一. HBase过滤器
1、列值过滤器
2、列名前缀过滤器
3、多个列名前缀过滤器
4、行键过滤器
5、组合过滤器
package demo; import javax.swing.RowFilter; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.filter.ColumnPrefixFilter; import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp; import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.filter.FilterList.Operator; import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter; import org.apache.hadoop.hbase.filter.RegexStringComparator; import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; import org.apache.hadoop.hbase.util.Bytes; import org.junit.Test; import net.spy.memcached.ops.OperationErrorType; public class TestHBaseFilter { /** * 列值过滤器:SingleColumnValueFilter */ @Test public void testSingleColumnValueFilter() throws Exception{ //查询工资等于3000的员工 //select * from emp where sal=3000 //配置ZK的地址信息 Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端 HTable client = new HTable(conf, "emp"); //定义一个列值过滤器 SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("empinfo"),//列族 Bytes.toBytes("sal"), //工资 CompareOp.EQUAL, // = Bytes.toBytes("3000"));//ֵ //定义一个扫描器 Scan scan = new Scan(); scan.setFilter(filter); //通过过滤器查询数据 ResultScanner rs = client.getScanner(scan); for (Result result : rs) { String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"))); System.out.println(name); } client.close(); } /** * 列名前缀过滤器:ColumnPrefixFilter */ @Test public void testColumnPrefixFilter() throws Exception{ //列名前缀过滤器 //select ename from emp //配置ZK的地址信息 Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //得到HTable客户端 HTable client = new HTable(conf, "emp"); //定义一个列名前缀过滤器 ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("ename")); //定义一个扫描器 Scan scan = new Scan(); scan.setFilter(filter); //通过过滤器查询数据 ResultScanner rs = client.getScanner(scan); for (Result result : rs) { String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"))); System.out.println(name); } client.close(); } /** * 多个列名前缀过滤器:MultipleColumnPrefixFilter */ @Test public void testMultipleColumnPrefixFilter() throws Exception{ Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp"); //员工姓名 薪资 byte[][] names = {Bytes.toBytes("ename"),Bytes.toBytes("sal")}; MultipleColumnPrefixFilter filter = new MultipleColumnPrefixFilter(names); Scan scan = new Scan(); scan.setFilter(filter); ResultScanner rs = client.getScanner(scan); for (Result result : rs) { String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"))); String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"))); System.out.println(name+" "+sal); } client.close(); } /** * 行键过滤器:RowFilter */ @Test public void testRowFilter() throws Exception{ Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp"); //定义一个行键过滤器 org.apache.hadoop.hbase.filter.RowFilter filter = new org.apache.hadoop.hbase.filter.RowFilter( CompareOp.EQUAL, //= new RegexStringComparator("7839")); //定义一个扫描器 Scan scan = new Scan(); scan.setFilter(filter); //通过过滤器查询数据 ResultScanner rs = client.getScanner(scan); for (Result result : rs) { String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"))); String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"))); System.out.println(name+" "+sal); } client.close(); } /** * 组合过滤器 */ @Test public void testFilter() throws Exception{ Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); HTable client = new HTable(conf, "emp"); //工资=3000 SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"), CompareOp.EQUAL, Bytes.toBytes("3000")); //名字 ColumnPrefixFilter filter2 = new ColumnPrefixFilter(Bytes.toBytes("ename")); FilterList filterList = new FilterList(Operator.MUST_PASS_ALL); filterList.addFilter(filter1); filterList.addFilter(filter2); Scan scan = new Scan(); scan.setFilter(filterList); ResultScanner rs = client.getScanner(scan); for (Result result : rs) { String name = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("ename"))); String sal = Bytes.toString(result.getValue(Bytes.toBytes("empinfo"), Bytes.toBytes("sal"))); System.out.println(name+" "+sal); } client.close(); } }
二. HDFS上的mapreduce
建立表
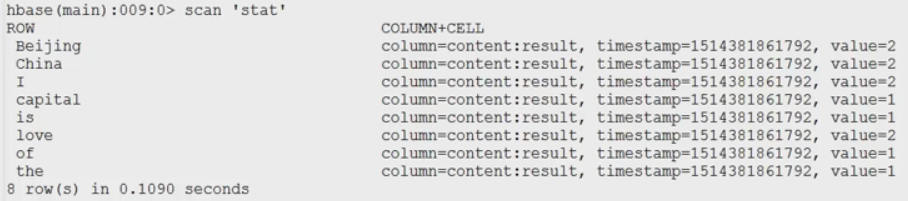
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
create 'stat','content'
注意:export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH

WordCountMapper.java
package wc; import java.io.IOException; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; //K2 V2 //没有k1和v1,因为输入的就是表中一条记录 public class WordCountMapper extends TableMapper<Text, IntWritable>{ @Override protected void map(ImmutableBytesWritable key, Result value, Context context)throws IOException, InterruptedException { //key和value代表从表中输入的一条记录 //key:行键 value:数据 String data = Bytes.toString(value.getValue(Bytes.toBytes("content"), Bytes.toBytes("info"))); //分词 String[] words = data.split(" "); for (String w : words) { context.write(new Text(w), new IntWritable(1)); } } }
WordCountReducer.java
package wc; import java.io.IOException; import org.apache.hadoop.hbase.client.Mutation; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; //k3 v3 代表输出一条记录 public class WordCountReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{ @Override protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException { // 求和 int total = 0; for (IntWritable v : v3) { total = total + v.get(); } //构造一个put对象 Put put = new Put(Bytes.toBytes(k3.toString())); put.add(Bytes.toBytes("content"),//列族 Bytes.toBytes("result"),//列 Bytes.toBytes(String.valueOf(total))); //输出 context.write(new ImmutableBytesWritable(Bytes.toBytes(k3.toString())), //把这个单词作为key,就是输出的行键 put);//表中的一条记录 } }
WordCountMain.java
package wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; public class WordCountMain { public static void main(String[] args) throws Exception { //获取ZK的地址 //指定的配置信息:Zookeeper Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "192.168.153.11"); //创建一个任务 Job job = Job.getInstance(conf); job.setJarByClass(WordCountMain.class); //定义一个扫描器读取:content:info Scan scan = new Scan(); //可以使用filter scan.addColumn(Bytes.toBytes("content"), Bytes.toBytes("info")); //使用工具类设置Mapper TableMapReduceUtil.initTableMapperJob( Bytes.toBytes("word"), //输入的表 scan, //扫描器,只读取需要处理的数据 WordCountMapper.class, Text.class, //key IntWritable.class,//value job); //使用工具类Reducer TableMapReduceUtil.initTableReducerJob("stat", WordCountReducer.class, job); job.waitForCompletion(true); } }
结果: