《python编程:从入门到实践》里的部分内容
第2章
单词大小写
单词首部大写
msg2="asdfg"
print(msg2.title())
结果 Asdfg
msg3="asdfg dfg"
print(msg3.title())
结果 Asdfg Dfg
单词全大写
msg3="Asdfg Dfg"
print(msg3.upper())
结果 ASDFG DFG
单词全小写
print(msg3.lower())
结果 asdfg dfg
制表符
换行符
消除字符中的空白
msg4=" a s d "
print(msg4+"'")
输出 ‘ a s d ’
print(msg4.rstrip()+"'") 消除尾部空白
输出 ‘ a s d’
print("'"+msg4.lstrip()+"'") 消除首部空白
输出 ‘a s d ’
print("'"+msg4.strip()+"'") 消除两端空白
输出 ‘a s d’
乘方
3**2 3的2次方 结果为 9
3**3 3的3次方 结果为 27
浮点数
0.2+0.1 结果可能为0.30000000000000004 (需要找一个方法来处理那些多余的小数位)
数字转字符
print("happy "+23+"rd Birthday!") 是错误的,会报错
print("happy "+str(23)+"rd Birthday!") 是正确的
注释
# 单行注释
第3章
数组、列表
testArr=["a","b","c",'d','e']
print(testArr) 结果为 [‘a’, ’b’, ’c’, ’d’, ’e’]
print(testArr[-1]); 结果为 e 数组最后一个元素
尾部添加
testArr.append(“f”) 数组更改为['a', 'b', 'c', 'd', 'e', 'f']
指定位置插入元素
testArr.insert(1,“temp”) 数组更改为['a', 'temp', 'b', 'c', 'd', 'e', 'f']
删除指定位置的元素
del testArr[1] 数组更改为['a', 'b', 'c', 'd', 'e', 'f']
或
testArr.pop(1)
区别:要删除不再使用的数据时使用del,只是从数组中删除,就用pop
尾部删除
testArr.pop() 数组更改为[‘a’, ’b’, ’c’, ’d’, ’e’] 返回删除的元素 f
删除指定的元素
testArr.remove(“c”) 数组更改为[‘a’, ’b’, ’d’, ’e’] 如果有两个c,则只删除第一个c
排序
sort直接改变原数组
cars=["bmw","audi","320","201","101","BMW","Audi"]
cars.sort() 升序
print(cars) 结果为 ['101', '201', '320', 'Audi', 'BMW', 'audi', 'bmw']
cars.sort(reverse=True) 降序
print(cars)[ 结果为 ['bmw', 'audi', 'BMW', 'Audi', '320', '201', '101']
sorted返回排好序的数组,原数组无变化
sorted(cars) 升序,返回值为 ['101', '201', '320', 'Audi', 'BMW', 'audi', 'bmw']
print(sorted(cars,reverse=True)) 降序,返回值为['bmw', 'audi', 'BMW', 'Audi', '320', '201', '101']
tempArr=[2,6,8,7]
tempArr.reverse() 翻转数组
print(tempArr) 结果为 [7, 8, 6, 2]
数组长度
print(len(tempArr)) 结果为 4
第4章
for循环
for value in range(1,5):
print(value) 结果为 1 2 3 4
range(min,max) 生成的数字为 min到max-1 只能是整数
list(range(1,4)) 生成一个1--4的数组 返回的值为 [1,2,3,4]
print(list(range(2,11,2))) 结果为 2,4,6,8,10 参数 min max 每次增加的数值
print(list(range(2,10,2))) 结果为 2,4,6,8
nums1=[1,2,3,4,5,6,7,8,9,0]
print(min(nums1)) 结果为 0 最小数
print(max(nums1)) 结果为 9 最大数
print(sum(nums1)) 结果为 45 所有数的和
squares=[value**2 for value in range(1,11)]
print(squares) 结果为 [1,4,9,16,25,36,49,64,81,100] 将for循环的1---10全都乘以2次方 然后再将值放进数组里
切片/数组截取
jie=[0,1,2,3,4,5]
print(jie[0:3]) #结果为[0,1,2] 参数是startIndex:endIndex 返回从参数startIndex到endIndex之间截取出来的数组,不包括endIndex
