1.列表list的性质:
- 一个队列,一个排列整齐的队伍,有序的
- 列表内的个体称作元素,由若千元素组成列表
- 元素可以是任意对象(数字、字符串、对象、列表等)
- 列表内元素有顺序,可以使用索引
- 线性的数据结构
- 使用 [ ] 表示
- 列表是可变的,可增加可减少
- 列表list、链表、queue、stack的差异,链表不一定是线性的,不能使用索引;queue是队列,先进先出后进先出等;stack是后进先出的队列。
2.定义和初始化:
1 >>> lst = list() 2 >>> lst 3 [] 4 >>> lst = [] 5 >>> lst 6 [] 7 # 空列表 8 >>> list(range(5)) 9 [0, 1, 2, 3, 4] 10 # list(可迭代),比如说range()
3.列表的索引访问:
- 索引,即下标。正索引:从左到右,从0开始,为列表中每一个元素编号;负索引:从右到左,从-1开始。
- 正负索引不可以越界,否则会引发异常IndexError。
- 为了方便理解,可以认为列表是从左至右排列的,左边是头部,右边是尾部,左边是下界,右边是上界。
- 列表通过索引访问。list[index],index就是索引,list[5]即表示访问列表中的第6个元素。
4.列表查询:
- index(value,[start,[stop]]):value是给出的值,一般是从左到右的顺序从指定区间查找列表内的元素是否匹配,如果该列表中有多个相同的value,匹配到第一个value值就立即返回索引;匹配不到的话就抛出异常ValueError。注意这里的[stop]中的中括号是可有可无的意思。
- 例子:list=['a',2,7,9,2,7],list.index(2)的结果是1,list.index(7)的结果是2。可以看出是从左到右的查找顺序,注意正索引是从0开始的。list.index(2,2)这个语句是什么意思呢?第一个2是value,是想要寻找的数值,第二个2则是start,是指定区间的开始,从例子上看,也就是从索引为2的list中寻找2,list中索引为2的value是第一个7,从第一个7开始从左往右查询,那么第5个数才是要寻找的value,即list.index(2,2)的值为4。这里的查找区间从start开始,默认查找到最后,如果有stop的话,那么查找区间以stop结束。
- count(value):例子:list=['a',2,7,9,2,7],list.count(9)的结果是1,list.count(7)的结果是2,这个是统计列表中value个数的。
- 时间复杂度O(n):一个列表有随即的n个元素,要统计count()某一个元素的个数时,需要将该列表中的所有元素遍历一遍,所消耗的时间为O(n)。O(1)是最理想的,效率最高。列表规模越大,效率越低下。
- 计数器:该如何知道一个列表的长度呢?即如何知道列表中有多少个元素?最直接的办法就是将列表遍历一次,统计个数,但是这样的话,如果有成千上万个元素的话,效率会非常低下。在这里数据结构在建立列表时,会有一个计数器来单独统计列表中元素的个数,每当该列表增减元素时,该计数器会相应的加减,想要查询该列表的长度,直接调用该计数器即可,这里时间复杂度就达到了所谓的O(1),效率非常高。
- 内置函数len():例子:list=['a',2,7,9,2,7],len(list)的结果是6,表示该列表中共有6个元素。
5.列表元素修改:
- list[index] = value,索引不要越界。
- append(object) ->None,元素追加
- 列表尾部追加元素,返回None。list=['a',2,7,9,2,7],list.append(10),list变为['a',2,7,9,2,7,10]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- 时间复杂度是O(1)
- insert(index,object) ->None,元素插入
- 在指定的索引index处插入元素object。list=['a',2,7,9,2,7],list.insert(3,'b'),在list索引为3的位置(即元素9前面)插入一个元素b,list变为['a', 2, 7, 'b', 9, 2, 7]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- 时间复杂度是O(1)
- 插入时候越界问题:超越上界,尾部追加。list.insert(100,'b'),list变为['a',2,7,9,2,7,'b'];超越下界,头部追加。list.insert(-100,'b'),list变为['b','a',2,7,9,2,7]
- + -> list,连接操作
- 将两个列表连接起来。list1 = [1,2,3],list2 = ['a','b','c'],那么list1 + list2的输出为:[1,2,3,'a','b','c']
- 产生新的列表,原列表不变
- 本质上调用的是_add_()方法
- * -> list,重复操作
- 将本列表的元素重复n次。list = [1,2,3],list * 3的输出为[1,2,3,1,2,3,1,2,3]
- 产生新的列表,原列表不变
- extend(iteratable) -> None
- 将可迭代对象的元素追加进来,返回None。list1 = [1,2],list2 = ['a','b'],那么list1.extend(list2),list1列表变为[1,2,'a','b'],list2列表不变。
