1). 日志格式分析
首先分析 Hadoop 的日志格式, 日志是一行一条, 日志格式可以依次描述为:日期、时间、级别、相关类和提示信息。如下所示:
2013-03-06 15:23:48,132 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting DataNode
STARTUP_MSG: host = ubuntu/127.0.0.1
STARTUP_MSG: args = []
STARTUP_MSG: version = 1.1.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1411108; compiled by 'hortonfo' on Mon Nov 19 10:48:11 UTC 2012
************************************************************/
2013-03-06 15:23:48,288 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2013-03-06 15:23:48,298 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source MetricsSystem,sub=Stats registered.
2013-03-06 15:23:48,299 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2013-03-06 15:23:48,299 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system started
2013-03-06 15:23:48,423 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source ugi registered.
2013-03-06 15:23:48,427 WARN org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Source name ugi already exists!
2013-03-06 15:23:53,094 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Registered FSDatasetStatusMBean
2013-03-06 15:23:53,102 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened data transfer server at 50010
2013-03-06 15:23:53,105 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Balancing bandwith is 1048576 bytes/s
2013-03-06 15:23:58,189 INFO org.mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
2013-03-06 15:23:58,331 INFO org.apache.hadoop.http.HttpServer: Added global filtersafety (class=org.apache.hadoop.http.HttpServer$QuotingInputFilter)
2013-03-06 15:23:58,346 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: dfs.webhdfs.enabled = false
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: Port returned by webServer.getConnectors()[0].getLocalPort() before open() is -1. Opening the listener on 50075
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: listener.getLocalPort() returned 50075 webServer.getConnectors()[0].getLocalPort() returned 50075
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: Jetty bound to port 50075
2013-03-06 15:23:58,347 INFO org.mortbay.log: jetty-6.1.26
2013-03-06 15:23:58,719 INFO org.mortbay.log: Started SelectChannelConnector@0.0.0.0:50075
2013-03-06 15:23:58,724 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source jvm registered.
2013-03-06 15:23:58,726 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source DataNode registered.
2013-03-06 15:24:03,904 INFO org.apache.hadoop.ipc.Server: Starting SocketReader
2013-03-06 15:24:03,909 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source RpcDetailedActivityForPort50020 registered.
2013-03-06 15:24:03,909 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source RpcActivityForPort50020 registered.
2013-03-06 15:24:03,910 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: dnRegistration = DatanodeRegistration(localhost.localdomain:50010, storageID=DS-2039125727-127.0.1.1-50010-1362105928671, infoPort=50075, ipcPort=50020)
2013-03-06 15:24:03,922 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Finished generating blocks being written report for 1 volumes in 0 seconds
2013-03-06 15:24:03,926 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting asynchronous block report scan
2013-03-06 15:24:03,926 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeRegistration(192.168.11.157:50010, storageID=DS-2039125727-127.0.1.1-50010-1362105928671, infoPort=50075, ipcPort=50020)In DataNode.run, data = FSDataset{dirpath='/home/hadoop/hadoop-datastore/dfs/data/current'}
2013-03-06 15:24:03,932 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 50020: starting
2013-03-06 15:24:03,932 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2013-03-06 15:24:03,934 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Finished asynchronous block report scan in 8ms
2013-03-06 15:24:03,934 INFO org.apache.hadoop.ipc.Server: IPC Server handler 0 on 50020: starting
2013-03-06 15:24:03,934 INFO org.apache.hadoop.ipc.Server: IPC Server handler 1 on 50020: starting
2013-03-06 15:24:03,950 INFO org.apache.hadoop.ipc.Server: IPC Server handler 2 on 50020: starting
2013-03-06 15:24:03,951 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: using BLOCKREPORT_INTERVAL of 3600000msec Initial delay: 0msec
2013-03-06 15:24:03,956 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Reconciled asynchronous block report against current state in 1 ms
2013-03-06 15:24:03,961 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: BlockReport of 12 blocks took 1 msec to generate and 5 msecs for RPC and NN processing
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting Periodic block scanner.