print(jie[1:3]) #结果为[1,2] 参数是startIndex:endIndex 返回从参数startIndex到endIndex之间截取出来的数组,不包括endIndex
print(jie[0:]) #结果为[0,1,2,3,4,5] 参数是startIndex: 返回从参数startIndex到结尾处截取出的数组
print(jie[4:]) #结果为[4,5] 参数是startIndex: 返回从参数startIndex到结尾处截取出的数组
print(jie[:3]) #结果为[0,1,2] 参数是:endIndex 返回从头到endIndex截取出的数组 不包含endIndex
print(jie[-3:]) #结果为[3,4,5] 返回从倒数三个长度的数组
print(jie[-3]) #结果为3
print(jie[:]) #复制整个数组 更改复制出的数组时,不会影响原数组
元组
yuanZu=(0,1,2) 元组不可更改某一个值,只能整体更换,重新给元组赋值
第5章
if 语句
if a==b:
执行语句
elif a>b:
执行语句
else:
执行语句
&& and 并且
|| or 或
testArr=[0,1,2,3,4]
检测数组中是否有某值(包含)
print(4 in testArr) 结果为 True
print(6 in testArr) 结果为 False
检测数组中是否没有某值(不包含)
print('a' not in testArr) 结果为 True
print(3 not in testArr) 结果为 False
打印中文报错
如果出现这个错误 syntaxError:non-utf-8 code starting with 'xb6' in file。。。。。。。
则在脚本第一行添加 #coding=gbk,即可正常使用
在if判断时,如果数组为空,则为False,不为空,则为True
第6章
字典
alien={"color":"red","name":"asd"} #创建字典
print(alien) 结果 {'color': 'red', 'name': 'asd'}
alien["pos"]=123 #增加键值对
print(alien) 结果 {'color': 'red', 'name': 'asd', 'pos': 123}
alien["name"]=333 #更改键值对
print(alien) 结果 {'color': 'red', 'name': 333, 'pos': 123}
del alien['pos'] #删除键值对
print(alien)) 结果 {'color': 'red', 'name': 333}
遍历字典
注意,遍历字典时,键值对的返回顺序可能会与存储顺序不同
直接的alien 格式是(key1:value1,key2:value2,key3:value3)
alien.items() 格式是([(key1,value1),](key2,value2)(key3,value3))
alien.items() 的返回值 dict_items([('color', 'red'), ('name', 333)])
for key,value in alien.items():
print(key)
print(value)
遍历字典中所有的键
alien.keys() 的返回值 dict_keys(['color', 'name'])
for key in alien.keys():
print(key)
按顺序遍历字典中所有的键
for key in sorted(alien.keys()):
print(key)
遍历字典中所有的值
alien.values() 的返回值 dict_values(['red', 333])
for key in alien.keys():
print(key)
剔除重复项
alien={"color":"red","name":"asd","name":"asd","name":"asd","name":"asd"}
print(set(alien.values())) 结果为 {'red', 'asd'}
数组跟字典是可以互相嵌套的
第7章
输入
input() 输入的内容在接收后会转为字符串
msg=input("请输入内容") #屏幕上会显示 请输入内容
print(msg) #输入后按回车,会显示输入的内容
字符串转数字 int()
Python中可用while循环
好好利用 break continue
第8章
函数
#创建无参函数
def funcName():
print(“aaaa”)
#调用函数
funcName()
#结果 aaaa
#创建有参函数
def funcName(msg):
print(msg)
#调用函数
funcName(‘aaaa’)
#结果 aaaa
多参数函数
def func(a,b):
print('a: '+a)
print('b: '+b)
func('a','b') 结果 a: a b: b
func('b','a') 结果 a: b b: a