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- clear() -> None,元素删除
- 清除列表的所有元素,剩下空列表。list = [1,6,3,5,7],那么list.clear(),list变为[]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- remove(value) -> None,元素删除
- 从左到右查找第一个匹配value的值,移除该元素,返回None。list = [2,4,6,3,4],那么list.remove(4),list变为[2,6,3,4]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- 效率比较低下
- pop([index]) -> item,元素删除
- 不指定index的话,就删除列表的最后一个元素。list = [1,5,3,6],list.pop()的结果为6,list变为[1,5,3]
- 指定index,从索引处删除一个元素,索引越界报IndexError错误。list = [1,5,3,6],list.pop(2)的结果为3,list变为[1,5,6]
- pop()效率高,pop(index)效率低
- reverse() -> None,反转操作
- 就列表进行反转。list = [1,'a','c',4,6],那么list.reverse(),list变为[6,4,'c','a',1]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- sort(key=None,reverse=False) -> None
- 对列表元素进行排序,默认升序。list = [5,3,7,2,9,2,6,9],那么list.sort(),list变为[2,2,3,5,6,7,9,9]
- reverse为True,反转后变为降序。list = [5,3,7,2,9,2,6,9],那么list.sort(reverse=True),list变为[9,9,7,6,5,3,2,2]
- None表示没有新的列表产生,就地修改,当前的列表发生变化
- key一个函数,指定key如何排序。list = [5,20,7,'b',2,10,500,9,'a'],如果此时list.sort()的话是会报错的,元素类型不统一,那么需要list.sort(key=str),按照字符串的形式默认升序排列,此时列表里面的数字元素都会转变成ASCII码,list变为[10,2,20,5,500,7,9,'a','b'];降序的话需要list.sort(key=str,reverse=True),list变为['b','a',9,7,500,5,20,2,10]
- in
- 返回的是布尔型True和False,可以应用于判断条件。list = [4,6,33,5],33 in list输出结果为True,100 in list输出结果为False
- for x in [4,6,33,5,'a']
6.列表复制:
copy() -> list
- copy返回的是一个新的列表,具体看以下代码。
- shadow copy,影子拷贝,也叫浅拷贝,遇到引用类型,只是复制了一个引用而已。
1 >>> lst0 = list(range(4)) 2 >>> lst0 3 [0, 1, 2, 3] 4 >>> lst2 = list(range(4)) 5 >>> lst2 6 [0, 1, 2, 3] 7 >>> id(lst0) 8 56095848 9 # id()是查看在内存中的位置 10 >>> id(lst2) 11 56096248 12 # 这里可以看出lst0和lst2在内存中不是一个位置 13 >>> hash(lst0) 14 Traceback (most recent call last): 15 File "<stdin>", line 1, in <module> 16 TypeError: unhashable type: 'list' 17 # 列表不可进行哈希运算 18 >>> hash(id(lst0)) 19 56095848 20 >>> hash(id(lst2)) 21 56096248 22 # 正整数的哈希值是其本身 23 >>> lst0 == lst2 24 True 25 # ==比较的左右两边的内容,返回结果为True 26 >>> lst0 is lst2 27 False 28 # is还比较左右两边在内存中的位置,返回结果为False 29 >>> lst1 = lst0 30 >>> lst1 31 [0, 1, 2, 3] 32 >>> lst0 33 [0, 1, 2, 3] 34 >>> lst1[2] = 10 35 >>> lst1 36 [0, 1, 10, 3] 37 >>> lst0 38 [0, 1, 10, 3] 39 >>> id(lst1) 40 56095848 41 # 这里可以看出lst1 = lst0,lst0把在内存中的位置也给了lst1 42 # lst1发生变化的时候,lst0同步跟随变化
1 >>> lst0 = list(range(4)) 2 >>> lst5 = lst0.copy() 3 >>> lst5 == lst0 4 True 5 >>> lst5[2] = 10 6 >>> lst5 7 [0, 1, 10, 3] 8 >>> lst0 9 [0, 1, 2, 3] 10 >>> lst5 == lst0 11 False 12 # copy()的只是内容,创建一个新的列表,lst5发生变化,lst0原列表不变