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Generated rough (lockless) block report in 0 ms
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Reconciled asynchronous block report against current state in 0 ms
2013-03-06 15:24:04,004 INFO org.apache.hadoop.util.NativeCodeLoader: Loaded the native-hadoop library
2013-03-06 15:24:04,047 INFO org.apache.hadoop.hdfs.server.datanode.DataBlockScanner: Verification succeeded for blk_3810479607061332370_1201
2013-03-06 15:24:34,274 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_8724520321365706382_1202 src: /192.168.11.157:42695 dest: /192.168.11.157:50010
2013-03-06 15:24:34,282 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42695, dest: /192.168.11.157:50010, bytes: 4, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-328627796_1, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8724520321365706382_1202, duration: 1868644
2013-03-06 15:24:34,282 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_8724520321365706382_1202 terminating
2013-03-06 15:24:36,967 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Scheduling block blk_3810479607061332370_1201 file /home/hadoop/hadoop-datastore/dfs/data/current/blk_3810479607061332370 for deletion
2013-03-06 15:24:36,969 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Deleted block blk_3810479607061332370_1201 at file /home/hadoop/hadoop-datastore/dfs/data/current/blk_3810479607061332370
2013-03-06 15:24:42,130 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-7687594967083109639_1203 src: /192.168.11.157:42698 dest: /192.168.11.157:50010
2013-03-06 15:24:42,135 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42698, dest: /192.168.11.157:50010, bytes: 3, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-7687594967083109639_1203, duration: 1823671
2013-03-06 15:24:42,135 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-7687594967083109639_1203 terminating
2013-03-06 15:24:42,159 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_8851175106166281673_1204 src: /192.168.11.157:42699 dest: /192.168.11.157:50010
2013-03-06 15:24:42,162 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42699, dest: /192.168.11.157:50010, bytes: 38, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8851175106166281673_1204, duration: 496431
2013-03-06 15:24:42,163 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_8851175106166281673_1204 terminating
2013-03-06 15:24:42,177 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42700, bytes: 42, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8851175106166281673_1204, duration: 598594
2013-03-06 15:24:42,401 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-3564732110216498100_1206 src: /192.168.11.157:42701 dest: /192.168.11.157:50010
2013-03-06 15:24:42,402 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42701, dest: /192.168.11.157:50010, bytes: 109, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-3564732110216498100_1206, duration: 465158
2013-03-06 15:24:42,404 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-3564732110216498100_1206 terminating
2013-03-06 15:24:42,593 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_2602280850343619161_1208 src: /192.168.11.157:42702 dest: /192.168.11.157:50010
2013-03-06 15:24:42,594 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42702, dest: /192.168.11.157:50010, bytes: 111, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2602280850343619161_1208, duration: 457596
2013-03-06 15:24:42,595 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_2602280850343619161_1208 terminating
2013-03-06 15:24:42,620 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-8499292753361571333_1208 src: /192.168.11.157:42703 dest: /192.168.11.157:50010
2013-03-06 15:24:42,673 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_2168216133004853837_1209 src: /192.168.11.157:42704 dest: /192.168.11.157:50010
2013-03-06 15:24:42,676 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42704, dest: /192.168.11.157:50010, bytes: 848, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 705024
2013-03-06 15:24:42,676 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_2168216133004853837_1209 terminating
2013-03-06 15:24:42,691 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42705, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 913742
2013-03-06 15:24:42,709 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42706, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 462507
2013-03-06 15:24:42,724 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42707, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 364763
2013-03-06 15:24:42,726 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42708, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 432228
2013-03-06 15:24:42,739 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42703, dest: /192.168.11.157:50010, bytes: 421, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-8499292753361571333_1208, duration: 116933097
2013-03-06 15:24:42,739 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-8499292753361571333_1208 terminating
2013-03-06 15:24:42,759 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-6232731177153285690_1209 src: /192.168.11.157:42709 dest: /192.168.11.157:50010
2013-03-06 15:24:42,764 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42709, dest: /192.168.11.157:50010, bytes: 134, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-6232731177153285690_1209, duration: 2742705
2013-03-06 15:24:42,765 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-6232731177153285690_1209 terminating
2013-03-06 15:24:42,803 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_6878738047819289992_1210 src: /192.168.11.157:42710 dest: /192.168.11.157:50010
2013-03-06 15:24:42,806 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42710, dest: /192.168.11.157:50010, bytes: 727, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_6878738047819289992_1210, duration: 1048999
2013-03-06 15:24:42,807 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_6878738047819289992_1210 terminating
2013-03-06 15:24:49,347 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42716, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 317106
2013-03-06 15:24:49,359 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42717, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 460452
2013-03-06 15:24:49,455 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42718, bytes: 516, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 264641
2013-03-06 15:24:49,456 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42719, bytes: 516, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 224282
2013-03-06 15:24:50,615 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-55581707144444311_1211 src: /192.168.11.157:42722 dest: /192.168.11.157:50010
2013-03-06 15:38:17,696 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at ubuntu/127.0.0.1
************************************************************/
/************************************************************
STARTUP_MSG: Starting DataNode
STARTUP_MSG: host = ubuntu/127.0.0.1
STARTUP_MSG: args = []
STARTUP_MSG: version = 1.1.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1411108; compiled by 'hortonfo' on Mon Nov 19 10:48:11 UTC 2012
************************************************************/
2013-03-06 15:23:48,288 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2013-03-06 15:23:48,298 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source MetricsSystem,sub=Stats registered.
