Java集合(八)哈希表及哈希函数的实现方式
一、哈希表
非哈希表的特点:关键字在表中的位置和它之间不存在一个确定的关系,查找的过程为给定值一次和各个关键字进行比较,查找的效率取决于和给定值进行比较的次数。
哈希表的特点:关键字在表中位置和它之间存在一种确定的关系。
哈希函数:一般情况下,需要在关键字与它在表中的存储位置之间建立一个函数关系,以f(key)作为关键字为key的记录在表中的位置,通常称这个函数f(key)为哈希函数。
哈希(hash) : 翻译为“散列”,就是把任意长度的输入,通过hash算法,变成固定长度的输出,该输出就是hash值。
这种转换是一种压缩映射,hash值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从hash值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到固定长度的消息摘要的函数。
实现哈希函数一般有6种方式:直接定址法、数字分析法、平方取中法、折叠法、除留余数法、 随机函数法。其中最常用的是除留余数法。
二、直接定址法
取关键码的某个线性函数值作为哈希地址。公式:H(k) = a × k + c (其中a,c为常数)。
优点:以关键码k的某个线性函数值为哈希地址,不会产生冲突。
缺点:会占用连续的地址空间,空间效率低。
当向字典中加入某一新元素时算法自动调用此函数,以确定该元素最终的存储位置。若某元素关键码key为1,上式中,a=2,b=3则该元素最终会存储在字典第5个位置中。
例子:关键码集合为{100,200,500,700,900},选取哈希方法为:H(k) = k / 100,则哈希表(存储结构)如下:

直接定址法的优点是实现方法简单,算法时间复杂度较小,而且不会产生冲突。但是,直接定址法要求散列地址空间的大小与关键码集合的大小一致,而这种要求是苛刻的,一般很难实现。例如当关键码的范围为1~1000000时,元素散列地址的个数也要达到1000000。这么大的散列地址是不合实际的。
特点:一般不会发生冲突,但适用面比较窄。
三、数字分析法
取关键码的中的若干位作为哈希地址。选用的原则应当是:各种符号在该位上出现的频率大致相同。
例子:有一组(例如80个)关键码,如下表:

1、位号为①、②的关键码均是“3和4”,③也是只有“7,8,9”,因此,这几位不应作为哈希地址,余下的四位,分布较均匀,可作为哈希地址选用。
2、若哈希地址取2位数,则可取④、⑤、⑥和⑦中的任意两位组成哈希地址,也可取其中两位和另外两位叠加求和后,取低的两位作为哈希地址。
特点:适用于事先明确知道表中所有关键码每一位数值的分布情况。它完全依赖于关键码集合,如果换一个关键码集合,选择哪几位作为哈喜欢地址要重新确定。
四、平方取中法
对关键码平方后,按哈希表大小,取中间若干位作为哈希地址。
例子:2589的平方值为6702921,可以取中间的029作为哈希地址。
特点:对数字分析法的改进,哈希地址与关键码的每一位都相关。
五、折叠法
将关键码分割成位数相同的几部分(最后一部分可以不同),然后取这几部分的叠加和作为哈希地址。折叠法有两种,即位移法和分界法。
(一)、位移法:采取的具体方式是把各部分的最后一位对齐相加
(二)、分界法:采用的具体方式是各部分不折断,而沿各部分的分界来回折叠,然后对齐相加,并将相加的结果当做散列地址
假设关键码key=987654321,散列地址为4位。位移法和分界法计算散列地址的算式如下图:
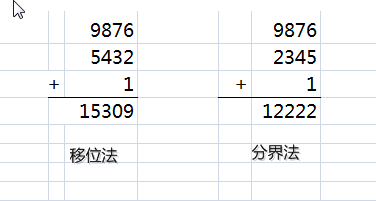
由式可见,位移法计算结果为15309,由于散列地址为4位,所以舍去最高位数字1,元素最终的散列地址为5309。分界法结算结果为12222,同样舍去最高位数字1,元素最终的散列地址为2222。
特点:适用于长关键码,当关键码位数较多时,且关键码每一位的数字上的分布较均匀时,可使用这种方法获得哈希地址。
六、除留余数法(最常用)
以关键码除以m的余数作为哈希地址,若设计的哈希表长为n,则一般取 m ≤ n 且为质数(也可为合数,但不能包含小于20的质因子)。
公式:H(k) = k mod m(m ≤ n ,m是一个整数,n是表的长度)。
为什么要对“m”加限制?
例子:给定一个关键码集合:{12,39,18,24,33,21},若取m = 9,则他们对应小标如下表:

从上表可见:若m中含质因子3,则所有含质因子3的关键码均映射到“3的倍数”的地址上,从而增加了“哈希冲突”的可能。
如何选取合适的“m”?
若哈希表表长为n,通常m为小于或等于表长(最好接近n)的最小质数或不包含小于20质因子的合数。当P取小于哈希表长的最大质数时,产生的哈希函数较好,因为它是离长度值最近的最大质数。
例如:关键码集合{12,24,36,48,60,72,84,96,108,120,132,144}
情况1:取m=12,根据公式:H(k) = k mod m,可以得到如下表:

从上表可以看出,得到的下标都为“0”,这样就造成了“哈希冲突”了。
情况2:如果m = 11,可以得到如下表:

从上表可以看出只有12和144冲突了,相比情况1,哈希冲突变少了。
特点:除留余数法有效缩减散列地址空间的大小,是最常用的方法。
七、乘余取整法
公式:H(k)=[b ×(a × k mod 1)] ,(a,b均为常数,且0 < a < 1,b为整数),(a × k mod 1)取的是 a × k 的小数部分。
特点:以关键码k乘以a,取其小数部分,然后再放大b倍再取整,作为哈希地址。
例如,当元素关键码为2020, 小数a为0.6180339,整数b为10000,则散列地址计算为H(2020)=[10000×(0.6180339×2020%1)]=4284。
特点:乘余取整法不但会缩减散列地址空间的大小,还能极大减小冲突情况的发生几率。Knuth(唐纳德·克努特,算法和程序设计的先驱)对常数a的取法做了仔细的研究,发现虽然a取任何值都可以,但一般取黄金分割数0.6180339比较好。
八、随机函数法
选择一随机函数,取关键字的随机值作为散列地址,及H(k) = random(k),(random(k)为伪随机数方法),通常用于关键码长度不同的场合。
九、总结
(一)、上述五中实现方式中最常用的是除留余数法,而通过哈希函数寻址的过程可能出现“冲突”------即若干个不同的key却对应相同的哈希地址。解决哈希冲突可查看Java集合(九)哈希冲突及解决哈希冲突的4种方式。
(二)、构造哈希函数的原则
1、执行速度,即计算哈希函数的时间;
2、关键字的长度;
3、哈希表的大小;
4、关键字的分布情况;
5、查找频率。