综述:
ARM CPU的架构都基于big.LITTLE大小核技术。而再big.LITTLE的基础上,又添加了DynamIQ。单一Cluster中可以又8个core,且支持不同架构的core,以及支持不同的clk。从而提升了工作效率和配置弹性。
以下利用网上的图片来说明DynamIQ的工作原理:
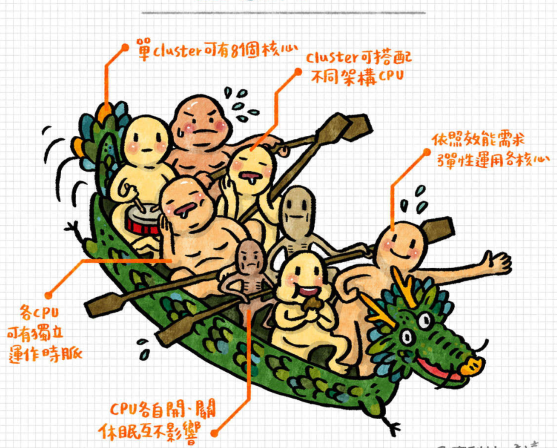
(上图解释为:DynamIQ支持多颗不同架构的处理器,也能让处理器各自在不同的clk下工作)
1、DynamIQ是ARM一个新的底层solution,用于连接在一个芯片上的不同core。
有了DynamIQ,我们可以将不同类型的core放到一个cluster中。比如,将性能高的core,和功耗低的core放进一个cluster。如果没有DynamIQ,我们是将其放在2个不同cluster中的。
最常见 4个Cortex-A72 核与4个Cortex-A53核,或者4个Cortex-A53与另外的4个Cortex-A53核配对。
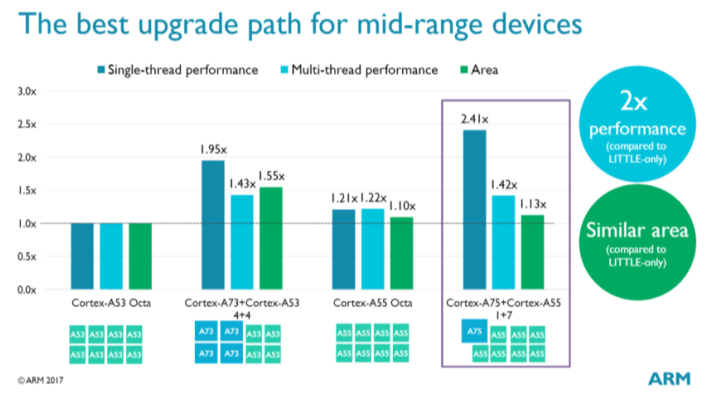
把核心放在同一个cluster中能保证核与核之间更好的通信。
2、DynamIQ的cluster也可以与其他不同的DynamIQ cluster配对。DynamIQ cluster还可以应用了ARMv8.2架构和DynamIQ Share Unit hardware,目前支持的平台有:Cortex-A76, Cortex-A75, Cortex-A55
比如:QCOM Krait385 Gold配合三星M3核集成至SDM845中;而三星Exynos9810则使用Cortex-A75作为base结构。海思麒麟98和SDM855使用Cortex-A76作为base结构。
DynamIQ 的Key Feature
1、Single cluster Design
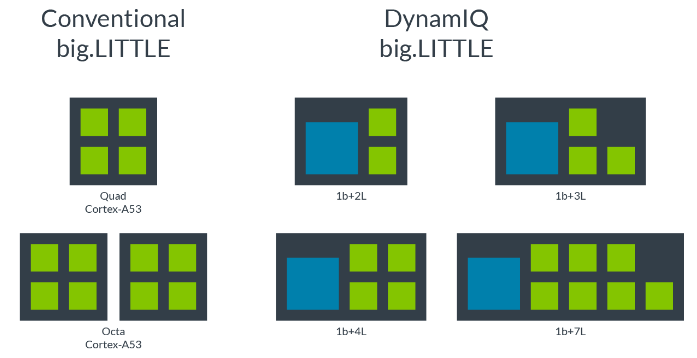
就是大小核可以放在同一个簇里。每个核可以按照各自需求工作在不同的频率,也可以单独的控制每个核开关。
虽然可以有8个不同频率的核,但是实现起来,会带来更多的cost。
2、Power Saving Featues
把所有核到放到同一个簇里,可以降低memory latency,并且简化了核与核之间的tasks sharing。LITTLE核是对memory latency非常敏感的。换句话说,就是在不增加功耗的前提下,提升性能。ARM也让核能更快的下电,进一步省电了。
3、Advance compute capablities
基于DynamIQ技术的Cortex A系列CPU能带来在AI和机器学习上更强大的计算能力。基于DynamIQ的系统能在AI的性能上提供50倍boost。
Meet the DynamIQ Shared Unit
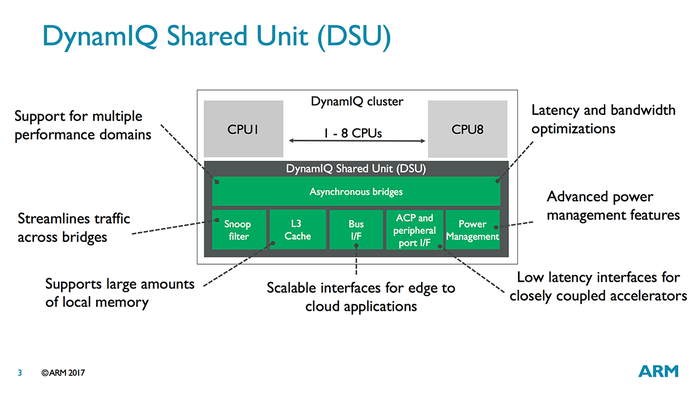
所有弹性的设计架构都仰仗着DynamIQ Shared Unit(DSU)。它构建了CPU、L3 cache、Snoop Filter、外围设备总线buses、power management features之间Asynchronous (异步)通信的桥梁。DSU的设计同时也起到了节省功耗和时间的作用。
1、DynamIQ中首次允许设计带有L3 cache的ARM SOC。这块memeory pool被簇中的所有核共享,它最大的好处是在于能简化big核与LITTLE核之间的task sharing,同时减少memory latency。
