.encode(‘utf-8’)) co_ht_xpath=contents_html.xpath(‘/*’) print(co_ht_xpath)
上面这段代码是典型的使用xpath()方法查找网页内容的步骤,表格中所写的X就是上面代码中的contents,这里的contents本质上是一个包含books.xml文档内所有内容的长字符串。
由于这个长字符串里,往往含有各种特殊符号或中文汉字等,所以必须对这个长字符串contents以‘utf-8’方式进行编码,那么才不会因无法识别而出现乱码的情况。如果这里没有用encode(‘utf-8’)进行编码,那么使用etree.HTML()和etree.fromstring()时,程序都会报错!