1 >>> lst0 = [1,[2,3,4],5] 2 >>> lst5 = lst0.copy() 3 >>> lst5 4 [1, [2, 3, 4], 5] 5 >>> lst5 == lst0 6 True 7 >>> lst5[2] = 10 8 >>> lst5 == lst0 9 False 10 # 这里在上段代码中阐述了,copy创建的是新列表,新列表改变,原列表不变 11 >>> lst5[1][1] = 20 12 >>> lst5 13 [1, [2, 20, 4], 10] 14 >>> lst5 == lst0 15 True 16 >>> lst0 17 [1, [2, 20, 4], 5] 18 # 这里lst5[1]是一个列表[2,3,4],修改了该列表的第二个元素变为[2,20,4] 19 # 可以看到lst0对应的位置也发生了改变,这是为什么呢? 20 # copy()在拷贝的时候,看见lst0的第二个元素是个复杂的元素,因此并不是将[2,3,4]这个列表的各个元素拷贝过来,而是将该表在内存中的位置拷贝过来了 21 # 因此lst5里面第二个复杂的元素变化的时候,其实就是它在内存中发生了变化,lst0也就同步发生了变化 22 # 对比与上述代码的差异
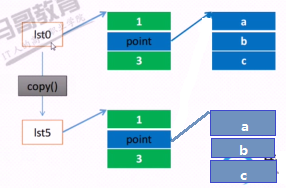
来看一下上图代码的结构图,这就是影子拷贝。其中一个修改point的时候,两者同步发生了同样的变化。

- 深拷贝,copy模块提供了deepcopy
1 >>> import copy 2 >>> lst0 = [1,[2,3,4],5] 3 >>> lst5 = copy.deepcopy(lst0) 4 >>> lst5[1][1] = 20 5 >>> lst5 == lst0 6 False 7 >>> lst5 8 [1, [2, 20, 4], 5 9 >>> lst0 10 [1, [2, 3, 4], 5] 11 # 从这里可以看出,深拷贝不管列表有着几层引用,复制所有的最基本的数据形成一个新的列表 12 # 新列表lst5的元素发生了改变,lst0保持不变
看一下深拷贝的结构图:
7.随机数:
- random模块
- randint(a,b)返回[a,b]之间的整数
- choice(seq)从非空序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 random.choice([1,3,5,7])
- randrange([start,] stop [,Step])从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1。 random.randrange(1,7,2)
- random.shuffle(ist) -> None就地打乱列表元素
1 >>> import random 2 # 导入random模块,import的用法 3 >>> random.randint(1,5) 4 1 5 >>> random.randint(1,5) 6 4 7 # randint()随机抽取正整数,这里注意随机数的范围包括两边的边界 8 ####################################### 9 >>> random.choice() 10 Traceback (most recent call last): 11 File "<stdin>", line 1, in <module> 12 TypeError: choice() missing 1 required positional argument: 'seq' 13 # choice()是从给定的集合中随机挑选一个,目前学到的集合只有列表 14 >>> random.choice([1,2,3,4,5]) 15 2 16 >>> random.choice([1,2,3,4,5]) 17 1 18 >>> random.choice([1,2,3,4,5]) 19 5 20 >>> random.choice(range(5)) 21 0 22 >>> random.choice(range(5)) 23 2 24 ######################################### 25 >>> random.randrange(1,7,2) 26 3 27 >>> random.randrange(1,7,2) 28 5 29 >>> random.randrange(1,7,2) 30 1 31 # 这里要注意randrange()的定义与range()是完全一样的 32 # 从1开始到7结束,含1不含7,步长为2,因此这个的随机数只能是1,3,5 33 ######################################### 34 >>> list = [5,54,767,1,5,22,69] 35 >>> list.sort() 36 >>> list 37 [1, 5, 5, 22, 54, 69, 767] 38 >>> random.shuffle(list) 39 >>> list 40 [767, 54, 1, 69, 5, 22, 5] 41 >>> random.shuffle(list) 42 >>> list 43 [5, 767, 1, 69, 22, 5, 54] 44 # 打乱列表元素的顺序