2013-03-06 15:23:48,299 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2013-03-06 15:23:48,299 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system started
2013-03-06 15:23:48,423 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source ugi registered.
2013-03-06 15:23:48,427 WARN org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Source name ugi already exists!
2013-03-06 15:23:53,094 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Registered FSDatasetStatusMBean
2013-03-06 15:23:53,102 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened data transfer server at 50010
2013-03-06 15:23:53,105 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Balancing bandwith is 1048576 bytes/s
2013-03-06 15:23:58,189 INFO org.mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
2013-03-06 15:23:58,331 INFO org.apache.hadoop.http.HttpServer: Added global filtersafety (class=org.apache.hadoop.http.HttpServer$QuotingInputFilter)
2013-03-06 15:23:58,346 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: dfs.webhdfs.enabled = false
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: Port returned by webServer.getConnectors()[0].getLocalPort() before open() is -1. Opening the listener on 50075
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: listener.getLocalPort() returned 50075 webServer.getConnectors()[0].getLocalPort() returned 50075
2013-03-06 15:23:58,346 INFO org.apache.hadoop.http.HttpServer: Jetty bound to port 50075
2013-03-06 15:23:58,347 INFO org.mortbay.log: jetty-6.1.26
2013-03-06 15:23:58,719 INFO org.mortbay.log: Started SelectChannelConnector@0.0.0.0:50075
2013-03-06 15:23:58,724 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source jvm registered.
2013-03-06 15:23:58,726 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source DataNode registered.
2013-03-06 15:24:03,904 INFO org.apache.hadoop.ipc.Server: Starting SocketReader
2013-03-06 15:24:03,909 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source RpcDetailedActivityForPort50020 registered.
2013-03-06 15:24:03,909 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source RpcActivityForPort50020 registered.
2013-03-06 15:24:03,910 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: dnRegistration = DatanodeRegistration(localhost.localdomain:50010, storageID=DS-2039125727-127.0.1.1-50010-1362105928671, infoPort=50075, ipcPort=50020)
2013-03-06 15:24:03,922 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Finished generating blocks being written report for 1 volumes in 0 seconds
2013-03-06 15:24:03,926 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting asynchronous block report scan
2013-03-06 15:24:03,926 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeRegistration(192.168.11.157:50010, storageID=DS-2039125727-127.0.1.1-50010-1362105928671, infoPort=50075, ipcPort=50020)In DataNode.run, data = FSDataset{dirpath='/home/hadoop/hadoop-datastore/dfs/data/current'}
2013-03-06 15:24:03,932 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 50020: starting
2013-03-06 15:24:03,932 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2013-03-06 15:24:03,934 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Finished asynchronous block report scan in 8ms
2013-03-06 15:24:03,934 INFO org.apache.hadoop.ipc.Server: IPC Server handler 0 on 50020: starting
2013-03-06 15:24:03,934 INFO org.apache.hadoop.ipc.Server: IPC Server handler 1 on 50020: starting
2013-03-06 15:24:03,950 INFO org.apache.hadoop.ipc.Server: IPC Server handler 2 on 50020: starting
2013-03-06 15:24:03,951 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: using BLOCKREPORT_INTERVAL of 3600000msec Initial delay: 0msec
2013-03-06 15:24:03,956 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Reconciled asynchronous block report against current state in 1 ms
2013-03-06 15:24:03,961 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: BlockReport of 12 blocks took 1 msec to generate and 5 msecs for RPC and NN processing
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting Periodic block scanner.
