前面介绍了数据库优化索引,这里我们介绍数据库索引调优
长字段的索引调优
使用组合索引的技巧
覆盖索引
排序优化
冗余、重复索引的优化
1、长字段的索引调优
selelct * from employees where first_name = ' Facello' 假设 first_name 的字段长度很长,如大于200个字符,那么索引占用的空间也会很大,
作用在超长字段的索引查询效率也不高。
解决方法: 额外创建个字段,比如first_name_hash int default 0 not null. first_name的hashcode
insert into employees value (999999, now(), 'zhangsan...','zhang','M',now(), CRC32('zhangsan...'));
first_name_hash的值应该具备以下要求
1) 字段的长度应该比较小,SHA1和MD5是不合适的
2) 应当尽量避免hash冲突,就目前来说,流行使用CRC32(),或者FNV64()
修改后的SQL selelct * from employees where first_name_hash = CRC32(zhangsan...) and first_name = ' Facello'
并且给 first_name_hash设置所有,并带上 first_name = ' Facello' 为了解决hash冲突也能返回正确的结果。
--长字段调优
selelct * from employees where first_name like ' Facello%'
如果是like,就不能使用上面的调优方法。
解决方法: 前缀索引
alter table employees add key (first_name(5)) 这里的5是如何确定的,能不能其它数字呢?
索引选择性 = 不重复的索引值/数据表的总记录数
数值越大,表示选择性越高,性能越好。
select count(distince first_name)/count(*) from employees; -- 返回的值为0。0043 完整列的选择性 0.0043 【这个字段的最大选择性】
select count(distinct left(first_name,5)) / count(*) from employees; -- 返回结果 0.0038 select count(distinct left(first_name,6)) / count(*) from employees; -- 返回结果 0.0041 select count(distinct left(first_name,7)) / count(*) from employees; -- 返回结果 0.0042 select count(distinct left(first_name,8)) / count(*) from employees; -- 返回结果 0.0042 select count(distinct left(first_name,9)) / count(*) from employees; -- 返回结果 0.0042 select count(distinct left(first_name,10)) / count(*) from employees; -- 返回结果 0.0042 select count(distinct left(first_name,11)) / count(*) from employees; -- 返回结果 0.0043,说明 为大于等于11时,返回 0.0043 select count(distinct left(first_name,12)) / count(*) from employees; -- 返回结果 0.0043
说明 为大于等于11时,返回 0.0043
结论: 前缀索引的长度设置为11
alter table employees add key (first_name(11))
优点: 前缀索引可以让索引更小,更加高效,而且对上层应用是透明的。应用不需要做任何改造,使用成本较低。
这是一种比较容易落地的优化方案。
局限性: 无法做order by、group by; 无法使用覆盖索引。
使用场景: 后缀索引,MySql是没有后缀索引的
额外创建一个字段,比如说first_name_reverse, 在存储的时候,把first_name的值翻转过来再存储。
比方Facello 变成 ollecaF存储到first_name_reverse
2、单例索引 vs 组合索引
explain select * from salaries where from_date = '1986-06-26' and to_date = '1987-06-26';
salaries表没有索引, explain后type为All All为全表扫描,查询时间为1s537ms
创建两个索引(单例索引)
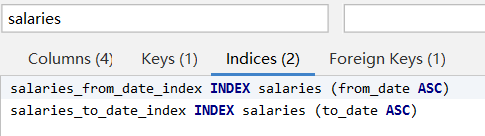
type为index_merge,
Extra为 Using intersect(salaries_to_date_index,salaries_from_date_index); Using where
查询时间为229ms
修改成组合索引index(from_date, to_date)
type : 为const 。说明组合索引比上面的单例索引性能好一些。
查询时间为215ms。 性能差异不大
总结:
SQL存在多个条件,多个单列索引,会使用索引合并
如果出现索引合并,往往说明索引不够合理。
如果SQL暂时没有性能问题,暂时可以不管。
组合索引要注意索引列顺序[最左前缀原则]
补充:

3、覆盖索引
什么是覆盖索引:对应索引X,SELECT的字段只需从索引就能获得,而无需到表数据里获取,这样的索引就叫覆盖索引。
索引index(from_date, to_date)
索引无法覆盖查询字段时
explain select * from salaries where from_date = '1986-06-26' and to_date = '1987-06-26';
type: ref
rows: 86
extra: null
索引能覆盖查询字段时
explain select from_date, to_date from salaries where from_date = '1986-06-26' and to_date = '1987-06-26';
type: ref
rows: 86
extra: using index
使用覆盖索引时,并不会改变SQL的执行过程。但是extra会显示using index
总结:
覆盖索引能提交SQL的性能
Select尽量只返回想要的字段(使用覆盖索引,减少网络传输的开销)
4、重复索引
索引是有开销的。增删改的时候,索引的维护开销。索引越多,开销越大。条件允许的情况下,尽量少创建索引。
重复索引:
在相同的列上按照相同的顺序创建的索引。
create table test_table(
id int not null primary key auto_increment,
a int not null ,
b int not null ,
unique (id),
index (id)
) ENGINE = InnoDB;
主键,唯一索引,普通索引。唯一索引在普通索引的基础上,增加了唯一性约束。主键在唯一索引的基础上增加了非空约束。相对于在Id的字段上创建了三个重复的索引。一般来说,重复索引是需要避免的。
如果发现有重复索引,也应该删掉重复索引。
上面发生了重复索引,改进方案:
create table test_table(
id int not null primary key auto_increment,
a int not null ,
b int not null
) ENGINE = InnoDB;
删除唯一索引和普通索引,值保留主键索引。
5、冗余索引(针对B-Tree和B+Tree来说的)
如果已经存在索引index(A,B), 又创建了index(A), 那么index(A) 就是index(A,B)的冗余索引。
一般要避免冗余索引。但有特例,一定要避免掉进陷阱里。
explain select * from salaries where from_date = '1986-06-26' order by emp_no;
索引index(from_date): type=ref extra=null。 使用了索引。
索引index(from_date) 某种意义上来说就相当于index(from_date, emp_no)
修改索引index(from_date,to_date)再次执行:
explain select * from salaries where from_date = '1986-06-26' order by emp_no;
索引index(from_date,to_date) type=ref extra=Using filesort 说明order by子句无法使用索引。
索引index(from_date, to_date) 某种意义上来说就相当于index(from_date, to_date, emp_no), 不符合最左前缀原则,所以order by子句无法使用索引。
6、未使用的索引
某个索引根本未曾使用
累赘,删除。