1. Hadoop 序列化
1.1 自定义Bean对象实现序列化接口
- 必须实现 Writable 接口;
- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造;
- 重写序列化方法;
- 重写反序列化方法;
- 注意反序列化的顺序和序列化的顺序完全一致;
- 要想把结果显示在文件中,需要重写 toString(),可以" "分开,方便后续使用;
- 如果需要将自定义的Bean放在KEY中传输,则还需要实现 Comparable 接口,因为 MapReduce 框架中的 Shuffle 过程要求KEY必须能排序。
2. 切片与 MapTask 并行度决定机制
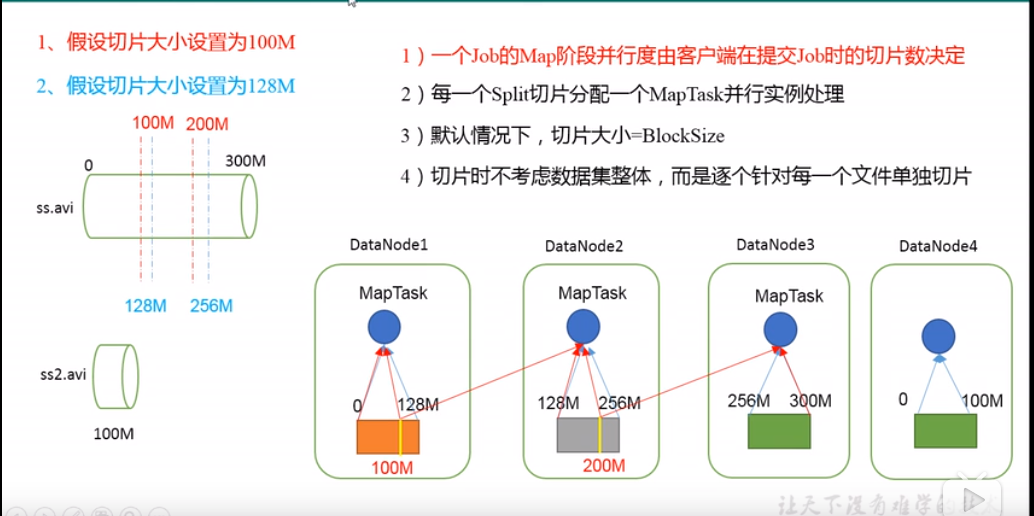
- MapTask 的并行度决定 Map 阶段的任务处理并发度,进而影响到整个 Job 的处理速度;
- MapTask 并行度决定机制
- 数据块:Block 是 HDFS 物理上把数据分成一块一块;
- 数据切片:数据切片只是逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储;
- 一个Job在Map阶段并行度由客户端在提交Job时的切片数决定;
- 每一个Split切片分配一个 MapTask 并行实例处理;
- 默认情况,切片大小=BlockSize;
=======================
3. WordCount 案例
4. FileInputFormat 实现类
- FileInputFormat 常见的接口实现类包括:
TextInputFormat,KeyValueTextInputFormat,NLineInputFormat,CombineTextInputFormat和自定义InputFormat等;
4.1 TextInputFormat
- TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable 类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text 类型。
4.2 KeyValueTextInputFormat
- 每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");来设定分隔符。默认分隔符是tab( );
// 示例 a.txt
line1 Rich learning form
line2 Intelligent learning engine
line3 Learning more convenient
line4 From the real demand for more close to the enterprise
// 切割后的效果,键值对
(line1, Rich learning form)
(line2, Intelligent learning engine)
(line3, Learning more convenient)
(line4, From the real demand for more close to the enterprise)

=======================
4.3 NLineInputFormat
- 如果使用 NLineInputFormat, 代表每个map进程处理的 InputSplit 不再按 Block 块去划分,而是按 NLineInputFormat 指定的行数 N 来划分。即输入文件的总行数/N = 切片数, 如果不整除,切片数=商+1;
4.4 自定义 InputFormat
- 步骤:
- 自定义一个类继承 FileInputFormat;
- 改写 RecordReader,实现一次读取一个完整文件封装为KV;
- 在输出时,使用 SequenceFileOutPutFormat 输出合并文件;
5.OutputFormat 数据输出
- OutputFormat是MapReduce输出的积累,所有实现MapReduce输出都实现了OutputFormat接口。
- 常见实现类:
- TextOutputFormat(文本输出)
- 默认的输出格式。它把每条记录写为文本行。它的键和值可以是任意类型。
- SequenceFileOutputFormat
- 经常作为后续MapReduce任务的输入,因为它的格式紧凑,很容易被压缩。
- 自定义OutputFormat
- 步骤:自定义一个类继承 FileOutputFormat;
- 改写RecordWriter,具体改写输出数据的方法 write();
- TextOutputFormat(文本输出)