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Generated rough (lockless) block report in 0 ms
2013-03-06 15:24:03,962 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Reconciled asynchronous block report against current state in 0 ms
2013-03-06 15:24:04,004 INFO org.apache.hadoop.util.NativeCodeLoader: Loaded the native-hadoop library
2013-03-06 15:24:04,047 INFO org.apache.hadoop.hdfs.server.datanode.DataBlockScanner: Verification succeeded for blk_3810479607061332370_1201
2013-03-06 15:24:34,274 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_8724520321365706382_1202 src: /192.168.11.157:42695 dest: /192.168.11.157:50010
2013-03-06 15:24:34,282 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42695, dest: /192.168.11.157:50010, bytes: 4, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-328627796_1, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8724520321365706382_1202, duration: 1868644
2013-03-06 15:24:34,282 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_8724520321365706382_1202 terminating
2013-03-06 15:24:36,967 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Scheduling block blk_3810479607061332370_1201 file /home/hadoop/hadoop-datastore/dfs/data/current/blk_3810479607061332370 for deletion
2013-03-06 15:24:36,969 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Deleted block blk_3810479607061332370_1201 at file /home/hadoop/hadoop-datastore/dfs/data/current/blk_3810479607061332370
2013-03-06 15:24:42,130 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-7687594967083109639_1203 src: /192.168.11.157:42698 dest: /192.168.11.157:50010
2013-03-06 15:24:42,135 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42698, dest: /192.168.11.157:50010, bytes: 3, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-7687594967083109639_1203, duration: 1823671
2013-03-06 15:24:42,135 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-7687594967083109639_1203 terminating
2013-03-06 15:24:42,159 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_8851175106166281673_1204 src: /192.168.11.157:42699 dest: /192.168.11.157:50010
2013-03-06 15:24:42,162 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42699, dest: /192.168.11.157:50010, bytes: 38, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8851175106166281673_1204, duration: 496431
2013-03-06 15:24:42,163 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_8851175106166281673_1204 terminating
2013-03-06 15:24:42,177 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42700, bytes: 42, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_8851175106166281673_1204, duration: 598594
2013-03-06 15:24:42,401 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-3564732110216498100_1206 src: /192.168.11.157:42701 dest: /192.168.11.157:50010
2013-03-06 15:24:42,402 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42701, dest: /192.168.11.157:50010, bytes: 109, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-3564732110216498100_1206, duration: 465158
2013-03-06 15:24:42,404 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-3564732110216498100_1206 terminating
2013-03-06 15:24:42,593 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_2602280850343619161_1208 src: /192.168.11.157:42702 dest: /192.168.11.157:50010
2013-03-06 15:24:42,594 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42702, dest: /192.168.11.157:50010, bytes: 111, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2602280850343619161_1208, duration: 457596
2013-03-06 15:24:42,595 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_2602280850343619161_1208 terminating
2013-03-06 15:24:42,620 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-8499292753361571333_1208 src: /192.168.11.157:42703 dest: /192.168.11.157:50010
2013-03-06 15:24:42,673 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_2168216133004853837_1209 src: /192.168.11.157:42704 dest: /192.168.11.157:50010
2013-03-06 15:24:42,676 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42704, dest: /192.168.11.157:50010, bytes: 848, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 705024
2013-03-06 15:24:42,676 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_2168216133004853837_1209 terminating
2013-03-06 15:24:42,691 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42705, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 913742
