1、HBase的能做什么
1、海量数据存储(上百亿行*上百万列)
2、准实时查询(百毫秒之内查询)
最多上百万行的数据,不建议使用Hbase。不能发挥Hbase的优势
2、HBase的应用场景和特点
交通 (如GPS数据,长江河道的船舶的GPS,城市十字路口的摄像头违章拍照)
金融:支付交易(取款信息,消费信息,贷款信息,还款信心,信用卡消费信息等)
电商: 商品买卖信息(交易信息,物流信息,日志浏览信息)
移动: 短信,通话
HBase特点
1、容量大: HBase单表可以有百亿行、百万列、数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。
一般关系型数据库单表的数量不超过500万行,如果超过500万,可以进行分库和分表操作;
列一般少于30列,如果超过30列,这个表的列的设计可能有问题。
2、面向列: HBase是面向列的存储和权限控制,并支持独立检索。
列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。
3、多版本: HBase每一个列的数据存储有多个Version
4、稀疏性: 为空的列并不占用存储空间,表可以设计的非常稀疏。
5、扩展性: 底层依赖于HDFS(存储不够的时候,动态增加机器)
6、高可靠性: WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS HDFS本身也有备份。
7、高性能:底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别。
3、HBase的列族式存储
列族式存储的概念
HBase Table的组成
Table = RowKey + Family + Column + Timestamp + Value
数据存储模式
(RowKey, Family ,Column , Timestamp ) -> Value
列数据属性
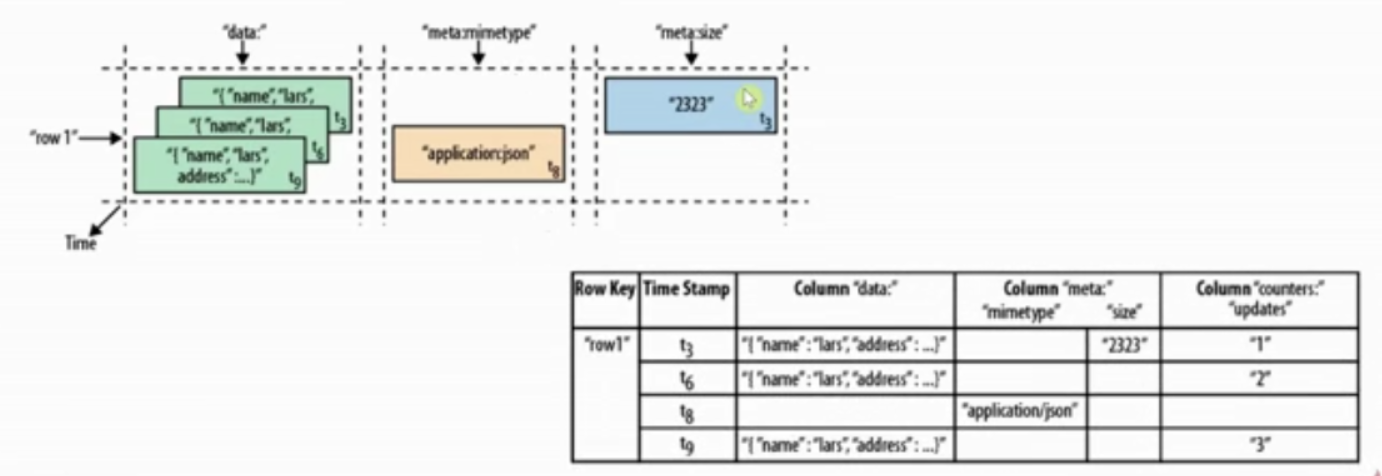
数据存储原型

