1、创建表
create table hive_wordcount(context string);

2、查看表
show tables;

3、查询表数据

4、查看刚才创建的Mysql数据库sparksql的表TBLS,可以发现已经有1条记录了,TBL_NAME 为hive_wordcount

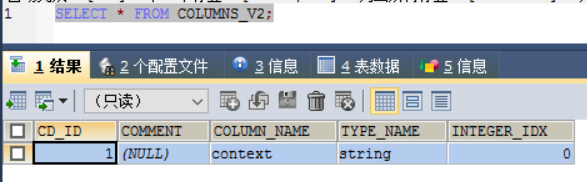
从COLUMNS_V2表查看刚才创建的hive_wordcount表的字段。
5、加载数据到Hive表里
数据准备,就是前面用到的数据。 /home/data/hello.txt文件
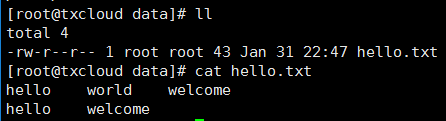
load data local inpath '/home/data/hello.txt' into table hive_wordcount;

查看数据
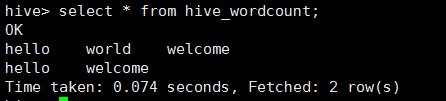
可以发现,已经有两行数据了。
6、查询统计单词个数功能
select word,count(1) from hive_wordcount lateral view explode(split(context,' ')) wc as word group by word
lateral view explode(): 该函数是把每行记录按照指定分隔符进行拆解。 split(context,' ')空格分隔。
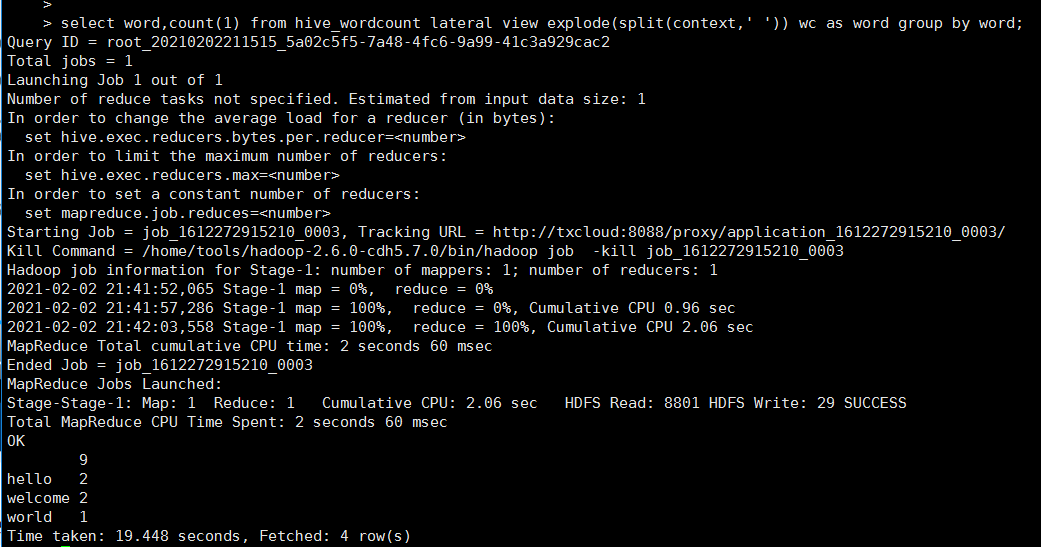
统计结果hello 2个,welcome 2个 world 1个
然后访问8088端口

总结: hive ql 提交执行后会生成mr作业,并在yarn上运行。对比MapReduce实现更简单,只需要使用HQL语句就行。