2013-03-06 15:24:42,709 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42706, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 462507
2013-03-06 15:24:42,724 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42707, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 364763
2013-03-06 15:24:42,726 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42708, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 432228
2013-03-06 15:24:42,739 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42703, dest: /192.168.11.157:50010, bytes: 421, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-8499292753361571333_1208, duration: 116933097
2013-03-06 15:24:42,739 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-8499292753361571333_1208 terminating
2013-03-06 15:24:42,759 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-6232731177153285690_1209 src: /192.168.11.157:42709 dest: /192.168.11.157:50010
2013-03-06 15:24:42,764 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42709, dest: /192.168.11.157:50010, bytes: 134, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_-6232731177153285690_1209, duration: 2742705
2013-03-06 15:24:42,765 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_-6232731177153285690_1209 terminating
2013-03-06 15:24:42,803 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_6878738047819289992_1210 src: /192.168.11.157:42710 dest: /192.168.11.157:50010
2013-03-06 15:24:42,806 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:42710, dest: /192.168.11.157:50010, bytes: 727, op: HDFS_WRITE, cliID: DFSClient_hb_m_localhost.localdomain,60000,1362554661390_792638511_9, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_6878738047819289992_1210, duration: 1048999
2013-03-06 15:24:42,807 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder 0 for block blk_6878738047819289992_1210 terminating
2013-03-06 15:24:49,347 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42716, bytes: 340, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 512, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 317106
2013-03-06 15:24:49,359 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42717, bytes: 856, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 460452
2013-03-06 15:24:49,455 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42718, bytes: 516, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 264641
2013-03-06 15:24:49,456 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.11.157:50010, dest: /192.168.11.157:42719, bytes: 516, op: HDFS_READ, cliID: DFSClient_hb_rs_localhost.localdomain,60020,1362554662758_1605864397_26, offset: 0, srvID: DS-2039125727-127.0.1.1-50010-1362105928671, blockid: blk_2168216133004853837_1209, duration: 224282
2013-03-06 15:24:50,615 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving block blk_-55581707144444311_1211 src: /192.168.11.157:42722 dest: /192.168.11.157:50010
2013-03-06 15:38:17,696 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at ubuntu/127.0.0.1
************************************************************/

表的定义如下:
create table if not exists loginfo( rdate string, time array<string>, type string, relateclass string, information1 string, information2 string, information3 string) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':';
2). 程序设计
本程序是在个人机器用 Eclipse 开发,该程序连接 Hadoop 集群,处理完的结果存储在MySQL 服务器上。下面是程序开发示例图。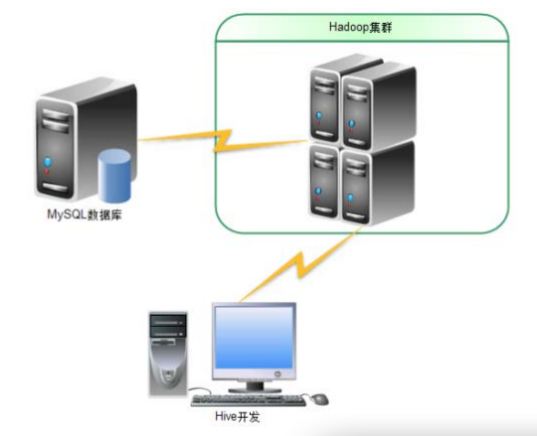
MySQL 数据库的存储信息的表“hadooplog”的 SQL 语句如下:
drop table if exists hadooplog; create table hadooplog( id int(11) not null auto_increment, rdate varchar(50) null, time varchar(50) default null, type varchar(50) default null, relateclass tinytext default null, information longtext default null, primary key (id) ) engine=innodb default charset=utf8;
操作如下:
登录mysql数据库:
hadoop@ubuntu:~$ mysql -uhive -pmysql;
创建数据库hive:
mysql> create database hive;
导入SQL语句创建表hadooplog:
mysql> use hive;
mysql> source /home/hadoop/ziliao/hadooplog.sql;
mysql> desc hadooplog;
3). 程序代码
DBHelper: 负责建立与 Hive 和 MySQL 的连接