func(b='b',a='a') 结果 a: a b: b (这种方式被称为,关键字实参)
函数中参数设置默认值的时候,跟其他语言的函数差不多
返回值
def return_func(a):
return a
print(return_func('sss'))
结果 sss
在python中,函数的参数为’’,也可传入int类型的值,例如:
def func1(a,b,c=''):
print(a)
print(b)
print(c+2)
func1('a','b',2)
结果为 a b 4
也可以直接将数组传入函数中
def func2(arr):
print(arr)
func2([1,2,3,4,5])
结果为 [1,2,3,4,5]
向函数内传递任意数量的参数
def func(*msg):
print(msg) #这个msg会被认为是一个元组(不论传入是参数是一个还是多个,都会被认为是一个元组)
func('s','a','r','h') 传参方法
结果为 ('s', 'a', 'r', 'h')
但是有的时候需要单个指定参数跟不确定数量的参数共同使用,所以出现了下列情况(多参数/多个参数)
def func(a,*msg):
print(a)
print(msg)
func(‘t’,'s','a','r','h') 传参方法
结果为 t ('s', 'a', 'r', 'h')
模块 (引入/导入)
#引入整个模块
import pizza # import用来引入模块 pizza.py
pizza.func("a",'a1','a2','a3') #func是pizza的一个函数
#引入某个模块的函数
from pizza import func #从pizza中引入func函数
func("a",'a1','a2','a3') #直接调用即可
#引入函数后,别名
如果只引入函数的话,可能会跟其他函数起冲突,这时可以用 as 来给引入的函数起个别名
from pizza import func as fff #从pizza中引入func函数 给它起个别名 fff
fff("a",'a1','a2','a3') #这里的fff 其实就是 pizza里的func
#引入模块后,别名
import pizza as pp #引入模块 pizza 起个别名 pp
pp.func("a",'a1','a2','a3') #这里相当于还是直接用的 pizza.func()
#引入某个模块的所有函数(最好不要用这个方法)
from pizza import *
func("a",'a1','a2','a3')
第9章
类
创建类
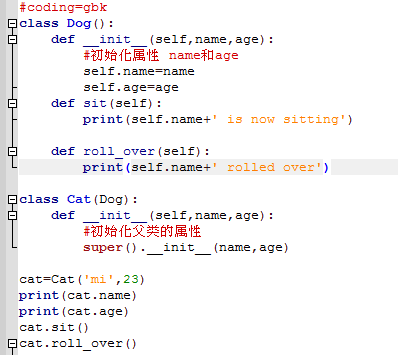
class Dog():
#主函数 self是必备的 name和age是传入的参数
def __init__(self,name,age):
#初始化属性 name和age
self.name=name
self.age=age
def sit(self):
print(self.name+' is now sitting')
def roll_over(self):
print(self.name+' rolled over')
声明类的实例/实例化
同个脚本中
dog=Dog('a',12)
print(dog.name)
print(dog.age)
dog.sit()
dog.roll_over()
不同脚本中
需要先引入类
from dog import Dog #从dog.py中引入Dog类
#然后可以实例化这个类
a_dog=Dog('kit',30)
print(a_dog.name)
也可以直接引入模块,然后用模块.类名
import dog
a_dog=dog.Dog('kit',30)
print(a_dog.name)
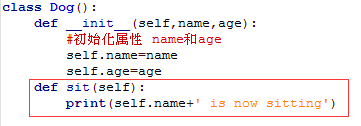
类的继承
同个脚本中
不同脚本

继承之后函数的重写
父类
继承类
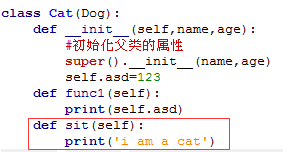
类的组合/类的嵌套
在类Big中嵌套进了类Small1

从同一个脚本中导入多个类(其实跟导入单个类区别不大,用逗号将类名隔开即可)
导入两个类/引入多个类
from big import Big,Small1
big=Big()
small1=Small1()
如果要导入所有类,则
from big import *
似乎跟引入所有函数是同一个写法
标准库
from collections import OrderedDict 类OrderedDict的用法跟字典相同
随机生成一个 1--6的整数
from random import randint
num=randint(1,6)
第10章
读取文件/加载文件
读取整个文件
with open('pi_digits.txt') as file_object:
contents=file_object.read()
print(contents)
open()用来打开文件,参数是文件名(路径)