2、 L3 cache是16路相联的缓存,可以配置0KB~4MB大小。memory setup是高度专用的,仅有一小部分被L1、L2、L3共享。L3 cache最多可以分成4块partition,这样可以避免cache chrashing、不同进程使用同一块内存等。并且partition可以通过软件进行动态分配。
ARM也实现了对不用的partition进行下电,以此来省电。当一个boot up 单个CPU时,也不会需要所有内存系统为了短暂的过程,都上电起来。L3 cache的power control是Energy Aware Scheduling。
L3 cache的引入也促进了L2 cache的速度。这是考虑到使用高latency的异步bridges的使用,ARM也优化了L2的memory latency。
为了提高performance和充分利用新的memory子系统,ARM也在DSU中使用了cache stashing。它允许相近的coupled accelerators和I/O agents 对部分CPU memory进行direct access(direct读写每一个核的shared L3/L2 caches)。

思路是这样的:peripherals和accelerator的需要CPU进行快速处理的信息,可以以最小的latency,直接inject到CPU的memory中;而不是通过高latency的RAM读写或者prefetch。包括network系统的包处理,与DSP、虚拟加速器的通信,或者是VR应用所使用的视觉捕捉芯片的数据。这钟就是基于特定应用的new feature,但能给SOC和designers更灵活、更强大的潜在性能提升。
回到功耗部分,不同CPU集成到一个cluster,这需要重新考虑一套通过DynamIQ来管理功耗和频率的方法。可选的异步bridges的使用,就可以在单个core的基础上配置的CPU clk domains;而之前只能基于单个cluster控制。Designer也可以选择core的频率与DSU的速度同步。
换句话说,通过DynamIQ,每个CPU理论上都可以跑在自己所需的频率上。而事实上,相同类型的core更多地是绑定到同一个domain group组,同步控制频率和电压,因此功耗是是按group组控制的,而非以单个core。ARM表示:big.LITTLE需要big cores和LITTLE cores分别动态的进行分频和分压。

这会对thermal limited的use case非常有帮助,比如手机,因为它能保证big和LITTILE cores能根据work loading持续地进行power scaled,即使仍然占用了同一个cluster。理论上,SOC designer能针对不同的CPU power points使用多个domains,类似MTK那样使用3个cluster的设计,当然这回增加设计复杂度和成本。
有了DynamIQ,ARM就可以在使用硬件控制时简化下电流程,意思是不在使用的cores可以更快地关闭。通过memory的进步及整合coherency management到硬件中,ARM已经移除通过了对下电的方式来disable和flush memory caches的耗时步骤。
最后
DynamIQ体现了对移动端多核处理技术的一个重要的进步。对移动设备,它不仅对多核系统提供了一些潜在的性能提升,而且也使SOC developer能实现新的big.LITTLE的设计,以及多样的计算方案。
翻译自:https://www.androidauthority.com/arm-dynamiq-need-to-know-770349/