package com.ljq.hive; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; /** * 该类的主要功能是负责建立与 Hive 和 MySQL 的连接, 由于每个连接的开销比较大, 所以此类的设计采用设计模式中的单例模式。 */ class DBHelper { private static Connection connToHive = null; private static Connection connToMySQL = null; private DBHelper() { } // 获得与 Hive 连接,如果连接已经初始化,则直接返回 public static Connection getHiveConn() throws SQLException { if (connToHive == null) { try { Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver"); } catch (ClassNotFoundException err) { err.printStackTrace(); System.exit(1); } connToHive = DriverManager.getConnection("jdbc:hive://192.168.11.157:10000/default", "hive", "mysql"); } return connToHive; } // 获得与 MySQL 连接 public static Connection getMySQLConn() throws SQLException { if (connToMySQL == null) { try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException err) { err.printStackTrace(); System.exit(1); } connToMySQL = DriverManager.getConnection("jdbc:mysql://192.168.11.157:3306/hive?useUnicode=true&characterEncoding=UTF8", "root", "mysql"); //编码不要写成UTF-8 } return connToMySQL; } public static void closeHiveConn() throws SQLException { if (connToHive != null) { connToHive.close(); } } public static void closeMySQLConn() throws SQLException { if (connToMySQL != null) { connToMySQL.close(); } } public static void main(String[] args) throws SQLException { System.out.println(getMySQLConn()); closeMySQLConn(); } }
HiveUtil:针对 Hive 的工具类
package com.ljq.hive; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; /** * * 针对 Hive 的工具类 */ class HiveUtil { // 创建表 public static void createTable(String sql) throws SQLException { Connection conn = DBHelper.getHiveConn(); Statement stmt = conn.createStatement(); ResultSet res = stmt.executeQuery(sql); } // 依据条件查询数据 public static ResultSet queryData(String sql) throws SQLException { Connection conn = DBHelper.getHiveConn(); Statement stmt = conn.createStatement(); ResultSet res = stmt.executeQuery(sql); return res; } // 加载数据 public static void loadData(String sql) throws SQLException { Connection conn = DBHelper.getHiveConn(); Statement stmt = conn.createStatement(); ResultSet res = stmt.executeQuery(sql); } // 把数据存储到 MySQL 中 public static void hiveToMySQL(ResultSet res) throws SQLException { Connection conn = DBHelper.getMySQLConn(); Statement stmt = conn.createStatement(); while (res.next()) { String rdate = res.getString(1); String time = res.getString(2); String type = res.getString(3); String relateclass = res.getString(4); String information = res.getString(5) + res.getString(6) + res.getString(7); StringBuffer sql = new StringBuffer(); sql.append("insert into hadooplog values(0,'"); sql.append(rdate + "','"); sql.append(time + "','"); sql.append(type + "','"); sql.append(relateclass + "','"); sql.append(information + "')"); int i = stmt.executeUpdate(sql.toString()); } } }
AnalyszeHadoopLog
package com.ljq.hive; import java.sql.ResultSet; import java.sql.SQLException; public class AnalyszeHadoopLog { public static void main(String[] args) throws SQLException { StringBuffer sql = new StringBuffer(); // 第一步:在 Hive 中创建表 sql.append("create table if not exists loginfo( "); sql.append("rdate string, "); sql.append("time array<string>, "); sql.append("type string, "); sql.append("relateclass string, "); sql.append("information1 string, "); sql.append("information2 string, "); sql.append("information3 string) "); sql.append("row format delimited fields terminated by ' ' "); sql.append("collection items terminated by ',' "); sql.append("map keys terminated by ':'"); System.out.println(sql); HiveUtil.createTable(sql.toString()); // 第二步:加载 Hadoop 日志文件 sql.delete(0, sql.length()); sql.append("load data local inpath "); sql.append("'/home/hadoop/ziliao/hadoop.log'"); sql.append(" overwrite into table loginfo"); System.out.println(sql); HiveUtil.loadData(sql.toString()); // 第三步:查询有用信息 sql.delete(0, sql.length()); sql.append("select rdate,time[0],type,relateclass,"); sql.append("information1,information2,information3 "); sql.append("from loginfo where type='INFO'"); System.out.println(sql); ResultSet res = HiveUtil.queryData(sql.toString()); // 第四步:查出的信息经过变换后保存到 MySQL 中 HiveUtil.hiveToMySQL(res); // 第五步:关闭 Hive 连接 DBHelper.closeHiveConn(); // 第六步:关闭 MySQL 连接 DBHelper.closeMySQLConn(); } }
4). 运行结果
程序执行完之后进入 MySQL 的控制台,查看 hadooplog 表中的结果信息如下。
hadoop@ubuntu:~$ mysql -uroot -pmysql; mysql> use hive; mysql> show tables; mysql> select * from hadooplog;
5). 经验总结
在示例中同时对 Hive 的数据仓库库和 MySQL 数据库进行操作,虽然都是使用了 JDBC接口,但是一些地方还是有差异的,这个实战示例能比较好地体现 Hive 与关系型数据库的
异同。
如果我们直接采用 MapReduce 来做,效率会比使用 Hive 高,因为 Hive 的底层就是调用了 MapReduce,但是程序的复杂度和编码量都会大大增加,特别是对于不熟悉 MapReduce
编程的开发人员,这是一个棘手问题。Hive 在这两种方案中找到了平衡,不仅处理效率较高,而且实现起来也相对简单,给传统关系型数据库编码人员带来了便利,这就是目前 Hive被许多商业组织所采用的原因。