4、HBase定位
HBase在整个Hadoop生态圈中作为存储功能,HBase基于HDFS。
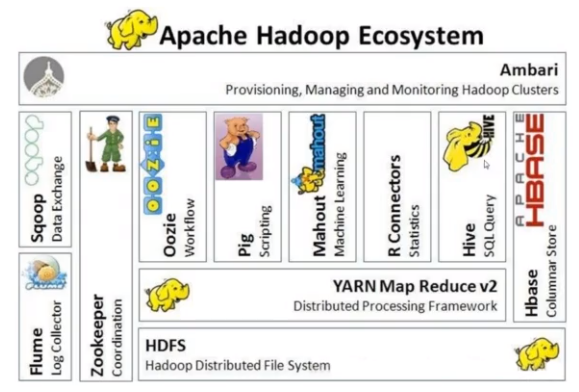
5、HBase架构体系
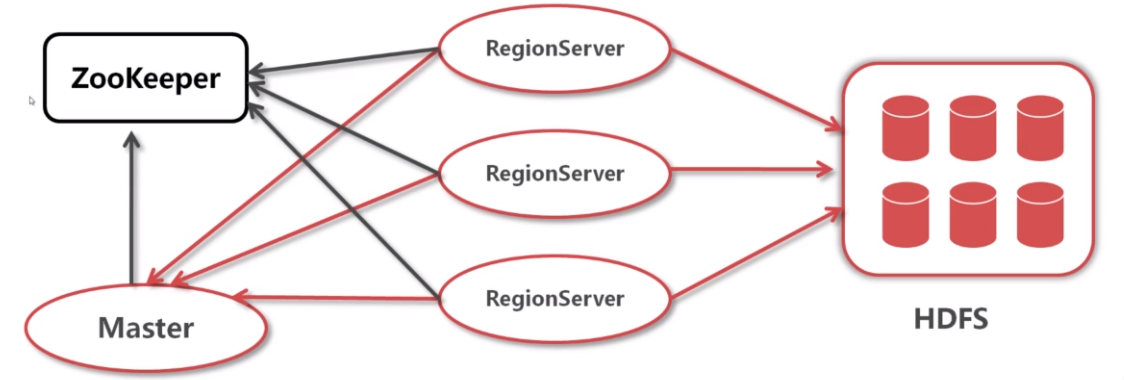
HBase 有两个进程,Region进程和Master进程,依赖于HDFS,ZooKeeper。
6、HBase设计模型
HBase表结构模型
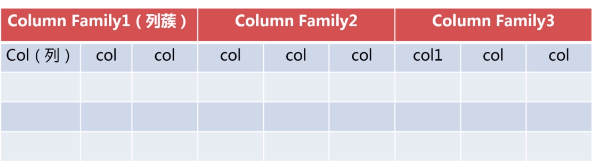
表结构举例说明
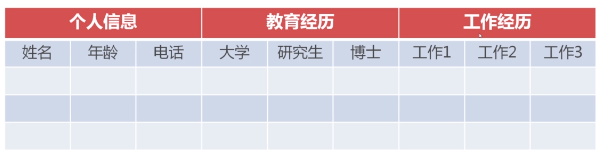
表结构举例说明
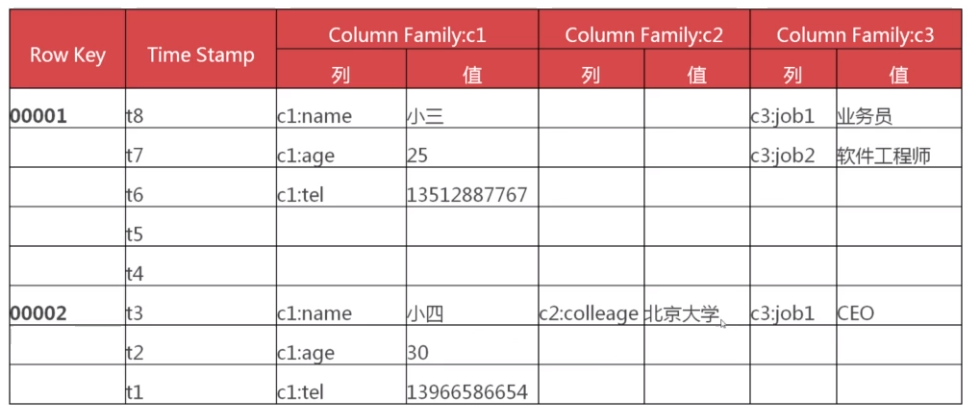
Row Key相当于主键
7、关于列族的说明

8、当数据很多时,会对数据进行分Regin,如下图

9、HBase表与关系型数据库表结构的对比
