Spark是一个快速且通用的集群计算平台
1、Spark概述及特点
1) Speed: 速度。执行速度快,开发速度提高了很多。
Spark扩充了流行的MapReduce计算模型
Spark是基于内存的计算。
2) Ease of User: 易用。支持多种语言,如Python,Java,Scala等
3) Generality: 通用性,解决多个框架学习成本和运维成本
4) Run Everywhere: 运行在很多地方
2、Spark产生背景
1 ) MapReduce局限性,使用过程繁琐。
A、代码繁琐
B、只能支持map和reduce方法
C、执行效率低下
D、不适合迭代多次、交互式、流式的处理
2) 框架的多样化
A、批处理(离线): MapReduce、Hive、Pig
B、流式处理(实时): Storm,JStorm
C、交互式计算:Impala
学习、运维成本无形中都提高了很多。
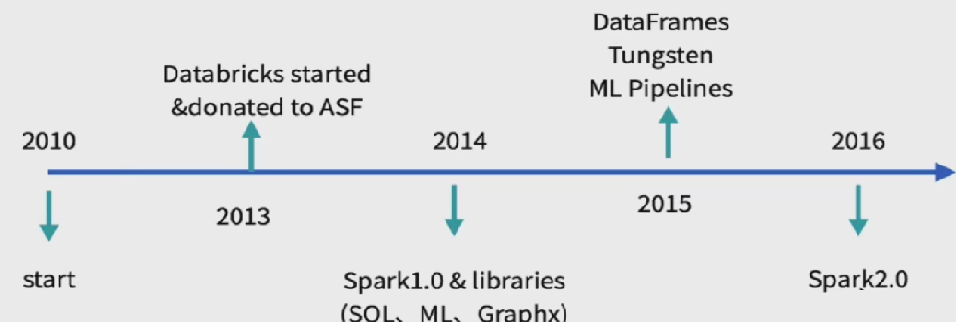
3、Spark发展历史
4、Spark生态圈

Related External Project: 灰色为外部工程。
5、Spark的组件

1) Spark Core:
包含Spark的基本功能,包含任务调度,内存管理,容错机制等
内部定义了RDDs(弹性分布式数据集)
提供了很多APIs来创建和操作这些RDDs
应用场景,为其他组件提供底层的服务
2) Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样
应用场景,企业中用来做报表统计
3) Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时流数据
应用场景,企业中用来从Kafka接收数据做实时统计
4) MLlib:
一个包含通用机器学习功能的包,Machine learning lib
包含分类,聚类,回归等,还包括模型评估和数据导入。
MLlib提供的上面这些方法,都支持集群上的横向扩展。
应用场景,机器学习。
5) Graphx:
是处理图的库(例如,社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
应用场景,图计算。
6) Cluster Managers:
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
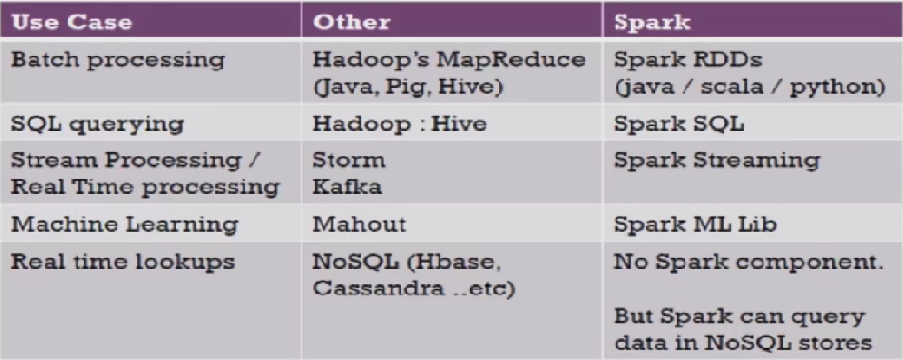
6、Hadoop生态圈对比Spark BDAS
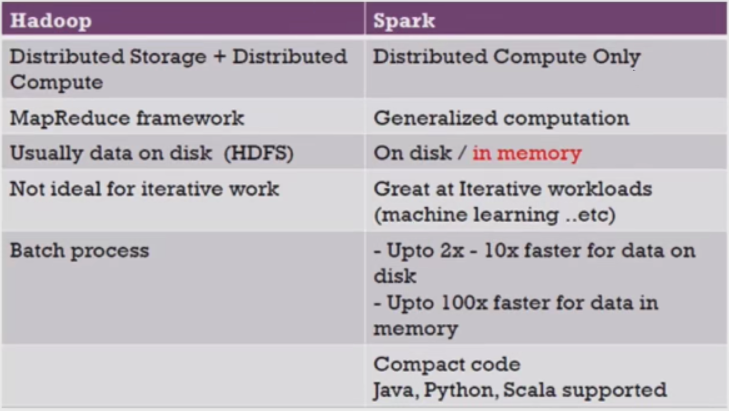
7、Hadoop与Spark对比
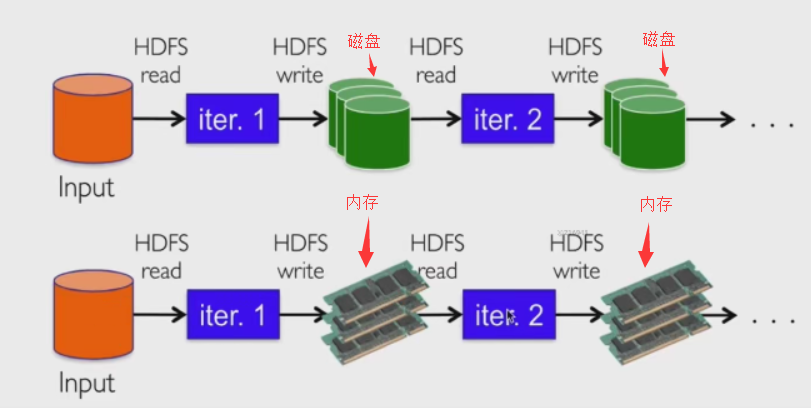
8、MapReduce与Spark对比
9、Spark和Hadoop的协作性