with的作用:打开文件后,会自动检测文件是否可以关闭,如果可以,将会自动关闭文件(如果用close()手动关闭,可能会因为逻辑或者其他原因导致各类问题出现)
read()用来读取文件的内容(读取文本的话,最后会带一行空行,可以使用rstrip()来清除这个空白行)
注意:虽然加载路径时”/斜线”和”反斜线”都可以用,但是在Linux和OS X中,通常用”/斜线”,在windows中用”反斜线”
windows相对路径
with open('txtpi_digits.txt') as file_object:
contents=file_object.read()
print(contents)
绝对路径
with open('D:lianpi_digits.txt') as file_object:
contents=file_object.read()
print(contents)
逐行读取
方法一:
with open('pi_digits.txt') as file_object:
contents=file_object
for line in contents:
print(line)
print(contents)
方法二:
with open('pi_digits.txt') as file_object:
contents=file_object.readlines()
print(len(contents))
for line in contents:
print(line)
readlines() 会返回一个数组,在数组中,将文件内容的每行分为一个元素
逐行读取后,由于自带换行的关系,所以就多了一些空白行,line.rstrip()即可消除空白行
注:for..in.. read()后的数据就会变成逐字读取
加载小说时报错了,但是不知道原因在哪,只知道删删减减的可能就会又能加载了,跟文件大小没有关系
替换
replace()
msg='哈哈哈哈'
print(msg.replace('哈','呵')) 结果 呵呵呵呵
print(msg) 结果 哈哈哈哈
写入文件
先说下open的参数
Open(filename,type) filename参数名
type分为四种
type =’w’写入模式 (如果有原文件则覆盖,没有则新建)
type=’r’只读模式 (只读。。。)
type=’a’附加模式 (如果有原文件则添加内容,没有则新建)
type=’r+’读写模式 ()
如果不写第二个参数,则默认为只读模式
简单的写入,写入模式的情况下,如果路径下存在save.txt则覆盖该文件,如果不存在则创建该文件
with open('save.txt','w') as file:
file.write('有内容吗?')
保存文本时,可以指定文本的编码格式
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+' ')
异常
try:
print(5/0)
except ZeroDivisionError:
print('ZeroDivisionError~~~~')
异常处理的写法 try...except...代码块 except后面的参数,到需要处理异常的时候根据异常提示看是什么异常再进行对应添加即可
try...except...else 可以混用

如果想要程序在发生异常时直接跳过,可以使用pass
try:
~~~
except ValueError:
pass
文本转数组/str to array

使用split()方法,将str转成数组
查看某字符串在文本内容中出现过多少次,可以使用count()方法

Json的读写/json读写
存储.json类型的文件

json.dump()有两个参数,第一个参数是要存储的数据,第二个参数是可用于存储数据的文件对象
读取.json类型的文件
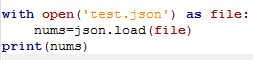
json.load()的参数的要读取的文件对象,返回这个文件的内容
第11章
测试代码
测试函数
import unittest #引入测试模块
from name_function import nameAddFunc #引入要被测试的函数
class NamesTestCase(unittest.TestCase): #新建继承测试模块的类用于测试
def test_name(self):
nameStr=nameAddFunc('a','b','c') #调用函数
self.assertEqual(nameStr,'a cb') #测试函数的实际返回值跟预测的正确结果是否相同
unittest.main() #开始测试
测试结果为成功时显示下面的内容
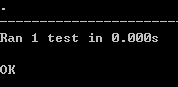
测试类
unittest.TestCase中的各种断言方法
assertEqual(a,b) 核实a==b
assertNotEqual(a,b) 核实a!=b
assertTrue(x) 核实x为True
assertFalse(x) 核实x为False
assertIn(item,list) 核实item在list中
assertNotIn(item,list) 核实item不在list中
